最近这两天,社交媒体上关于 Claude Sonnet 5(代号 Fennec)的消息已经传得沸沸扬扬。如果这些爆料属实,我们可能在本周左右就会迎来这位新成员。
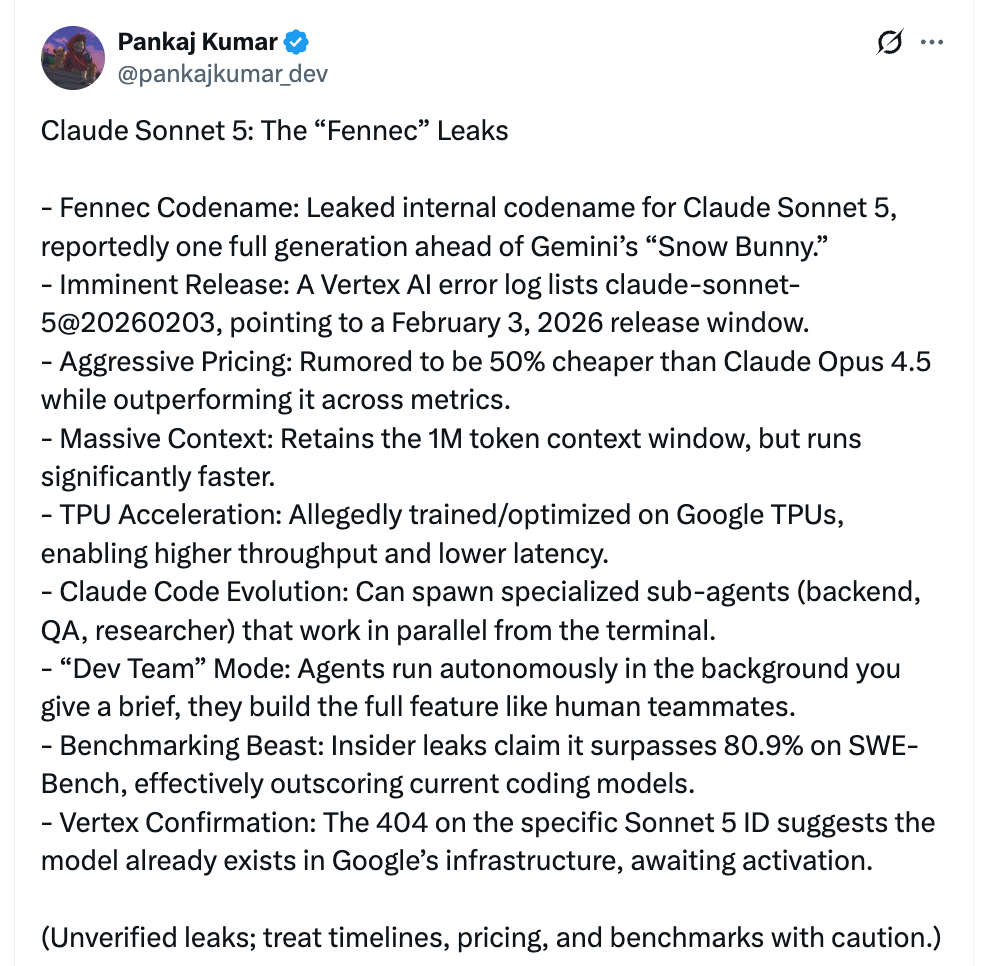
关键信息(均为泄露与传闻,未获官方确认)
发布窗口与代号:一条疑似 Google Vertex AI 的错误日志出现模型 ID“claude-sonnet-5@20260203”,常见含义是部署窗口落在 2026-02-03 左右。内部代号为“Fennec”。我尝试在 Vertex 侧访问该 ID,目前返回 404,这在云端产品里通常意味着“已部署但未对外开放”。
性能指标:传闻 SWE-Bench 得分>82.1%。同时有说法称 Sonnet 5(中杯定位)在综合表现上超过上一代高配 Opus 4.5。具体测试集、评估方法、复现实验尚未公开。
价格与速度:爆料称价格与 Sonnet 4.5 持平,泄露中明确的是输出 $15/1M tokens,输入侧价格未被清晰披露(一般与现价相近)。据称针对 Google TPU 做了训练和推理优化,在维持约 1M 上下文窗口的同时降低延迟。
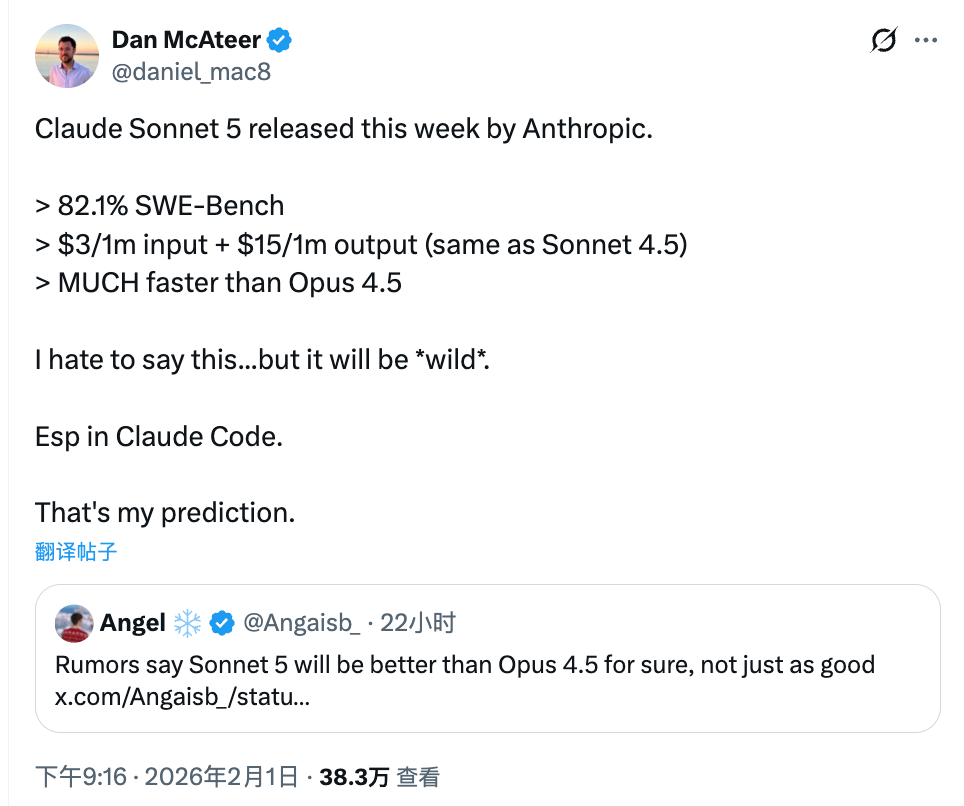
Claude Code 的“Dev Team”模式:信息称将支持并行子 Agent,能在终端执行、分工协作(后端编码、QA、资料检索等),更接近原生集成的 Agentic Workflow。
差异化维度:如果传闻属实,关键变化在哪些方面
| 维度 | 现状(Sonnet 4.5) | 传闻(Sonnet 5 / Fennec) | 适配建议 |
|---|---|---|---|
| 功能范围 | 通用对话与编码协助,单 Agent 工作流为主 | 内建并行子 Agent与终端协作,“Dev Team”模式 | 准备好工具链隔离(容器/沙箱)、权限边界与日志审计 |
| 技术特征 | 1M 上下文,GPU/TPU 混合;常规推理延迟 | 仍为约 1M 上下文;TPU 定制优化,延迟下降 | 对交互式编码、批量评测、长文档任务做延迟与吞吐评估 |
| 性能指标 | 在 SWE-Bench 等任务表现稳定 | 传闻 SWE-Bench>82.1%,综合超过 Opus 4.5 | 用自家代码库做复现实验,不直接用公开分数做选型 |
| 使用门槛 | 低到中:提示工程、少量工具集成 | 中到高:多 Agent 并发、任务编排、资源治理 | 团队需具备 CI/CD、环境管理、失败恢复与回滚能力 |
| 适合人群 | 个人开发者、小团队的日常协作 | 需要仓库级自动化、并行任务的中大型团队 | 先在试点项目落地,逐步扩大覆盖范围 |
| 价格策略 | 输入/输出分级计费,输出约 $15/1M tokens | 传闻与 4.5 持平(输入未明确,输出 $15/1M tokens) | 以成本/修复量为单位做预算:每次 PR、每千测试用例的成本 |
开发者视角:可落地的影响与场景
- 代码修复与仓库级任务
- 如果 SWE-Bench 的提升在你们代码库可复现,自动修复、测试补齐、依赖升级、API 迁移等仓库级任务的成功率会提高。
- 建议以“任务包”为单位做评估:例如针对 50 个历史失败用例,统计成功率、平均 tokens 消耗与时延。
- 交互体验与吞吐
- TPU 优化若带来更低延迟,交互式编码(Cursor/Claude Code)体验会更流畅,批量评测与报告生成的吞吐也会提升。
- 关注流式输出稳定性、长上下文下的注意力质量与断流恢复。
- 多 Agent 编排
- “Dev Team”模式适合把任务拆成并行链路(开发、测试、检索)。这需要明确工具权限、产物落盘位置、并发上限和故障策略。
- 推荐使用短生命周期容器隔离每个子 Agent,产物统一走制品仓库,日志通过集中式收集(如 OpenTelemetry)。
- 成本控制
- 若价格不变,价值主要来自延迟和成功率的提升。把“每次合并请求的平均 tokens 成本”“每千测试的成功率”作为对比指标更有意义。
- 对于个人开发者,设定月度上限与并发限制,避免多 Agent误触发大量外部工具调用。
不确定性与风险标注
- 基准数据:SWE-Bench 分数可能针对特定子集或特定评估协议,复现性待验证。
- 发布时间:即使日志显示窗口,开关也可能因技术或合规原因推迟。
- 功能可用性:多 Agent/终端能力可能分阶段开放,或者受地区与平台限制。
- 费用细节:输入侧价格尚未明确,实际计费还需以官方公告与控制台为准。
行动建议:如何准备评估与迁移
- 准备评估用例:挑选能代表真实工作的任务包(代码修复、测试生成、长文档总结),定义成功标准与度量方式。
- 搭好隔离与审计:为并发子 Agent配置容器/沙箱、权限白名单与日志采集,提前演练失败回滚。
- 建立成本视角:不只看单次调用成本,用“每次 PR 成本”“每千测试成功率”做性价比比较。
- 逐步迁移:从试点项目开始,观察延迟与质量稳定性,再扩大到核心仓库与生产流程。
- 跟踪官宣:以 Anthropic 官方文档与控制台信息为准,避免基于传闻做大规模改造。
结语
从产品与开发的角度,这次传闻里最值得关注的是三点:更高的仓库级任务成功率、更低的交互与批量延迟、以及更原生的多 Agent 编排。如果这些能力在正式版中落地,开发团队的自动化边界会扩大一圈。但在官宣之前,保持实验心态更稳妥:准备好评估集、环境治理与成本视角,到时候用自家数据说话。我会在官方发布后第一时间补充对比结果与迁移建议,欢迎继续关注。
声明:本站原创文章文字版权归本站所有,转载务必注明作者和出处;本站转载文章仅仅代表原作者观点,不代表本站立场,图文版权归原作者所有。如有侵权,请联系我们删除。