阿里巴巴 通义实验)发布了一款名为Z-Image(造相)的高效图像生成基础模型。
-
模型参数:6B(60亿)
-
显存占用:16GB以下即可运行
-
生成速度:8步采样即可出图
-
支持设备:消费级显卡即可流畅运行
它是通义家族中首个完全开源、支持中英文双语、性能接近 Gemini 的模型系列。
而其中的核心版本 —— Z-Image-Turbo,是它的“极速版”,主打三个关键词:
快 —— 只需 8 步生成高清图像(别人要 30~50 步)。
精 —— 画面写实、光影自然、文字可控(中英双语)。
聪明 —— 能理解复杂指令并准确执行图像变化。
它的核心目标是:
在保持照片级真实感(photorealism)的同时,大幅降低计算和显存成本,
让顶级AI图像生成技术可以在普通显卡上流畅运行(16GB显存即可)。
过去,如果你想要照片级的真实感、准确的中文字渲染,以及复杂的图像编辑能力,往往要依赖几十 GB 显存的大模型。而 Z-Image 只有 6B 参数、16GB 显存即可运行,却能稳定产出能直接用于创意、广告、视觉设计的图像质量。
Z-Image 是什么?为什么值得关注
Z-Image 系列包括两个方向:
| 模型 | 用途 |
|---|---|
| Z-Image | 标准图像生成 |
| Z-Image-Edit | 文字驱动的图像编辑 |
全系列开源,能跑在 HuggingFace、ModelScope,普通消费级显卡即可流畅推理。
核心版本 Z-Image-Turbo 主打:
-
快:只要 8 步采样就能出图(主流模型常见 30–50 步)
-
清晰:真实感强、光影自然
-
稳:理解复杂指令,编辑任务一致性好
作为习惯跑 20+ 模型的人,我对它的速度提升感知很强。
核心能力
逼真的质量: Z-Image-Turbo 在生成逼真图像的同时保持了出色的美学质量。

准确的双语文本渲染: Z-Image-Turbo 擅长准确渲染复杂的中英文文本。

提示增强与推理: 提示增强器赋予模型推理能力,使其能够超越表面描述,挖掘潜在的世界知识。

创意图像编辑: Z-Image-Edit 对双语编辑指令有很强的理解力,能够实现富有想象力和灵活性的图像变换。

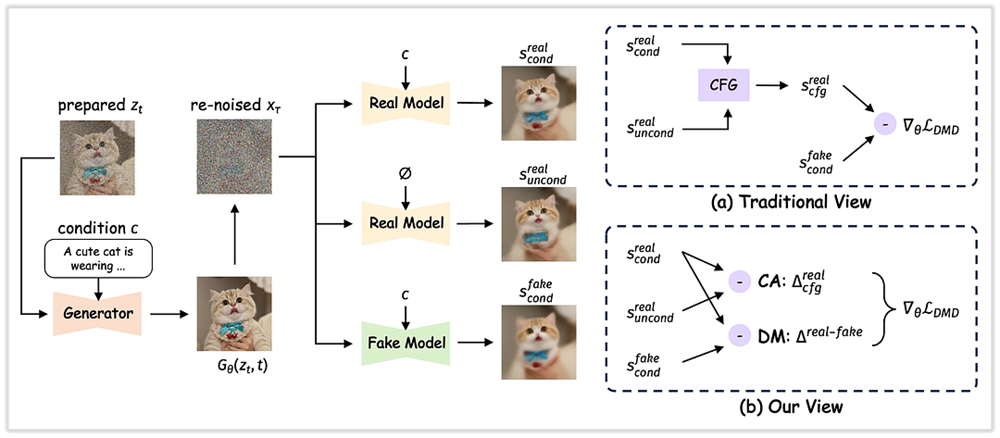
模型架构
我们采用了一种可扩展的单流DiT(S3-DiT)架构。在这种设置中,文本、视觉语义标记和图像VAE标记在序列级别上连接起来,作为统一的输入流,与双流方法相比,最大化了参数效率。
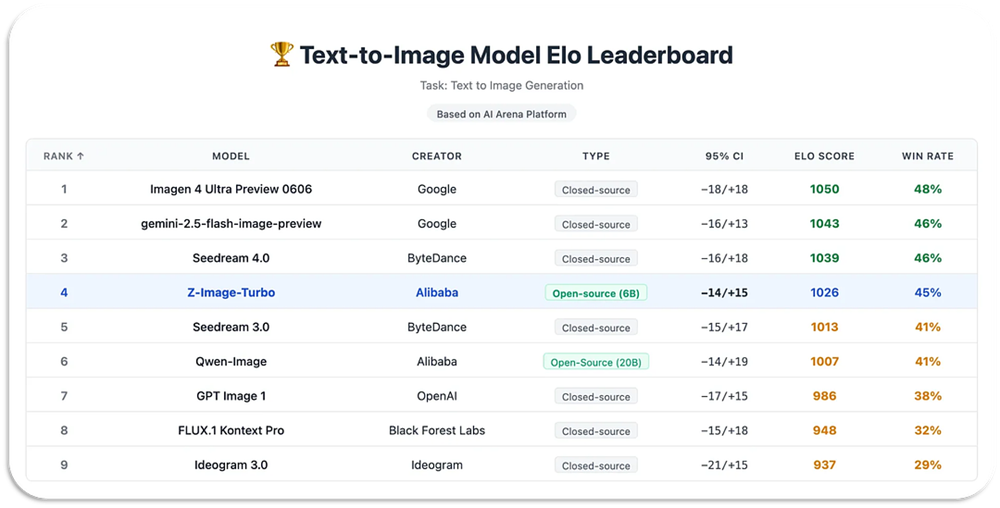
性能
根据基于Elo的人类偏好评估(在AI Arena上),Z-Image-Turbo相对于其他领先模型表现出极高的竞争力,同时在开源模型中取得了最先进的结果。
关键技术亮点
| 技术 | 作用 |
|---|---|
| Decoupled-DMD 蒸馏 | 提升 8 步生成能力(效率 + 质量) |
| DMDR(蒸馏 + RL) | 结构保持更稳定,画面更统一 |
| Prompt Enhancer | 自动补全逻辑,提高普通用户的出图成功率 |
从产品的角度看,这三个技术点都是“提升体验”的核心因素。
性能对比:1/3 计算量 ≈ 商业级质量
在 AI Arena 的 Elo 评估中,Z-Image 在开源模型里是领先水平,同时在一些指标上逼近商业旗舰模型。
这意味着它的“单位显存价值”非常高。
项目资源
GitHub:https://github.com/Tongyi-MAI/Z-Image
HuggingFace 模型:https://huggingface.co/Tongyi-MAI/Z-Image-Turbo
在线体验:
https://huggingface.co/spaces/Tongyi-MAI/Z-Image-Turbo
https://www.modelscope.cn/models/Tongyi-MAI/Z-Image-Turbo