Fable 5 被暂停那天,我第一反应是庆幸——庆幸自己没有把生产流程全押在它身上。
Fable 5 发布的时候,我认真研究了一下。它属于 Mythos-class,能力层级比 Opus 还高。Anthropic 官方的说法是:任务越长、越复杂,Fable 5 相对其他模型的领先越大。有个 Stripe 的案例很说明问题:5000 万行 Ruby 代码的迁移任务,Fable 5 一天完成,团队手工做可能超过两个月。
这种级别的模型,正常情况下会让人产生一个念头:是不是该把所有 Agent 都切过去?但"最强"这个标签有个问题:它描述的是能力上限,跟生产可靠性没关系。
单一模型依赖的生产风险
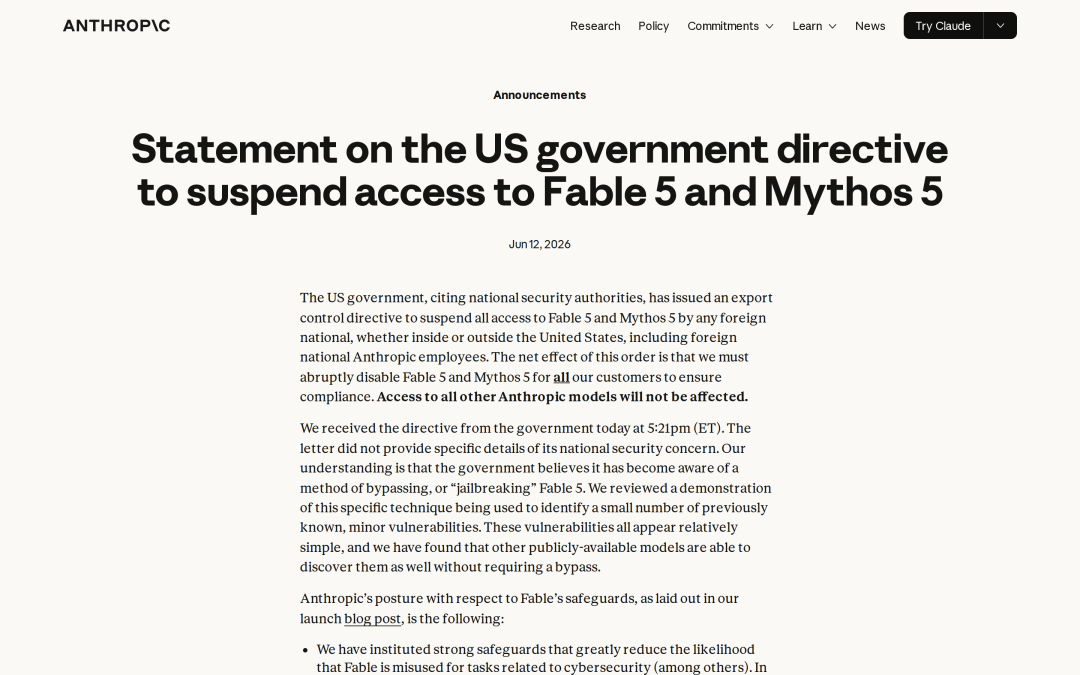
Anthropic 发布了一则公告,以国家安全权力发出出口管制指令,要求暂停所有 foreign national 对 Fable 5 和 Mythos 5 的访问。结果是必须对所有客户禁用这两个模型。
作为开发者,真正值得关注的只有一件事:一个模型可以因为合规、政策、安全或供应商策略,在任何一天突然消失。
模型能力是上限,模型可用性才是生产底线。如果你的生产流程深度依赖 Fable 5,那天你只有两个选择:临时切换(如果你有备用流程)或者等着(如果没有)。等着意味着整个工作流停摆。单点依赖的必然结果,就是一个节点挂掉,整条链路跟着停。
我的多 Agent 工作流里有明确的依赖链:设计 Agent 出配色、排版建议;前端 Agent 拿这些规范写代码;QA Agent 接住代码跑测试;运营 Agent 负责选题、文案。设计 Agent 一停,前端 Agent 没有输入可用,前端停了 QA 空转,运营也失去了可发布的产物。
按角色拆分模型,而不是追最强
Fable 5 被暂停的这段时间,我刚好在做一件相反的事:把不同 Agent 切到不同模型。
目前的分配:
- 设计 Agent、前端 Agent:换成了 Kimi K2.7
- 运营 Agent:换成了 GLM 5.2
- 其他 Agent:仍以 GPT 5.5 为主
每个 Agent 的模型需求根本不一样。设计和前端需要长上下文稳定、多模态理解可用、代码生成精准;运营处理的是平台数据分析、选题决策、文案生成,需要的是中文输出质量高、指令遵循稳定。塞给同一个模型,哪个角色都不会跑得顺。
Kimi K2.7 Code 支持 256K context window,定位是 long-context coding、工具调用、多模态分析和复杂代码生成。设计 Agent 需要读完整 UI 上下文,前端 Agent 需要长时间持有组件代码,这两个需求跟 Kimi K2.7 的定位对得上。
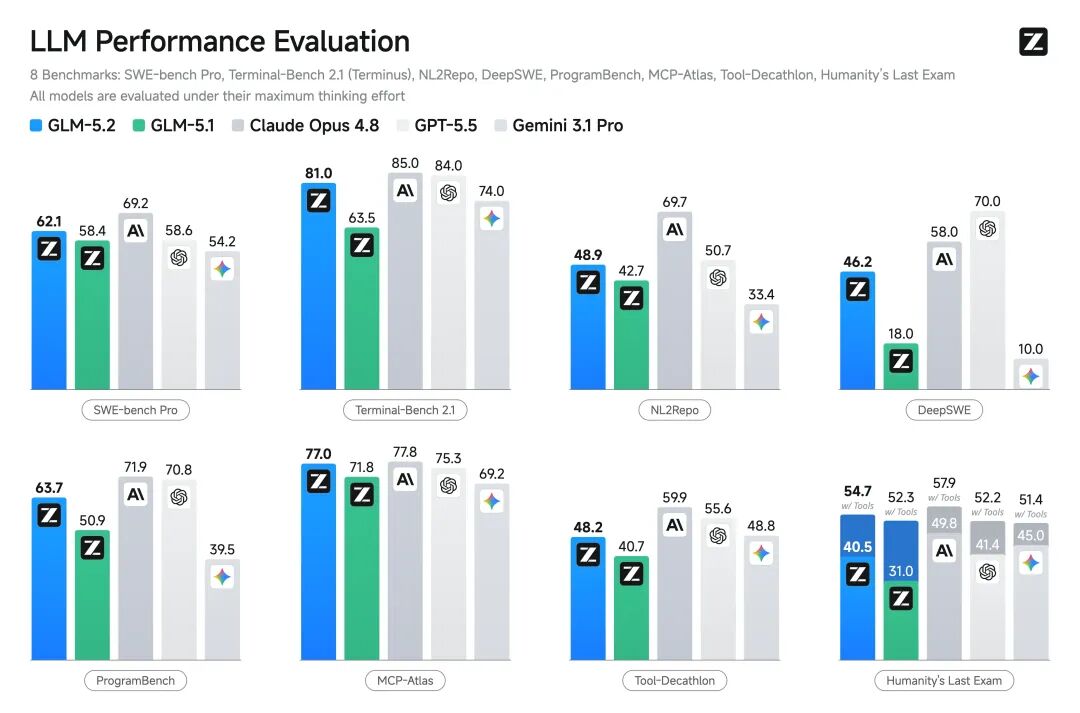
运营 Agent 选 GLM 5.2,看中的是它在长程 agentic 任务上的实测表现。GLM-5.2 是面向 long-horizon agentic coding 的旗舰模型,context window 最高 1M tokens。在 FrontierSWE、SWE-Marathon 等长程工程任务上表现突出。运营 Agent 的核心需求——多步规划稳定、长文本不跑题——和这个方向对得上。
生产级 AI 编程的选模型四维度
一、任务类型
前端、后端、运营、写作、QA、调研,每类任务对模型的需求是不同的。把所有任务塞给同一个模型,是对差异的抹平,而不是对能力的利用。
二、风险等级
低风险的高频任务,可以用新模型、便宜模型;高风险动作,必须用最稳的路径,而且要有人工确认点。
三、可替换性
- Prompt 层:按通用指令结构写,换模型时 prompt 不需要大改
- 验收标准:定义清楚什么叫"输出合格",和用哪个模型无关
- 调用日志:记录每次调用的模型、输入输出 token 数、耗时
- 回滚路径:新模型效果变差,能一行配置切回旧模型
四、供应商风险
限流、临时下架、合规、价格调整、地区访问限制——这些都是真实发生过的事。单一供应商意味着这些风险会同时命中你的所有流程。多供应商的意义,就是让这些风险变成局部影响。
以后不要问"哪个模型最强",要问"哪里必须能换"
AI 编程的生产体系,不应该围绕"最强模型"构建,而应该围绕"可替换的节点"构建。
给个人开发者的模型组合参考:
- 主力 Coding 模型:当前最适合代码生成的,用于核心开发 Agent
- 备用 Coding 模型:主力挂了能顶上,最好来自不同供应商
- 文本 / 运营模型:专门处理写作、分析、长文本
- 快速响应模型:轻量、低延迟,用于高频小任务
四个位置,四个不同来源。最差情况下任何一个出问题,其他三个还在跑。这个清单不需要每个位置都用最贵的,要的是每个位置有备份、整体不单点。
最强模型会继续出现,也会继续消失。生产流程不能跟着它一起消失。