作为一名产品经理,我最近在尝试如何用更低的成本和门槛来部署一个功能完整的AI Agent系统。
春节期间看到Qwen3.5发布和OpenClaw引起的热议,我决定深入体验这个方向。
经过几周的测试,我发现了一个更值得推荐的方案:用香港大学开源的Nanobot框架 + Qwen3.5本地大模型的组合,能以相对较低的学习成本和资源占用,快速搭建一个功能完善的AI助手。
这篇文章会详细记录我的实施过程。
为什么选择Nanobot而不是OpenClaw
在决策之前,我对主流方案进行了对比:
| 维度 | OpenClaw | Nanobot |
|---|---|---|
| 配置复杂度 | 高(需要较多专业知识) | 低(开箱即用) |
| Token消耗 | 较高 | 可控 |
| 资源占用 | 较大 | 轻量 |
| 功能完备性 | 完备 | 完备 |
| 生态成熟度 | 较新 | 26k Star(Github) |
| 适合用户 | 技术背景强的用户 | 技术和非技术用户均可 |
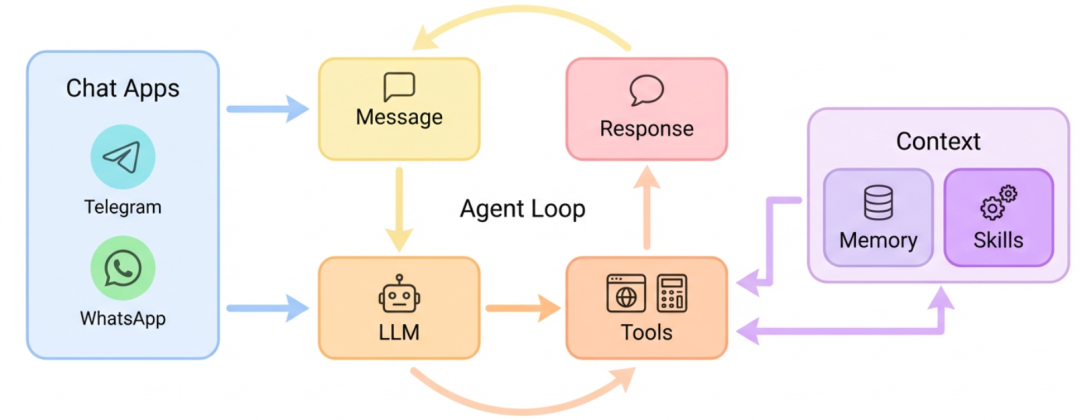
考虑到我们公司现有的8卡4090算力资源闲置,用Nanobot这套方案既能充分利用现有资源,又降低了运维复杂度,这是我最终选择它的原因。
第一步:部署Qwen3.5大模型
安装Ollama并下载模型
Ollama是我们用来管理和部署大模型的工具。Qwen3.5:122b是本次选用的模型版本,具体参数如下:
- 模型名称:qwen3.5:122b
- 模型大小:81GB
- 上下文长度:256K
- 支持能力:文本、图像
执行以下命令启动模型:
ollama run qwen3.5:122b启动后,可通过以下命令查看当前加载的模型状态:
ollama ps你会看到类似的输出信息:
NAME ID SIZE PROCESSOR CONTEXT UNTIL
qwen3.5:122b 8b9d11d807c5 103 GB 100% GPU 262144 17 minutes from now关键参数说明:
- SIZE:模型占用的显存大小
- PROCESSOR:处理器类型。100% GPU表示模型完全加载进GPU显存;其他可能值包括50%/50% CPU/GPU混合或100% CPU
- UNTIL:模型卸载时间。默认情况下,模型空闲5分钟后会从内存卸载。可通过环境变量或CLI参数修改此行为
第二步:安装和配置Nanobot
2.1 一键安装Nanobot
使用以下命令进行安装:
uv tool install nanobot-ai安装完成后,所有配置文件存储在~/.nanobot/config.json中。我的工作目录设置在用户主目录下。
2.2 配置Telegram连接通道
Telegram是Nanobot官方最推荐的交互通道。配置步骤非常简洁:
第1步:在Telegram中创建Bot
- 搜索@BotFather,发送/newbot命令
- 按提示填写Bot名称和用户名
- 获取Bot Token(格式如:123456:ABC-DEF1234ghIkl-zyx57W2v1u123ew11)
第2步:获取你的Telegram User ID
- 搜索@userinfobot,点击/start
- 记录返回的ID号
第3步:在config.json中配置
"telegram": {
"enabled": true,
"token": "YOUR_BOT_TOKEN",
"allowFrom": ["YOUR_USER_ID"],
"proxy": null
}将YOUR_BOT_TOKEN替换为第1步获取的Bot Token,将YOUR_USER_ID替换为第2步的ID号。
2.3 配置本地Qwen3.5模型
在config.json中添加以下配置,使Nanobot能调用本地运行的Qwen3.5:
"vllm": {
"apiKey": "local",
"apiBase": "http://localhost:11434/v1",
"extraHeaders": null
}说明:本地Qwen3.5默认在11434端口提供兼容OpenAI的API服务。
然后在agents配置段指定使用的模型和参数:
"agents": {
"defaults": {
"workspace": "~/.nanobot/workspace",
"model": "qwen3.5:122b",
"maxTokens": 8192,
"temperature": 0.7,
"maxToolIterations": 20,
"memoryWindow": 50
}
}参数含义:
- workspace:工作目录位置
- model:指定使用的模型
- maxTokens:单次生成的最大Token数
- temperature:生成的随机性(0-1,越低越确定性)
- maxToolIterations:Tool调用的最大迭代次数
- memoryWindow:对话记忆窗口大小
2.4 后台启动Nanobot
Nanobot官方提供的gateway命令会在前台运行,不适合生产环境。
使用以下命令在后台运行:
nohup nanobot gateway > nanobot.log 2>&1 &命令说明:
- nohup:使进程忽略挂断信号,即使终端关闭也继续运行
- > nanobot.log:标准输出重定向到日志文件
- 2>&1:标准错误也重定向到日志文件
- &:后台执行
注意:Nanobot的CLI参数优先级高于config配置文件。默认监听端口为18790。
第三步:扩展网络访问能力
3.1 识别功能缺陷
Nanobot默认缺少网络搜索能力。当用户询问"今天A股大盘指数是多少?"这类需要实时数据的问题时,它无法给出准确答案。
3.2 利用Skill机制扩展能力
Nanobot通过Skill(技能)机制允许Agent动态获取新的能力。系统已内置的Skill包括:
clawhub/ # 用于从Clawhub安装新Skill的技能
cron/ # 定时任务管理
github/ # GitHub集成
memory-rw/ # 记忆读写
skill-creator/ # Skill创建工具
summarize/ # 文本总结
tmux/ # 终端复用
weather/ # 天气查询(无需API Key)3.3 安装Tavily Web Search Skill
第1步:获取Tavily API Key
- 访问Tavily官网
- 注册账户并登录
- 在"API Keys"或"Generate MCP Link"选项中生成API Key
第2步:让Nanobot自动配置
在Telegram与Bot对话,发送以下消息:
让nanobot把tavily的apikey配置进去:YOUR_TAVILY_API_KEYNanobot会自动解析你的请求,并将API Key写入config.json的相应位置。
3.4 为什么选择Tavily而非Brave Search
- Brave Search的缺点:需要翻墙访问;获取免费额度的API Key需要信用卡,这对很多用户形成了门槛
- Tavily的优势:国内可直接访问;提供更便利的免费层级
从产品易用性角度,Tavily是更好的选择。
验证配置成功
配置完成后,你可以在Telegram中与Bot进行对话,测试以下功能:
- 基础对话能力
- 网络搜索能力(询问实时信息)
- Markdown格式输出(让它生成结构化内容)
当Bot能够正确回答基于实时信息的问题,并返回格式正确的内容时,说明整个系统配置成功。
总结:为什么这套方案值得关注
作为一个产品经理,我在选择技术方案时关注三个维度:
- 易实施性:配置步骤清晰,不需要深度的工程背景
- 资源效率:充分利用现有算力,避免额外投资
- 扩展性:通过Skill机制灵活扩展功能,不需要修改核心代码
Nanobot + Qwen3.5这套组合在这三个方面都表现得相当均衡。
特别是对于想快速验证AI Agent想法、但又不想陷入复杂配置的团队,这是一个务实的起点。
nanobot: https://github.com/HKUDS/nanobot
qwen3.5:122b: https://ollama.com/library/qwen3.5:122b
https://docs.ollama.com/faq#how-do-i-keep-a-model-loaded-in-memory-or-make-it-unload-immediately: https://link.juejin.cn?target=https%3A%2F%2Fdocs.ollama.com%2Ffaq%23how-do-i-keep-a-model-loaded-in-memory-or-make-it-unload-immediately
nanobot github文档: https://github.com/HKUDS/nanobot
tavily: https://www.tavily.com/