注意:各一键包文件较大,苏米直接放在网盘下载,关注《苏米客》公众号回复“TTS一键包”即可获得;

什么是TTS
TTS(Text-To-Speech)这是一种文字转语音的语音合成。简单来说,它是一种能够将文本信息转换为自然、流畅的语音输出的技术。这种技术通过计算机或专门的设备,将文字内容转化为人们可以听懂的语音,

1、ChatTTS
ChatTTS 最强文本转语音!一键本地安装,100%成功!效果逼真如真人,完全免费开源!!
ChatTTS是专门为对话场景设计的文本转语音模型,例如LLM助手对话任务。它支持英文和中文两种语言。最大的模型使用了10万小时以上的中英文数据进行训练。在HuggingFace中开源的版本为4万小时训练且未SFT的版本。
功能亮点:中文/英语、支持多个说话者、可以预测和控制精细的韵律特征,包括笑声、停顿和插入语
一键部署:直接下载安装包解压后使用(需关闭VPN后双击运行,否则会出现闪退的情况)
使用说明:
支持四种Prompt 提示词:语速、笑声、停顿、语气词
-
[speed_0]-[speed_9]:数字越大,语速越快;
-
[laugh_0]-[laugh_9]:数字越大,笑声越多;
-
[break_0]-[break_9]:数字越大,停顿越多;
-
[oral_0]-[oral_9]:数字越大,语气词越多。
2、GPT-SoVITS
GPT-SoVITS是花儿不哭大佬研发的低成本AI音色克隆软件。目前只有TTS(文字转语音)功能,将来会更新变声功能。GPT-SoVITS的正确缩写应该是GSV。
GPT-SoVITS支持参考音频的情感、音色、语速控制合成音频的情感、音色、语速,可以少量语音微调训练,也可不训练直接推理,可以跨语种生成,即参考音频(训练集)和推理文本的语种为不同语种,支持中日英韩粤5个语种均可跨语种合成。
V3新增特点:
-
音色相似度更像,需要更少训练集来逼近本人(甚至不需要训练SoVITS)
-
GPT合成更稳定,重复漏字更少,也更容易跑出丰富情感
一键部署:Windows用户下载我给你的一键包后点击go-webui.bat,直接启动;
使用说明:
-
如果你想克隆一个人的声音,你可以找到一段这个人的演讲录音
-
如果是视频,可以使用人声分离功能,先分离出音频
开源地址:https://github.com/RVC-Boss/GPT-SoVITS
在线试用:https://gsv.acgnai.top/(各种游戏600多个角色)
使用指南:https://www.yuque.com/baicaigongchang1145haoyuangong/ib3g1e
3、F5-TTS
F5-TTS 是由上海交通大学、剑桥大学和吉利汽车研究院(宁波)有限公司于2024年共同开源的一款高性能文本到语音 (TTS) 系统,它基于流匹配的非自回归生成方法,结合了扩散变换器 (DiT) 技术。这一系统能够在没有额外监督的情况下,通过零样本学习快速生成自然、流畅且忠实于原文的语音。

F5-TTS 支持多语言合成,包括中文和英文,且能在长文本上进行有效的语音合成。系统在 10 万小时的大规模数据集上进行训练,展现出了卓越的性能和泛化能力。主要功能包括零样本声音克隆、速度控制、情感表现控制、长文本合成以及多语言支持。它的技术原理涉及到流匹配、扩散变换器 (DiT) 、 ConvNeXt V2 文本表示改进、 Sway Sampling 策略以及端到端的系统设计。
功能亮点:
快速训练和推理: 相比于其他模型,F5-TTS的训练和推理速度更快。
流畅逼真的语音: 采用流匹配技术,生成更流畅、更自然、更忠实的语音。
基于扩散Transformer和ConvNeXt V2: 利用先进的架构,提升模型性能。
多风格/多说话人生成: 支持多风格和多说话人的语音生成。
提供Gradio应用: 提供友好的图形用户界面,方便用户进行推理和微调。
支持语音聊天: 通过集成Qwen2.5-3B-Instruct模型,支持语音聊天功能。
支持三种形式:
-
TTS:标准的单音色语音克隆;
-
Podcast:多音色克隆:有声读物制作者的福音;
-
Multi-Style:多种说话情绪,例如 Shouting...
开源地址:https://github.com/SWivid/F5-TTS
在线体验:https://www.modelscope.cn/studios/modelscope/E2-F5-TTS(魔塔)
4、Spark-TTS
Spark-TTS是一种先进的文本对语音系统,它使用大语言模型(LLM)的力量来高度准确且自然的语音综合。它旨在为研究和生产使用而有效,灵活和强大。
Spark-TTS完全基于QWEN2.5,完全基于QWEN2.5,消除了对流程匹配等其他生成模型的需求。它没有依靠单独的模型来生成声学特征,而是直接从LLM预测的代码中重建音频。这种方法简化了该过程,提高了效率并降低了复杂性。

功能亮点:
-
零样本语音克隆:实测 3 秒音频就足够;
-
双语支持:支持汉语和英语,并且能够以零拍的语音克隆来克隆跨语义和代码转换场景。
-
可控的语音生成:结合 Qwen-2.5,自动调整语气、停顿、强调等语音表达。
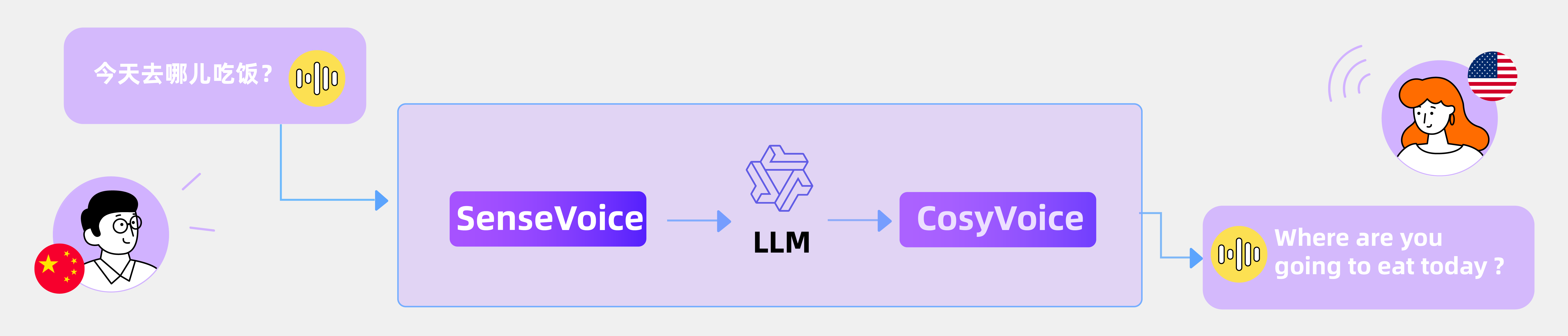
5、CosyVoice
阿里开源的 CosyVoice,与已有 TTS 方案相比,CosyVoice 在多语言语音生成、零样本语音生成、跨语言语音生成、富文本和自然语言细粒度控制方面,表现出色。
CosyVoice 的亮点总结:
-
只需3到10秒的音频样本,便能够复刻出音色,包括语调和情感等细节;
-
支持富文本和自然语言输入实现对情感和韵律的精细控制,使得合成语音充满感情色彩;
-
可以实现跨语种的语音合成。
官方共提供了三个版本的模型:
-
基座模型 CosyVoice-300M,支持 3s 声音克隆;
-
经过SFT微调的模型 CosyVoice-300M-SFT,内置了多个训好的音色;
-
支持细粒度控制的模型 CosyVoice-300M-Instruct,支持支持富文本和自然语言输入。
开源地址:https://github.com/FunAudioLLM/CosyVoice
体验地址:https://www.modelscope.cn/studios/iic/CosyVoice-300M(魔塔)
其实CosyVoice还有一个搭档,那就是阿里开源的SenseVoice,专注语音识别、情感识别和音频事件检测,满足更多人机交互的应用场景,比如语音翻译、语音对话、互动播客、有声读物等,有兴趣的也可以了解一下。
总结
苏米本文的整理主要还是针对TTS声音克隆开源项目的大致介绍,以便小白用户对开源TTS项目与在线克隆平台有一定的对比和了解,毕竟开源项目的部署是需要一定的程序开发和部署的基础,对比中可以发现,目前TTS开源项目的支持的功能更全面,对于实际的应用场景会支持的更好,像ChatTTS的提示词设置、GPT-SoVITS的情感、音色,还有音频分离、F5-TTS的多风格/多说话人生成,Spark-TTS的更可控的语音生成,阿里开源的 SenseVoice + CosyVoice 互动式的对话场景等,都能够应用到更具体的场景中。
一键包整理至网盘了,注意各一键包文件较大,关注《苏米客》公众号回复“TTS一键包”即可获得;