使用免费 AI API 的朋友可能都遇到过这些问题:NVIDIA NIM 访问速度慢、频繁触发限流(Rate Limit)、单一平台不稳定影响使用体验。
解决方案是 CC Switch —— 一个跨平台桌面工具,通过多模型路由 + 降级熔断机制,让你的 AI 编程工具永不掉线。
CC Switch 是什么?
CC Switch 用于统一管理多个 AI 编程命令行工具的配置,支持的工具包括:
- Claude Code:Anthropic 官方 AI 编程助手
- Claude Desktop:Claude 桌面客户端
- Codex:OpenAI Codex CLI
- Gemini CLI:Google Gemini 命令行工具
- OpenCode:开源代码助手
- OpenClaw:开源 AI 编程工具
核心能力:
- 多 Provider 管理:同时配置 NVIDIA NIM、智谱 GLM、CherryIn 等多个平台
- 优先级调度:P1 > P2 > P3 > P4 > P5,自动按优先级选择模型
- 降级熔断:当前模型限流/异常时,自动切换到下一个可用模型
- 状态监控:实时显示每个模型的健康状态(正常/限流/异常)
- 一键切换:无需手动改配置文件,界面点击即可切换
安装 CC Switch
前置要求
Node.js ≥ 18(CC Switch 管理的 CLI 工具需要 Node.js 环境)
# 检查是否已安装
node --version
npm --version安装方式
| 平台 | 安装方式 |
|---|---|
| Windows | 从 GitHub Releases 下载 .msi 安装包或便携版 |
| macOS | brew tap farion1231/ccswitch && brew install --cask cc-switch |
| Linux | 下载 .deb / .rpm / .AppImage 安装包 |
配置多个免费模型
步骤 1:添加 Provider
打开 CC Switch 主界面,点击 "Add Provider" 按钮,添加以下免费模型:
Provider 1:NVIDIA NIM(免费无限量)
- Base URL:
https://integrate.api.nvidia.com/v1 - API Key:
nvapi-你的Key(从 build.nvidia.com 获取)
Provider 2:智谱 GLM(免费无限流但限速)
- Base URL:
https://open.bigmodel.cn/api/paas/v4 - API Key:你的智谱 API Key(从 open.bigmodel.cn 获取)
- 模型:
glm-4.7-flash(免费模型)
Provider 3:CherryIn(充值 $10 后可用)
- Base URL:
https://open.cherryin.ai/v1 - API Key:你的 CherryIn API Key(从 open.cherryin.ai 获取)
Provider 4:OpenRouter(可选)
- Base URL:
https://openrouter.ai/api/v1 - API Key:
sk-or-你的Key(从 openrouter.ai 获取)
步骤 2:设置优先级
推荐配置:
- P1(最高)→ NVIDIA NIM # 能力强
- P2→ 智谱 GLM # 速度快
- P3→ NVIDIA NIM(其他模型)# 备选
- P4→ CherryIn # 兜底
- P5(最低)→ OpenRouter / 备用 # 最后备用
数字越小,优先级越高。CC Switch 会优先使用高优先级的模型,当高优先级模型限流或异常时,自动降级到下一个优先级。
配置降级熔断机制
为了实现快速失败、快速恢复,建议按以下参数配置:
| 配置项 | 推荐值 | 说明 |
|---|---|---|
| 最大重试次数 | 2 | 连续失败时的重试次数(0-10) |
| 失败阈值 | 3 | 连续失败多少次后打开熔断器 |
| 流式字节超时 | 15 秒 | 等待单个数据块的最大时间 |
| 流式静默超时 | 60 秒 | 数据块之间的最大间隔 |
| 非流式超时 | 60 秒 | 非流式请求的总超时时间 |
| 恢复等待时间 | 15 秒 | 熔断器打开后等待多久尝试恢复 |
| 错误率阈值 | 30% | 错误率达到此值时触发熔断 |
降级熔断的工作原理:用户请求 → P1 模型(限流?)→ P2 模型(正常?)→ P3 模型(正常?)→ ✅ 返回结果。简单说:一个模型挂了,自动换下一个,全程无感!
配置方式:
- 点击 "启动代理" 按钮
- 代理默认监听 127.0.0.1:15721
- 启用应用接管(Claude / Codex / Gemini)
- 所有请求经过 CC Switch 代理转发
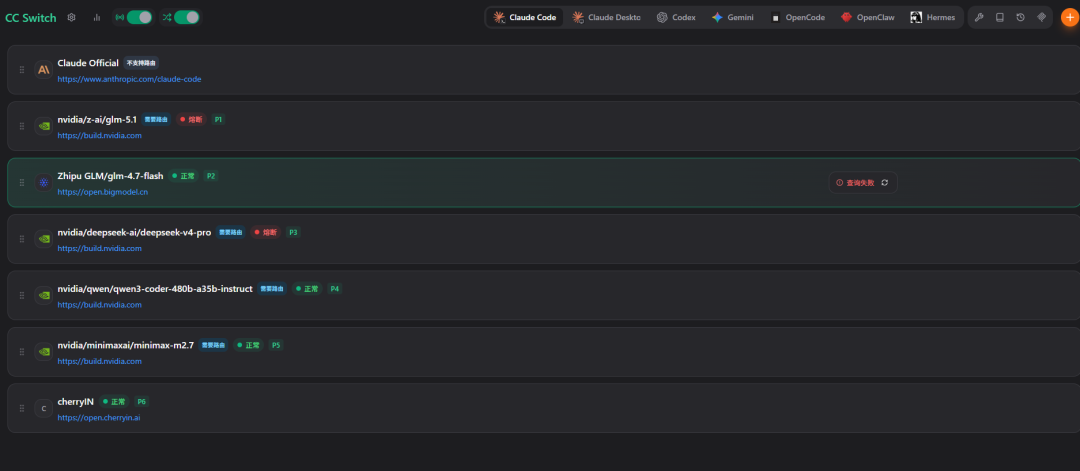
启用接管后,CC Switch 会自动监控每个模型的响应状态,检测到限流(429)或错误时自动切换到下一个可用模型,在界面实时显示模型状态(✅ 正常 / ⚠️ 限流 / ❌ 异常)。
对比总结
| 维度 | 单一平台 | CC Switch 多模型 |
|---|---|---|
| 稳定性 | ❌ 限流就挂 | ✅ 自动降级切换 |
| 速度 | ❌ 取决于单个平台 | ✅ 选最快的可用模型 |
| 成本 | 免费 | 免费 |
| 配置难度 | 简单 | 稍复杂(一次配置) |
| 推荐场景 | 轻度使用 | 重度使用 |
苏米注:CC Switch 的核心价值在于"用免费模型,享受付费级别的稳定性"。对于每天大量使用 AI 编程工具的开发者来说,频繁遇到 429 限流确实很影响效率。一次配置好优先级和熔断机制,之后基本不需要管,系统会自动选择最合适的模型。推荐所有使用免费API 的开发者都试试。
相关链接
- CC Switch 官网:ccswitch.io/zh/
- CC Switch GitHub:github.com/farion1231/cc-switch
- NVIDIA NIM:build.nvidia.com
- 智谱 GLM:open.bigmodel.cn