不需要先成为语音算法工程师。准备一段自己的录音,再找一个能够操作终端和浏览器的 AI Agent,你就可以把 GPT-SoVITS 安装、训练和封装成日常可调用的工具。
最近我完整体验了一次 GPT-SoVITS:从下载安装到第一次语音合成,再到用十几分钟录音训练自己的声音模型,最后让 Codex 把它封装成了一个可以重复调用的 Skill。整个过程最让我意外的,不只是"生成的声音像我",而是过去需要阅读大量文档、反复复制命令的工作,现在可以交给 AI Agent 执行。人主要负责录音、校对文字、试听效果和做关键选择。
本文不会展开复杂的模型参数,而是介绍 GPT-SoVITS 能做什么,以及如何有效地让 AI Agent 带你完成整个流程。
GPT-SoVITS 是什么?
GPT-SoVITS 是一个开源的少样本语音生成项目。你给它一段参考音频和文字,它就能使用类似的音色朗读新的内容。
它主要有三种实用方式:
- 零样本尝鲜:提供大约 5 秒参考音频,直接体验相似音色的文字转语音。
- 少样本训练:使用自己的录音训练模型,提高声音相似度和稳定性。
- 程序调用:通过 API 或 Skill,把自己的声音接入文章朗读、视频旁白和自动化流程。
项目还提供了一套 WebUI,把语音切分、语音识别、文字校对、数据集处理、训练和推理串在一起。
它是如何工作的?
可以把 GPT-SoVITS 理解成两位配合工作的"配音助手":
- GPT 部分理解文字内容、发音和节奏,决定"应该怎么说"。
- SoVITS 部分学习声音的音色和声学特征,决定"听起来像谁"。
推理时,再加入一段 3 到 10 秒的参考音频,帮助模型确定这一次说话的情绪和语气。
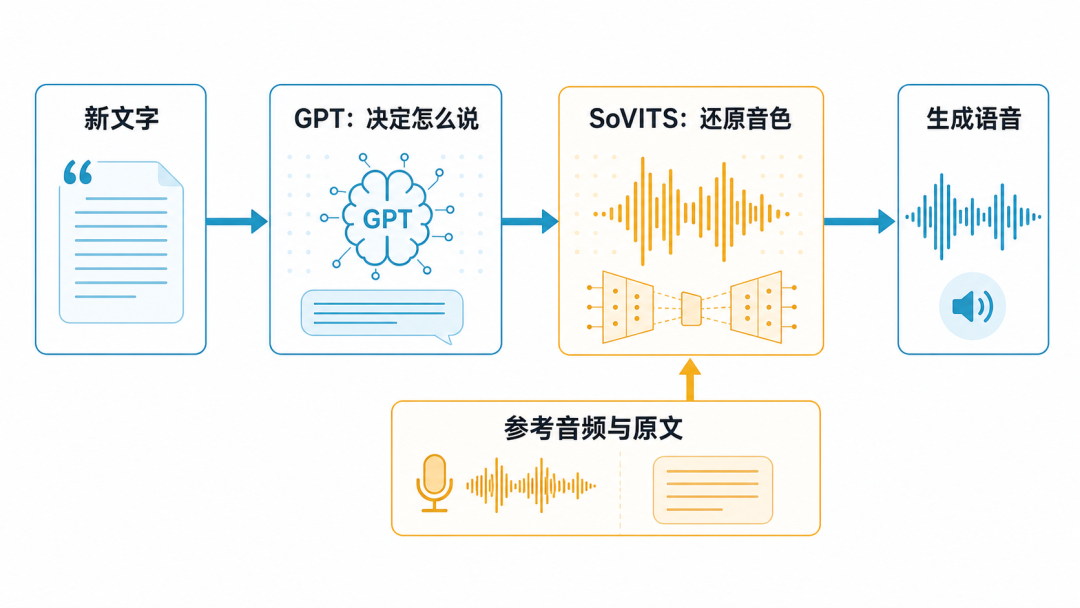
这不是简单地播放或拼接录音。模型会根据新文字重新生成语音,因此可以朗读录音里从未出现过的句子。
为什么要让 AI Agent 帮忙?
GPT-SoVITS 已经提供了 WebUI,但首次使用仍然会遇到环境安装、模型下载、文件路径、启动命令和训练参数等问题。AI Agent 的价值不是替你听声音,而是接管这些可以验证、但容易出错的操作。
正确的协作方式,不是一次性对 AI 说"帮我训练声音"然后等待结果,而是明确要求它一步一步执行,每个关键节点停下来让我确认。
第一阶段:让 Agent 安装并启动项目
可以这样对 AI Agent 说:
在当前文件夹安装 GPT-SoVITS。检查我的电脑环境,使用适合当前设备的安装方式。安装完成后,把启动方式写到本地文档,然后启动项目并告诉我访问地址。
这句话包含四个重要要求:
- 在当前目录操作,避免项目安装到未知位置。
- 先检查设备环境,不要照搬某个平台的命令。
- 把启动方式写入本地文档,方便下次使用。
- 实际启动并验证页面,而不是只告诉你"理论上可以启动"。
第一次打开主页面后,可以先让 Agent 带你做零样本尝鲜:
页面已经打开了。请告诉我需要上传什么音频,并一步一步带我完成第一次语音生成。
这一步只需要一段清晰、没有背景音乐、长度约 5 秒的人声,以及完全对应的参考文字。
第二阶段:训练自己的声音模型
如果零样本效果不错,但你希望音色更像自己,就可以开始少样本训练。我使用的是一段大约 12 分钟的单人录音。Agent 将它自动切成 150 段短音频,并通过语音识别生成初始文字。人工校对后,最终保留了 142 条有效数据。

录音应该注意什么?
- 尽量只有一个人说话。
- 避免背景音乐、混响和明显噪声。
- 正常语速说话,不要刻意播音。
- 内容尽量丰富,覆盖不同句式。
- 宁可使用 10 分钟清晰录音,也不要使用一小时嘈杂录音。
把录音放好后,可以对 Agent 说:
录音已经放到项目里了。请检查音频格式、时长和音量,然后按照 GPT-SoVITS 的推荐方式切分,并告诉我切分结果。一次只进行一个阶段。
接着让它完成语音识别,并打开校对页面:
请对切分后的音频执行中文语音识别,然后启动标注校对页面。告诉我应该重点检查什么,等我校对完成后再继续。
为什么人工校对很重要?
模型会同时学习声音和文字之间的对应关系。如果文字写错了,即使录音很好,模型也会学到错误发音。校对时重点检查:
- 漏字、错字和重复字。
- 英文缩写、数字和专有名词。
- 音频开头或结尾是否截断。
- 是否混入了其他人的声音。
- 是否存在明显噪声或过长静音。
校对完成后,只需要告诉 Agent:
标注校对完成。请检查有效数据数量,继续完成数据集处理,然后分别训练 GPT 和 SoVITS。训练过程中持续检查日志,完成后加载最终模型。
Agent 会处理数据集格式、模型路径和训练命令,并在训练完成后启动推理页面。
第三阶段:试听并调整清晰度
训练完成并不代表第一次合成就是最佳效果。参考音频、文本长度和推理参数都会影响结果。
我的第一次长文合成有些吐字不清。让 Agent 调整后,主要做了三件事:
- 把长文章拆成短段落。
- 降低生成随机性,让发音更稳定。
- 根据需要稍微放慢语速。
可以直接这样描述问题:
生成结果吐字有点不清。先不要重新训练,请调整推理参数做一段短文本对比测试,并解释修改了什么。
一组适合作为起点的参数是:
Speech rate: 1
top_k: 5
top_p: 1
temperature: 0.7
Pause Duration: 0.3不需要一开始就研究每个参数。先用短句测试,再根据实际听感告诉 Agent:"更清晰了""声音不像""语速太快"或"情绪太平",比盲目调整数值更有效。
第四阶段:把自己的声音封装成 Skill
每次都打开页面、上传参考音频和填写参数,会逐渐变得麻烦。GPT-SoVITS 提供 API,因此可以让 Agent 把固定模型、参考音频和默认参数封装成一个 Skill。

可以对 Agent 这样说:
根据当前项目的 API,生成一个"我的语音生成"Skill。固定使用已经训练好的模型和参考音频,默认使用当前清晰度参数,但允许单独覆盖语速、top-k、top-p、temperature 和停顿时长。实际调用接口验证后,再把 Skill 链接到 Codex 能识别的位置。
完成后,使用方式就变成:
使用 $generate-my-voice,把这段文章生成为我的声音。
Agent 会自动检查 API、启动服务、调用模型并返回音频文件路径。至此,训练模型不再只是一次演示,而是变成了可以接入其他工作流的个人能力。
一套有效的 AI Agent 协作方法
回顾整个过程,真正有效的提示词通常包含以下信息:
1. 明确执行边界
不要只说"教我安装",而要说:"在当前目录安装,完成后实际启动并验证页面。"
2. 要求一步一步进行
训练流程较长,适合这样说:"一次只进行一个阶段,每个需要我操作的节点停下来告诉我。"
3. 要求留下可复用成果
- 把启动方式写到本地文档。
- 把最终调用方式封装成 Skill。
- 使用绝对路径或自动定位项目,确保能从其他目录调用。
4. 用听感描述问题
不用先学习所有参数,直接告诉 Agent:"吐字不清""声音像,但语气太平""长文章后半段不稳定"。请先做对比测试,不要立即重新训练。
5. 要求验证,而不是只生成命令
最关键的一句话是:"请实际执行并验证结果,出现错误时检查日志继续处理。"这样,AI Agent 才会从"回答问题的聊天机器人",变成真正帮助你完成工作的执行者。
最后的建议
GPT-SoVITS 的门槛已经比过去低很多,而 AI Agent 又进一步降低了安装和训练成本。如果只是好奇,可以从 5 秒参考音频开始;如果准备长期使用,就录制一段清晰的人声训练自己的模型;如果希望接入内容生产,再把模型封装成 API 或 Skill。
但也要记住:声音克隆能力应当只用于你拥有授权的声音。公开发布生成内容时,最好明确标注这是 AI 合成语音,避免给他人造成误解。
当开源模型负责能力,AI Agent 负责操作,而你负责判断和创意时,训练一个属于自己的语音工具,已经不再是一件遥远的事。