昨天,豆包大模型 2.0(Doubao-Seed-2.0,简称 Seed2.0)全线发布。
此次更新覆盖三款通用 Agent 模型(Pro、Lite、Mini)以及一款编程增强模型(Code),围绕复杂 Agent 使用与大规模生产部署进行了系统级优化。
核心看点速览
多模态与推理:在涉及数学与视觉推理的 19 项基准中,12 项拿下第一;视觉感知、文档理解、长上下文等多数基准达到 SOTA;EgoTempo 分数超越人类(人类 63.2,Seed2.0 Pro 71.8)。
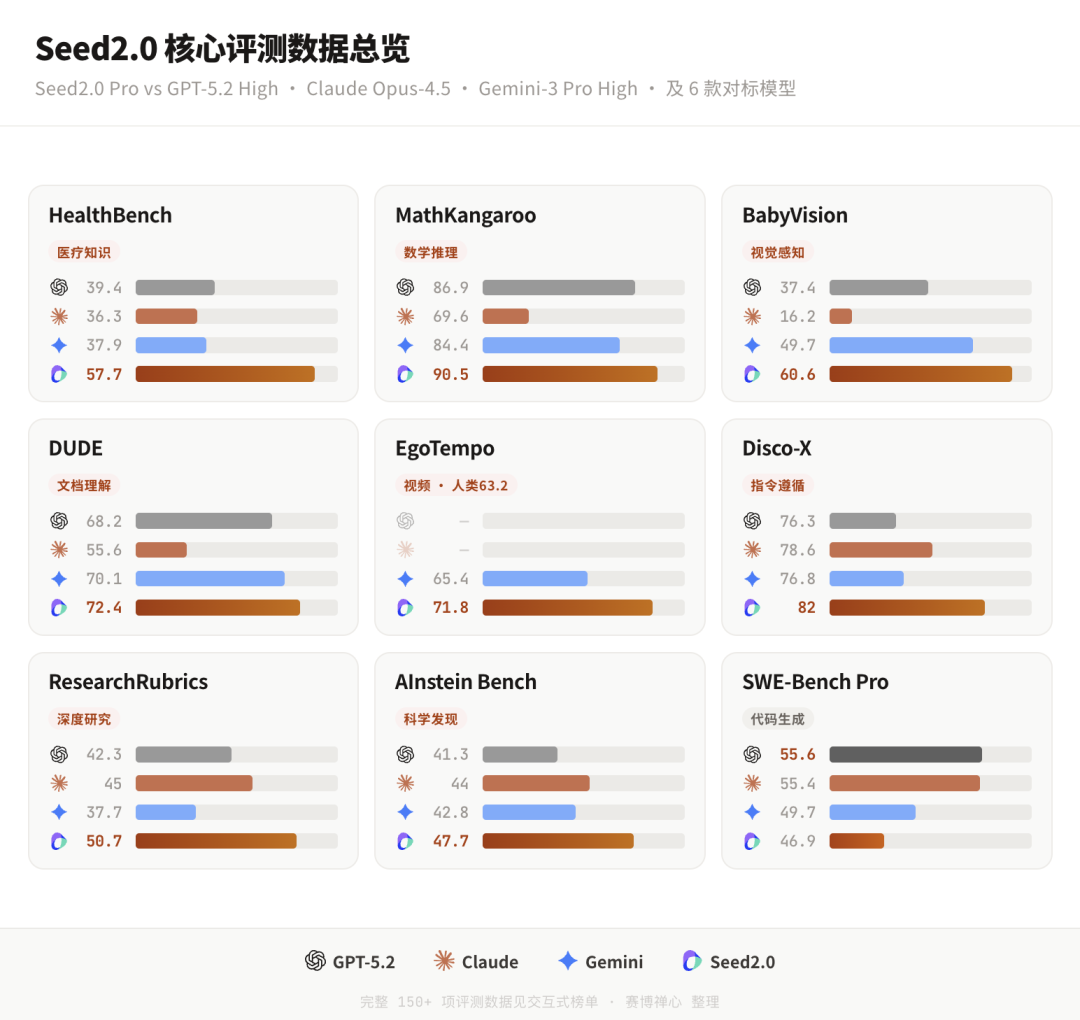
科学与长尾知识:HealthBench 排名第一,SuperGPQA 超过 GPT-5.2,整体与 Gemini 3 Pro、GPT-5.2 相当;在 FrontierSci 等 STEM 评测上表现亮眼。
代码:端到端生成与上下文学习能力明显进步,但在部分高难基准上与国际领先者仍有差距。
可用性:豆包 App 开通「专家」模式可用;TRAE 支持选择「Doubao-Seed-2.0-Code」;全系列 API 已登陆火山引擎。
成本优势:相比同级 GPT 与 Claude,API token 定价低一个数量级,面向长链路与大规模推理更具成本优势。
资料完整:同步发布 79 页 Model Card,公众号后台回复「Seed2.0」可获取。
注:文中对比信息基于官方公布与公开技术报告;部分数据源自公开技术基准。
定价与接入
四款模型均已在火山引擎开放 API(以下为分段计费中 ≤32k 输入的价格,单位:元/百万 tokens):
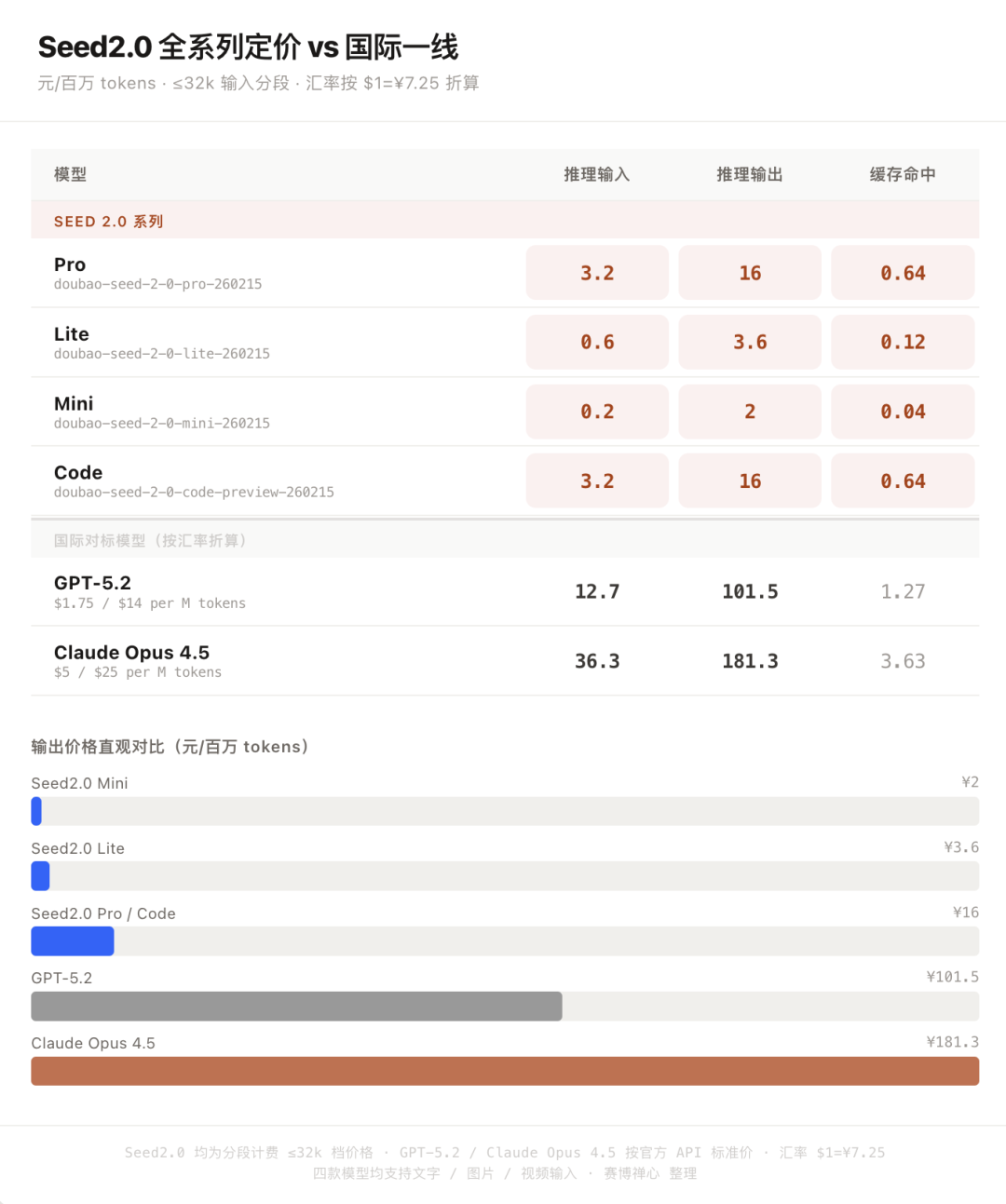
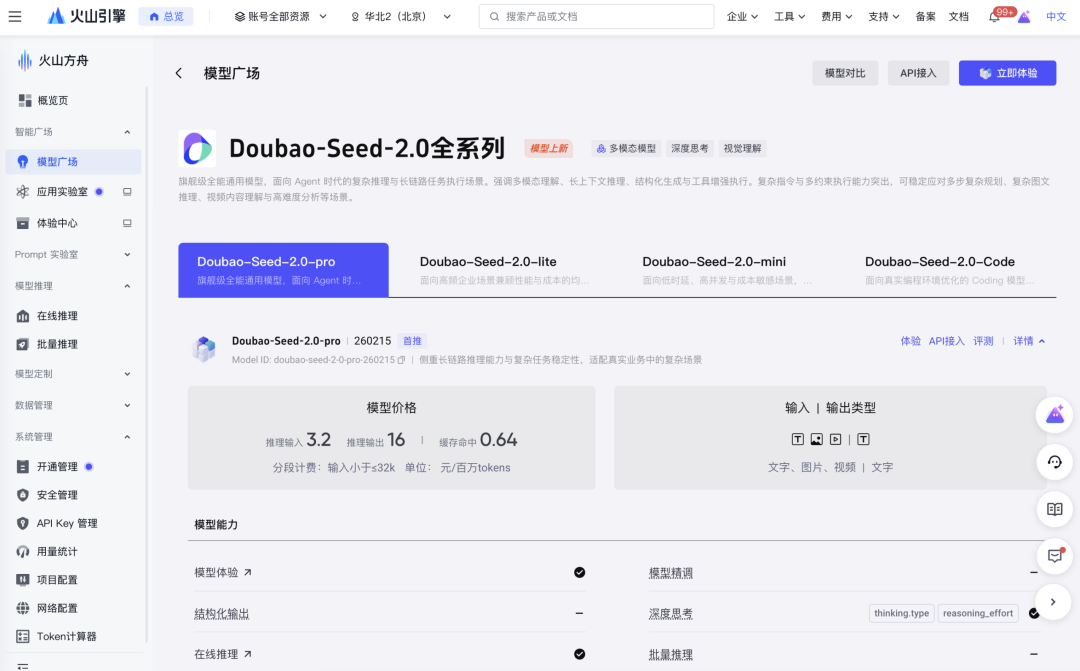
- Pro(doubao-seed-2-0-pro-260215):旗舰全能,面向复杂推理与长链路 Agent 任务
输入 3.2 / 输出 16 / 缓存命中 0.64 - Lite(doubao-seed-2-0-lite-260215):均衡型,综合能力超 Seed1.8,兼顾质量与速度
输入 0.6 / 输出 3.6 / 缓存命中 0.12 - Mini(doubao-seed-2-0-mini-260215):低时延高并发,256k 上下文,支持四档思考长度
输入 0.2 / 输出 2 / 缓存命中 0.04 - Code(doubao-seed-2-0-code-preview-260215):编程加强版,适配 Claude Code 等 IDE 工具链
输入 3.2 / 输出 16 / 缓存命中 0.64
支持文字、图片、视频输入,输出为文本。对比海外同级模型,token 定价低约一个数量级。
考虑到在真实复杂任务中,Agent 跑一次 workflow 消耗的 token 往往是常规对话的数十倍,成本优势更为明显。
模型详情页:https://console.volcengine.com/ark/region:ark+cn-beijing/model/detail?Id=doubao-seed-2-0-pro
优化思路与设计取向
Seed 团队基于 MaaS 在中国大陆的真实调用数据(火山方舟协作奖励计划)观察到:企业侧的高频需求集中在处理图表、扫描件、混排文档等非结构化知识材料,常以“先读懂、再执行”两段式流程展开。
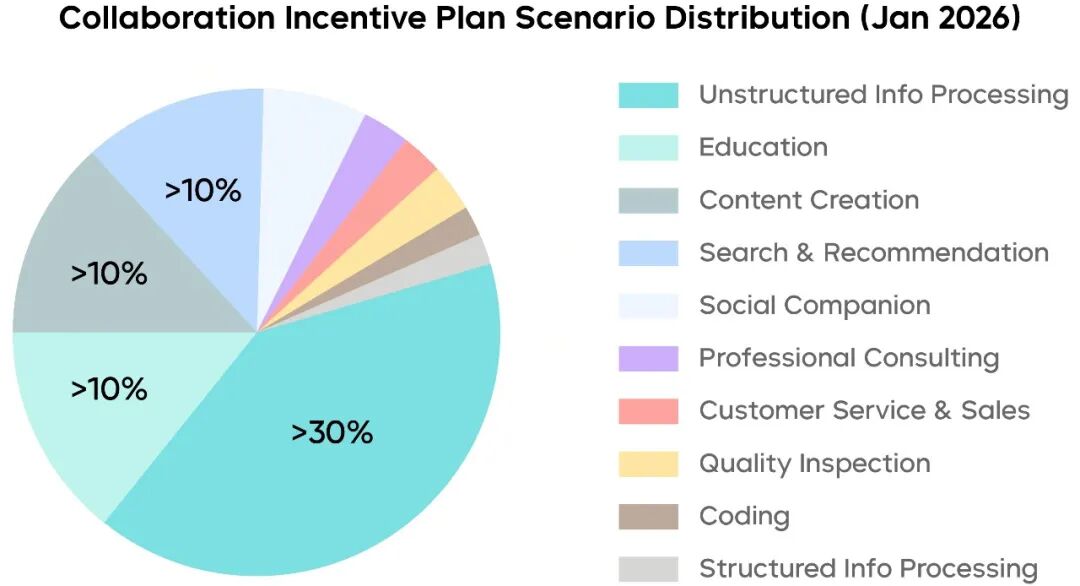
对应地,Seed2.0 聚焦三大方向:
- 更强的视觉与多模态理解:显著提升对复杂文档、表格、图形、视频的解析能力。
- 更可靠的复杂指令执行:优化多约束、多步骤、长链路任务的理解与执行稳定性。
- 更灵活的推理策略:Pro/Lite/Mini 与 Code 四款梯度覆盖不同场景与成本带宽。
除生产级需求外,Seed2.0 也在抬升智能上限:从奥赛级问题迈向研究级推理,尝试探索埃尔德什级数学问题,并能完成部分科学编程任务;同时具备“读懂一堆扫描合同并落实流程”的工程化能力。
多模态理解与长上下文
数学与视觉推理
Seed2.0 Pro 在 MathVista、MathVision、MathKangaroo、MathCanvas 等数学推理基准达到业内领先;在 LogicVista、VisuLogic 等视觉解谜与逻辑推理基准上较 Seed1.8 大幅提升。
视觉感知
在 VLMsAreBiased、VLMsAreBlind、BabyVision 等基准上取得高分,在多种视觉输入类型下保持稳定、可信的感知与判断。
文档理解与长上下文
针对复杂版式和非结构化材料,Seed2.0 在 ChartQAPro、OmniDocBench 1.5 达到顶尖水准;长上下文方面在 DUDE、MMLongBench、MMLongBench-Doc 等取得业内最佳。
视频理解
- 时间序列与运动感知:在 TVBench、TempCompass、MotionBench 等关键测评领先;EgoTempo 得分 71.8,超过人类水平(63.2)。
- 长视频:在多数评测中优于其他顶尖模型,可高效处理小时级长视频;配套工具 VideoCut 进一步拓展处理时长与推理精度。
- 流式实时视频:在实时分析、环境感知、主动纠错与情感陪伴方面表现良好,可用于健身、穿搭等场景。
说明:部分数据引自公开技术报告。
LLM 与 Agent:真实长程任务能力
团队指出:尽管模型已能解竞赛难题,但在真实世界里,要端到端完成如“从零构建设计精良、功能完整的小程序”等任务仍具挑战。关键原因在于:
- 真实任务跨越更长时间尺度、包含多阶段,现有 LLM Agent 难以自主构建高效工作流。
- 各行业知识长尾且壁垒高,训练语料中高频覆盖有限。
长尾知识强化:Seed2.0 系统性增强了长尾领域知识能力:SuperGPQA 超过 GPT-5.2,HealthBench 居首;总体与 Gemini 3 Pro、GPT-5.2 相当,FrontierSci 等 STEM 基准表现突出,部分场景超过 Gemini 3 Pro。
指令遵循与流程稳定性:保持较强一致性与可控性,为长链路、多步骤、强约束任务提供基础。
深度研究工作流:在“找资料—归纳—写结论”等连续研究流程中表现优异,多项深度研究评测中,Pro 与 Lite 都取得了不俗成绩。
真实世界任务:在客服问答、信息抽取、意图识别、中小学题目解答等高频生产场景稳定;在 GDPVal-Diamond、XPert Bench 等复杂专业基准上亦具竞争力。
科学发现与实验落地
在 FrontierSci-research、AInstein Bench 等前沿科研评测中表现强劲,展现出较强的假设驱动式推理能力。更进一步,Seed2.0 能把“研究想法”推进为“可执行的实验方案”。
示例:高尔基体蛋白分析实验方案——模型将基因工程、小鼠模型构建、亚细胞分离与多组学分析串联为完整流程,细化到关键步骤、对照设置、污染排除与纯度评估指标等。相关领域专家反馈称:在跨学科细节与步骤化表达方面超出预期,产出的草案结构清晰、科学上相对可靠、具备可执行性。
代码能力
在端到端代码生成与上下文学习上显著进步(如 Vibe Coding 与相关 ICL 评测),但在部分高难任务上仍与国际领先模型存在差距。
如何使用与优惠
- 火山引擎 API:四款模型全面上线。
- 豆包 App:选择「专家」模式开启对话。
- TRAE:内置模型中选择「Doubao-Seed-2.0-Code」。
- 方舟 Coding Plan:已支持此模型,首月低至 8.91 元,“新春限时特惠 × 二月特别补贴”。

Model Card 获取
官方同步发布了 79 页 Model Card。关注公众号并回复「Seed2.0」即可获取。
