Anthropic 在 2026 年 6 月 9 日正式发布了两款模型:Claude Fable 5 对所有人开放,Claude Mythos 5 继续限制访问。
最引人注目的是,这两个模型底层使用完全相同的权重参数,区别仅在于安全护栏的配置。
Fable 来自拉丁语 fabula("被讲述的东西"),与希腊语 mythos(神话)同源。Anthropic 用这个命名暗示了两者同源分流的关系——Fable 是安装了安全刹车的公开版本,Mythos 则是移除了部分安全限制、仅面向特定用户的版本。

性能表现:编程能力大幅领先
Anthropic 公布了 Mythos 5 / Fable 5 与 Opus 4.8、GPT 5.5、Gemini 3.1 Pro 的对比数据,核心指标如下:
| Benchmark | Mythos 5 / Fable 5 | Opus 4.8 | GPT 5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-Bench Pro(Agentic 编程) | 80.3% | 69.2% | 58.6% | 54.2% |
| FrontierCode 钻石难度 | 29.3% | 13.4% | 5.7% | — |
| Terminal-Bench 2.1(终端编程) | 88.0% | 82.7% | 83.4%* | — |
| GDPval-AA(知识工作) | 1932 | 1890 | 1769 | 1314 |
| Humanity's Last Exam(多学科推理) | 59.0% / 64.5%** | — | — | — |
* GPT 5.5 配 Codex CLI
** 不带工具 / 带工具
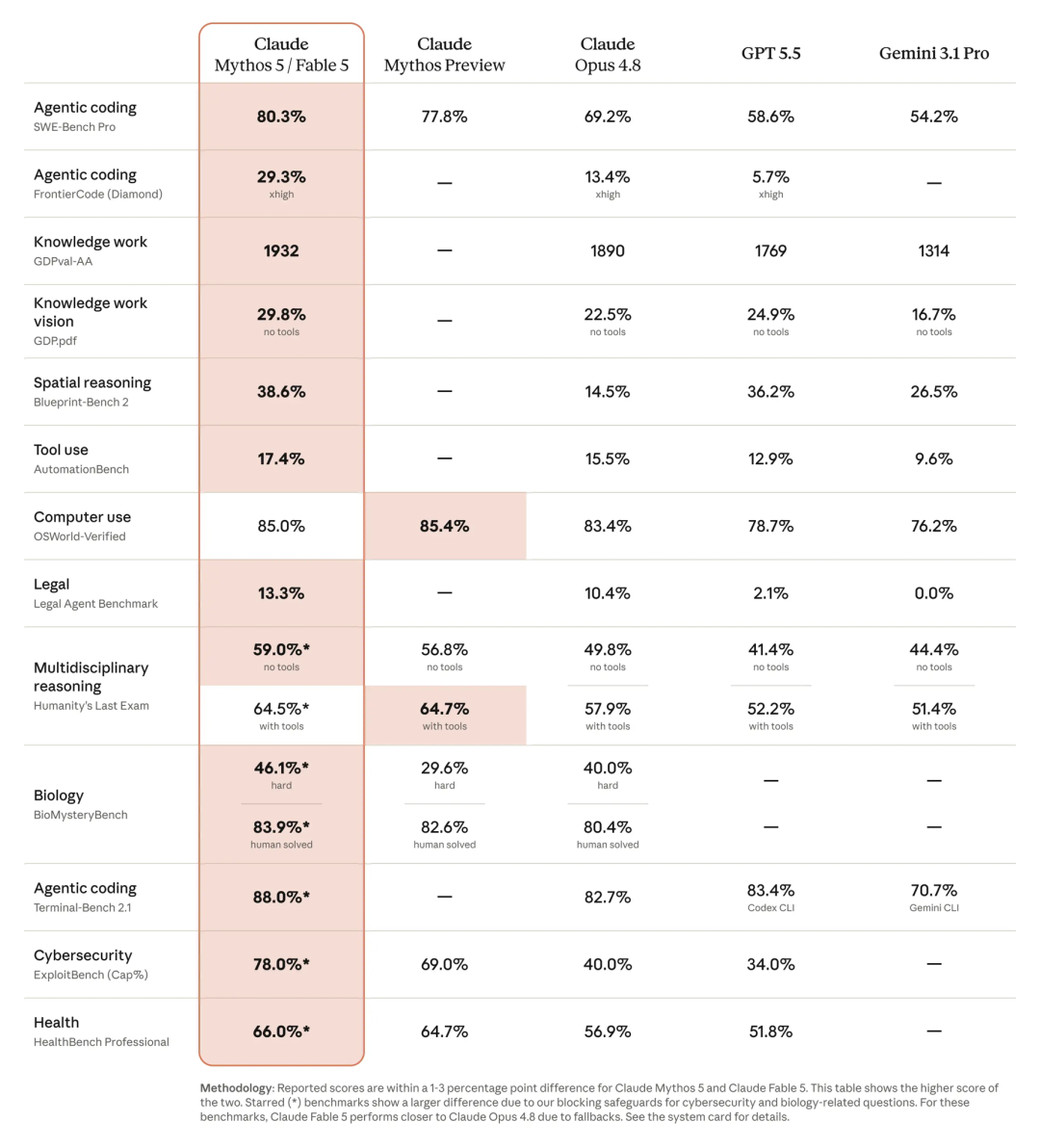
SWE-Bench Pro 上 80.3% 的成绩标志着 Agentic 编程能力的一次显著跃升。相比之下,GPT 5.5 的 58.6% 与 Fable 5 之间存在超过 20 个百分点的差距。
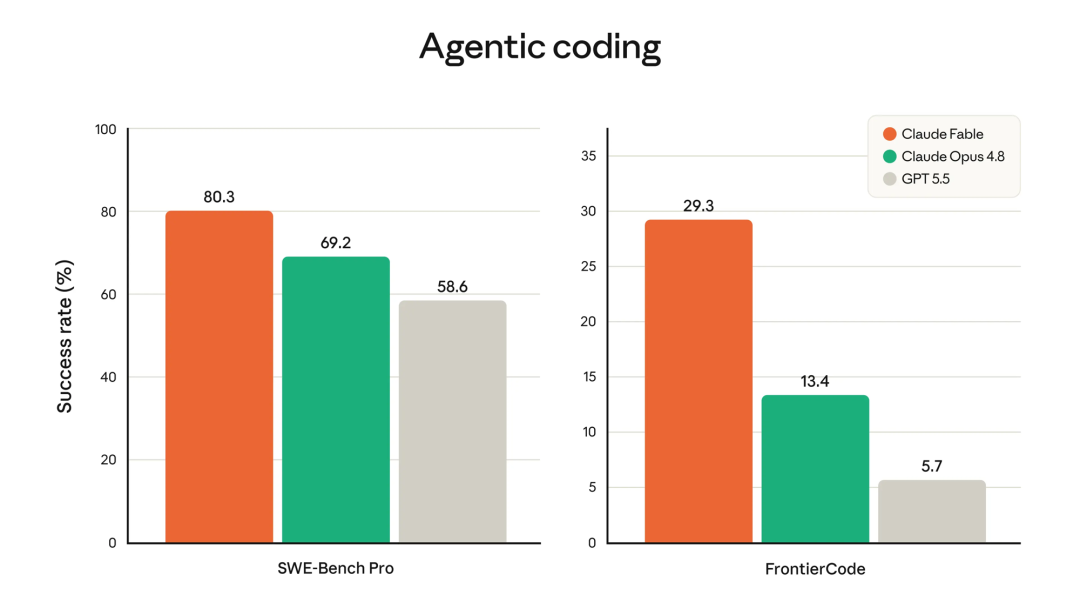
FrontierCode 的"准确率对成本"曲线揭示了一个关键差异:Fable 5 在增加算力投入后分数持续上升,从 low 到 max 几乎呈线性增长;而 Opus 4.8 在 xhigh 配置后出现平台期甚至回落,GPT 5.5 则整体表现低迷。这表明 Fable 5 在处理长链条复杂任务时具有更深的扩展空间。
安全护栏:能力与风险的平衡
Fable 5 部署了三类安全护栏,覆盖网络安全、生物化学和模型蒸馏。当用户请求涉及高风险领域(如网络攻击规划、双用途生物研究)时,模型不会直接回答,而是将会话转交给能力较低但更安全的 Opus 4.8 处理,用户会收到明确告知。
官方数据:超过 95% 的会话不会触发回退机制;不到 5% 的对话会被转走。在网络安全内部测试中,关于策划网络攻击的单轮有害请求得到有效回应数量为零。
这套机制也解释了对比表中带星号的数据点——在网络安全和生物相关题目上,Fable 5 的成绩向 Opus 4.8 靠拢,因为护栏拦截了部分回答。换言之,公开版 Fable 5 在敏感领域的能力是被刻意限制的,其完整能力存在于不公开的 Mythos 5 中。
Mythos 5 通过 Project Glasswing 项目交付给美国政府的网络防御方和关键基础设施提供方。Anthropic 计划未来通过"可信访问计划"逐步扩大访问范围,聚焦防御性网络安全和生物医学研究。
视觉能力:新的行业标杆
Fable 5 在视觉理解方面被官方定位为新的标杆。其能力包括:
- 从复杂科学图表中读取精确数值数据
- 仅通过网页截图反向生成对应网页的源代码
- 纯视觉方式通关《宝可梦 火红》——无地图、无导航提示、无游戏状态信息输入,仅凭屏幕像素识别完成全程游戏
- 生成流体模拟代码,使流体运动与自创音乐节拍同步(模型从未接触过任何音频数据)
工具集成与定价
Fable 5 已集成到 Claude Code 和 Cowork 中。Claude Code 创始人 Boris Cherny 评价该模型"在编程模型中数一数二",具体优势包括:所需提示更少、token 使用效率更高、代码质量更好、工具调用更精准、自我验证能力更强、会话持续时间更长。
定价方面,Fable 5 与 Mythos 5 保持一致:输入 $10/百万 token,输出 $50/百万 token,官方表示不到 Mythos Preview 价格的一半。Fable 5 自 6 月 9 日起对 API 用户开放,订阅套餐将分批放量。
苏米观察
这次发布的核心意义不在于跑分数字,而在于 Anthropic 首次公开承认了一个事实:模型的真实能力上限与企业愿意交付给用户的能力,是两个不同的概念。
同一套权重,装上是刹车叫 Fable,面向全球开发者;拆掉刹车叫 Mythos,仅限政府背书的少数机构。这种"同源分流"的策略反映了 AI 行业正在面临的一个深层问题——随着模型能力逼近危险边界,"什么该给、什么不该给"的判断权越来越集中到少数几家头部公司手中。
对开发者而言,SWE-Bench Pro 80.3% 的编程模型是实打实的工具升级。但 5% 的回退率、带星号的对比数据、以及被锁在玻璃柜里的 Mythos,都在提醒我们关注能力之外的治理议题。