这个视频中,风刮玻璃、狂野感的森林环境音和鸟叫声、火球发射后爆炸声、布鞋踩在松软草原的脚步声——这些一系列场景的配音都是 AI 生成的。
今天要推荐的开源语音大模型 AudioX-Turbo,能把视频场景直接转成高质量配音,效果确实惊艳。
01 项目简介
AI 视频生成这一年卷得离谱,Seedance、可灵等已经把效果拉到电影级。但 AI 音频这边还有不少痛点:主流方案还在用几十步甚至上百步的扩散采样,生成一段 10 秒的音频要等好一阵。
港科大、清华联合 Noiz AI 刚开源了 AudioX-Turbo,目标就是解决极速推理与精准可控两大难题。
它是一个统一的 Anything-to-Audio 生成框架。输入支持纯文本、纯视频、纯音频,或者任意组合。输出都是声音,可以是音效、环境音,也可以是音乐。
- 开源地址:https://github.com/NoizAI/AudioX-Turbo
- 论文:https://arxiv.org/abs/2606.12555
- 模型权重:https://huggingface.co/HKUSTAudio/AudioX-Turbo
02 效果展示
文字生成音频:在键盘上打字、烟花绽放两次后钟声滴答作响
文字生成音乐:平滑的城市 R&B 节拍、适合旅行视频的振奋人心尤克里里曲调
视频转音频:根据视频画面自动生成匹配的环境音和音效
视频转音乐:根据视频情绪自动生成配乐
03 两大核心能力
一个模型干 6 件事
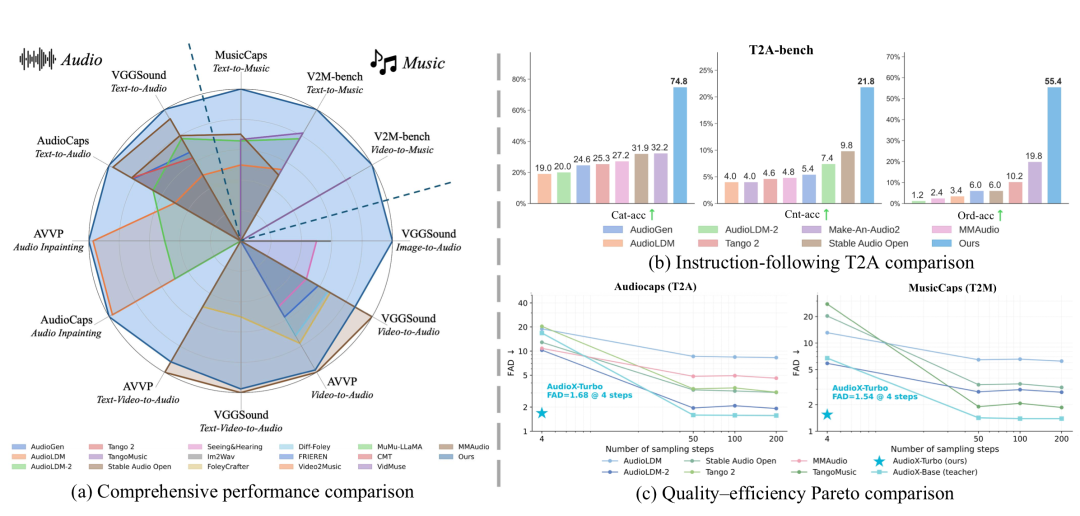
大多数音频生成模型都是单一任务,AudioX-Turbo 把 6 种任务装进了一个模型:文本生成音频、文本生成音乐、视频生成音频、视频生成音乐、文本加视频生成音频、文本加视频生成音乐。
更关键的是生成速度极快——4 步就能出结果。这是 AudioX-Turbo 最核心的能力。
技术路径走的是师生蒸馏:先用完整的多步扩散模型 AudioX-Base 当老师,再用 Distribution Matching Distillation 配合扩散判别器,把它压缩成 4 步就能出结果的 AudioX-Turbo。
对实际应用来说,响应延迟可以从分钟级降到秒级,做实时交互的 AI 音频工具有了可行性。
数据壁垒
训练数据是这类大模型项目的核心壁垒。AudioX-Turbo 自建了 IF-caps-Pro 数据集,规模约 920 万条样本,通过两阶段数据采集和标注流程构建。
社区里大多数开源音频模型要么用 5 万条的 AudioCaps,要么用 5 千条的 MusicCaps,数据量级直接被拉开了一个数量级。
04 怎么用起来
官方推荐 A100 或 H800、CUDA 12.1,DeepSpeed 训练路径还需要完整 CUDA toolkit。普通个人玩家跑推理勉强,完整复现训练基本要实验室级别。
安装步骤
# Clone the repository
git clone https://github.com/NoizAI/AudioX-Turbo.git
cd AudioX-Turbo
# Create a conda environment
conda create -n audiox-turbo python=3.8.20
conda activate audiox-turbo
# Install media libraries
conda install -c conda-forge ffmpeg libsndfile
# Install dependencies
pip install -r requirements.txt
pip install -e . --no-deps
pip install soundfile==0.12.1模型权重托管在 HuggingFace,用 huggingface-cli 下载:
pip install -U "huggingface_hub[cli]"
# Inference checkpoints (student + VAE + Synchformer)
huggingface-cli download HKUSTAudio/AudioX-Turbo \
audiox_turbo/audiox_turbo.ckpt pretransform/vae.ckpt synchformer/synchformer_state_dict.pth \
--local-dir checkpoints
# Training only: teacher / base model
huggingface-cli download HKUSTAudio/AudioX-Turbo \
pretrained_ckpt/pretrained_ckpt.ckpt \
--local-dir checkpoints推理方式
Gradio 一行命令启动:
python run_gradio.py # http://localhost:7860
python run_gradio.py --share # 生成公开链接Python API 调用:核心是 load_audiox_turbo_model 加载模型,generate_diffusion_cond_dmd 跑 4 步生成,最后用 torchaudio.save 落盘。仓库给了完整的示例代码,包括视频条件下的 Synchformer 特征提取、音频后处理、视频音频合并等。
写在最后
AudioX-Turbo 把音频生成从"慢但可控"推进到了"又快又可控"的阶段。
4 步推理 + 多模态输入,意味着实时 AI 配音工具终于有了落地基础。对于视频创作者来说,再也不用手动找音效和配乐了。