英伟达在 CES 2026 发布了下一代 AI 计算平台 Rubin,Rubin 平台彻底刷新了我对“AI基础设施”的认知。它不再只是单颗GPU的升级,而是一整套从CPU、GPU到网络、存储、互联的极端协同设计(Extreme Codesign),目标只有一个:
让训练和推理大模型的成本与功耗真正进入可规模化的新阶段。
六款芯片齐发:把整个机架当作一台电脑来设计

英伟达这次一口气发布了六款全新芯片,共同构成 Rubin AI 计算平台:
- Vera CPU:自研 CPU,88 个定制 Olympus 核心
- Rubin GPU:下一代 GPU,集成 3360 亿晶体管
- NVLink 6 Switch:实现机架内 GPU 互联,每 GPU 带宽达 3.6TB/s
- ConnectX-9 SuperNIC:800Gb/s 高速网卡
- BlueField-4 DPU:专责安全、存储与基础设施卸载
- Spectrum-6 Ethernet Switch:机架间互联,单芯片带宽 102.4Tb/s
黄仁勋在发布会上直言:“Rubin 来得正是时候,AI 计算需求正在爆炸。” 这句话背后,是真实世界中模型规模与成本之间的尖锐矛盾。
性能提升:不只是“更快”,而是“更省”
与上一代 Blackwell 平台相比,Rubin 的提升堪称革命性:
- 推理 token 成本降至十分之一
- 训练相同 MoE 模型所需 GPU 数量减少至四分之一
- 网络功耗效率提升 5 倍
具体来看:训练一个 10 万亿参数的 MoE 模型,Blackwell 需要 64,000 张 GPU,而 Rubin 仅需 16,000 张
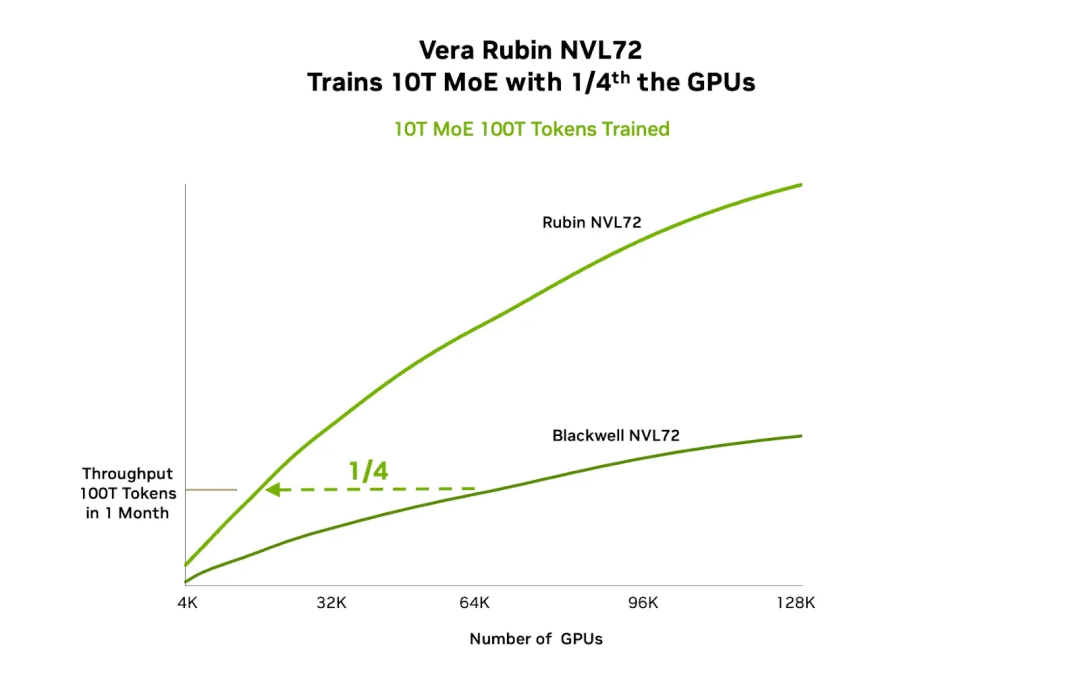
这不仅是硬件数量的节省,更是数据中心空间、电力、运维复杂度的全面优化。
Vera CPU:为“喂数据给 GPU”而生
英伟达此前使用 Grace CPU,如今全面转向 Vera CPU——名字致敬发现暗物质证据的天文学家 Vera Rubin。
核心规格:
- 88 个定制 Olympus 核心,176 线程
- 1.5TB LPDDR5X 内存,带宽 1.2TB/s
- 2270 亿晶体管
- 支持 Arm v9.2 架构

与 Grace 对比,Vera 实现了全方位跃升:
表格
| 规格 | Grace | Vera |
|---|---|---|
| 核心数 | 72 Neoverse V2 | 88 Olympus |
| 线程数 | 72 | 176 |
| L3 缓存 | 114MB | 162MB |
| 内存带宽 | 512GB/s | 1.2TB/s |
| 内存容量 | 480GB | 1.5TB |
| NVLink-C2C | 900GB/s | 1.8TB/s |
英伟达明确表示:Vera 的核心任务就是高效“喂数据”给 GPU,确保计算单元永不“饥饿”。
Rubin GPU:3360 亿晶体管的推理怪兽
单颗 Rubin GPU 规格如下:
- 3360 亿晶体管(Blackwell 为 2080 亿)
- 288GB HBM4 显存
- 显存带宽 22TB/s(Blackwell 为 8TB/s)
- NVFP4 推理算力 50 PFLOPS
- 224 个 SM,第六代 Tensor Core
- 第三代 Transformer Engine,支持硬件级自适应压缩,专为 FP4 精度优化
- NVLink 带宽翻倍至 3.6TB/s

与 Blackwell 对比如下:
表格
| 规格 | Blackwell | Rubin |
|---|---|---|
| 晶体管 | 2080 亿 | 3360 亿 |
| NVFP4 推理 | 10 PFLOPS | 50 PFLOPS |
| FP8 训练 | 5 PFLOPS | 17.5 PFLOPS |
| HBM 带宽 | 8 TB/s | 22 TB/s |
| NVLink 带宽 | 1.8 TB/s | 3.6 TB/s |
Vera Rubin NVL72:一整机架即一台超级计算机
Rubin 平台的旗舰配置 Vera Rubin NVL72 将 72 张 GPU、36 颗 Vera CPU、NVLink 6、ConnectX-9 和 BlueField-4 全部集成在一个机架内:
- NVFP4 推理算力:3.6 EFLOPS
- HBM4 总量:20.7TB
- 系统内存:54TB
- 机架内互联带宽:260TB/s(英伟达称“超过整个互联网”)
采用 全液冷设计,使用 45°C 温水直接冷却,冷却流量比 Blackwell 提升近一倍;同时实现 无线缆设计,组装速度提升 18 倍。

NVLink 6:72 GPU 全互联,延迟一致
第六代 NVLink 是 Rubin 平台的通信中枢:
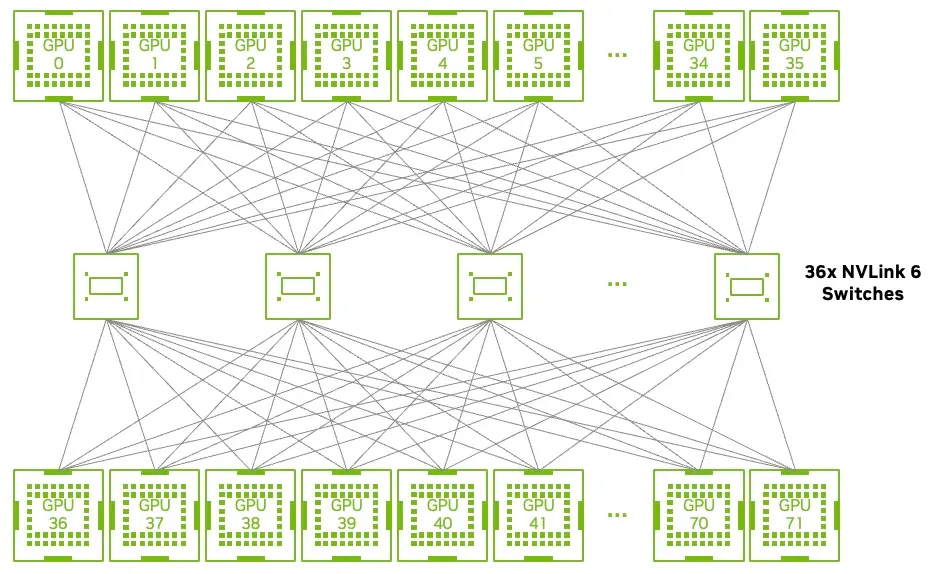
- 每 GPU 带宽 3.6TB/s(翻倍)
- 全互联拓扑,任意两张 GPU 间通信延迟一致
- 内置 SHARP 网络计算单元,提供 14.4 TFLOPS FP8 算力
- 每个 Switch Tray 带宽 28.8TB/s
- MoE 模型的 all-to-all 通信吞吐提升 2 倍
- 支持热插拔、部分填充运行、动态流量重路由

BlueField-4 DPU:基础设施的“隐形引擎”
BlueField-4 不再只是辅助芯片,而是承担起网络、存储、安全等关键任务:
- 集成 64 核 Grace CPU + ConnectX-9 网卡
- 与 BlueField-3 对比:
表格
| 规格 | BlueField-3 | BlueField-4 |
|---|---|---|
| 带宽 | 400 Gb/s | 800 Gb/s |
| CPU 核心 | 16 A78 | 64 Neoverse V2 |
| 内存带宽 | 75 GB/s | 250 GB/s |
| 内存容量 | 32GB | 128GB |
| 存储 IOPS | 10M | 20M |
新增 ASTRA(Advanced Secure Trusted Resource Architecture),提供硬件级隔离,适用于裸金属与多租户环境。
还引入 “推理上下文内存存储平台”,专门缓存 KV Cache,使长上下文推理吞吐与能效均提升 5 倍。
还引入 “推理上下文内存存储平台”,专门缓存 KV Cache,使长上下文推理吞吐与能效均提升 5 倍。

ConnectX-9 SuperNIC 与 Spectrum-6:构建超低延迟网络底座
ConnectX-9:单端口 800Gb/s,支持 200G PAM4 SerDes、可编程拥塞控制、硬件加密(IPsec/PSP)

与 Spectrum-6 配合,在端点即可完成流量整形,避免网络拥塞

Spectrum-6 以太网交换机:
- 单芯片带宽 102.4Tb/s(翻倍)
- 采用 共封装光学(Co-packaged Optics) 技术:
- 功耗效率提升 5 倍
- 信号损耗从 22dB 降至 4dB,信号完整性提升 64 倍
- 可靠性提升 10 倍
此外,Spectrum-XGS 支持跨地域组网,数百公里外的数据中心可视为同一集群。

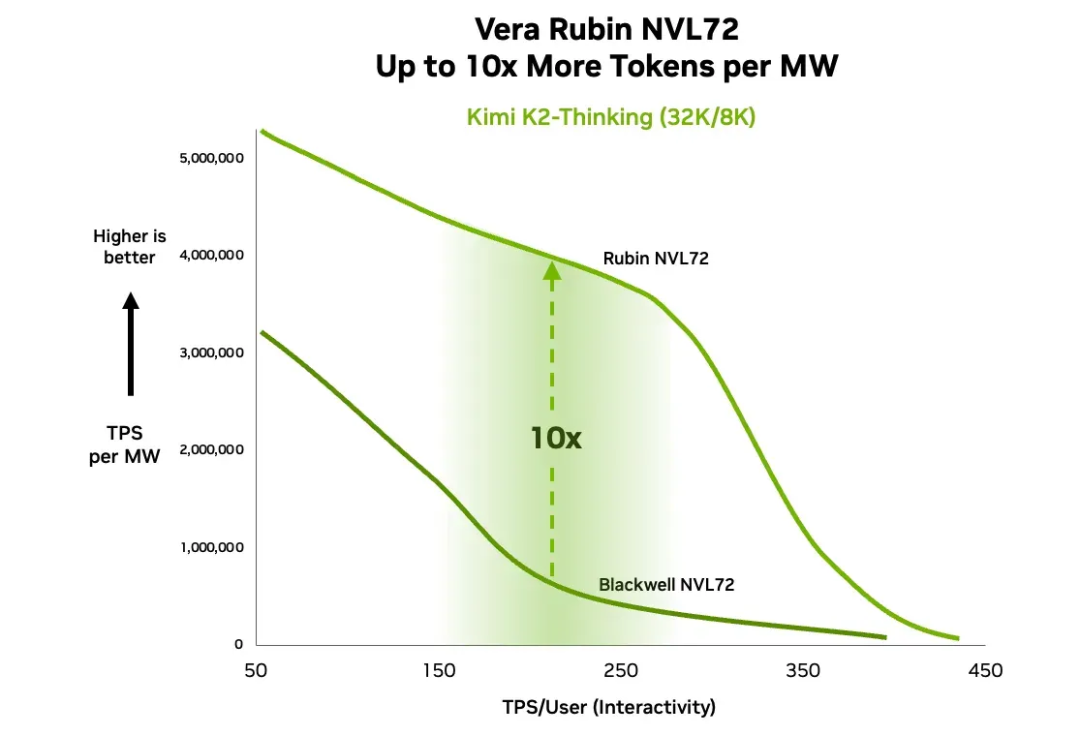
推理实测:成本与能效的“十倍法则”
英伟达使用 Kimi-K2-Thinking(1T MoE 模型,32K 输入 + 8K 输出)进行测试:
同等交互性下,每瓦吞吐提升 10 倍
同等延迟下,每百万 token 成本降至十分之一
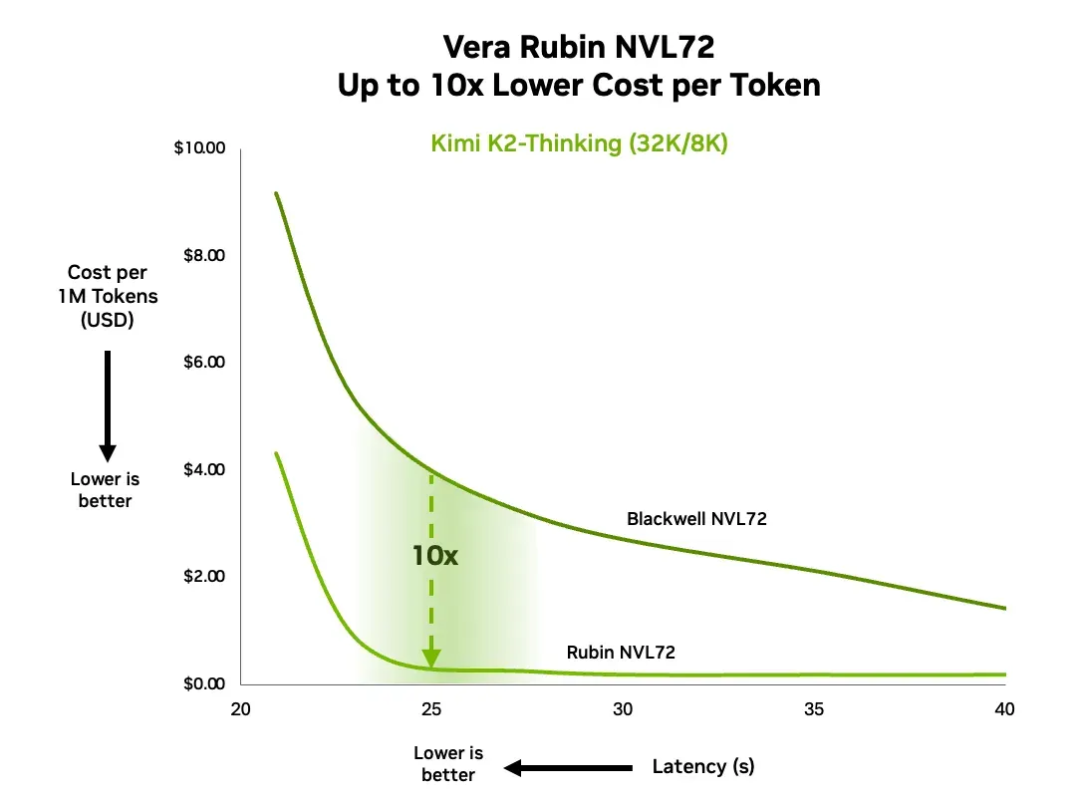
这验证了 Rubin 不仅是“更强”,更是“更可持续”。
谁在用?生态已全面就位
云厂商:
AWS、Google Cloud、Microsoft Azure、Oracle Cloud、CoreWeave、Lambda、Nebius、Nscale
AI 公司:
OpenAI、Anthropic、Meta、xAI、Mistral、Cohere、Perplexity、Black Forest Labs、Runway、Cursor、Harvey
硬件厂商:
Dell、HPE、Lenovo、Supermicro、Cisco
微软将在下一代 Fairwater AI 超算中心部署 Vera Rubin NVL72,规模达 数十万张 GPU。
CoreWeave 也确认 2026 下半年上线 Rubin 实例。
CoreWeave 也确认 2026 下半年上线 Rubin 实例。
行业领袖怎么说?
- Sam Altman(OpenAI):“Intelligence scales with compute. Rubin 让我们能继续 scale.”
- Dario Amodei(Anthropic):“Rubin 的效率提升能让模型有更长的记忆、更好的推理、更可靠的输出。”
- Mark Zuckerberg(Meta):“Rubin 的性能和效率提升是把最先进模型部署给几十亿用户的前提。”
- Elon Musk(xAI):“💚🎉🚀🤖 Rubin 是 AI 的火箭引擎”
- Satya Nadella(Microsoft):“我们在建世界上最强的 AI 超算,Vera Rubin 加进来,开发者能以全新方式创造、推理、扩展。”
何时可用?
- Rubin 已进入量产阶段
- 2026 下半年开始出货
- AWS、Google Cloud、Microsoft、Oracle 将首批部署

总结
作为长期追踪 AI 基础设施的产品人,Rubin 平台让我看到一个清晰趋势:AI 算力的竞争已从“单点突破”进入“系统级协同”时代。英伟达不再只卖 GPU,而是提供一套从芯片到机架、从计算到网络的完整“AI工厂”解决方案。
对上层应用而言,这意味着:更低成本的推理、更可行的超大规模训练、更高效的长上下文处理——这些都将直接转化为产品体验的跃升。无论是做 Agent、RAG,还是多模态生成,底层算力的“十倍效率提升”终将释放出新一轮的产品创新浪潮。
Rubin 不只是一代芯片,它是一张通往下一阶段 AI 产品的通行证。而我们,正站在入口处。
声明:本站原创文章文字版权归本站所有,转载务必注明作者和出处;本站转载文章仅仅代表原作者观点,不代表本站立场,图文版权归原作者所有。如有侵权,请联系我们删除。