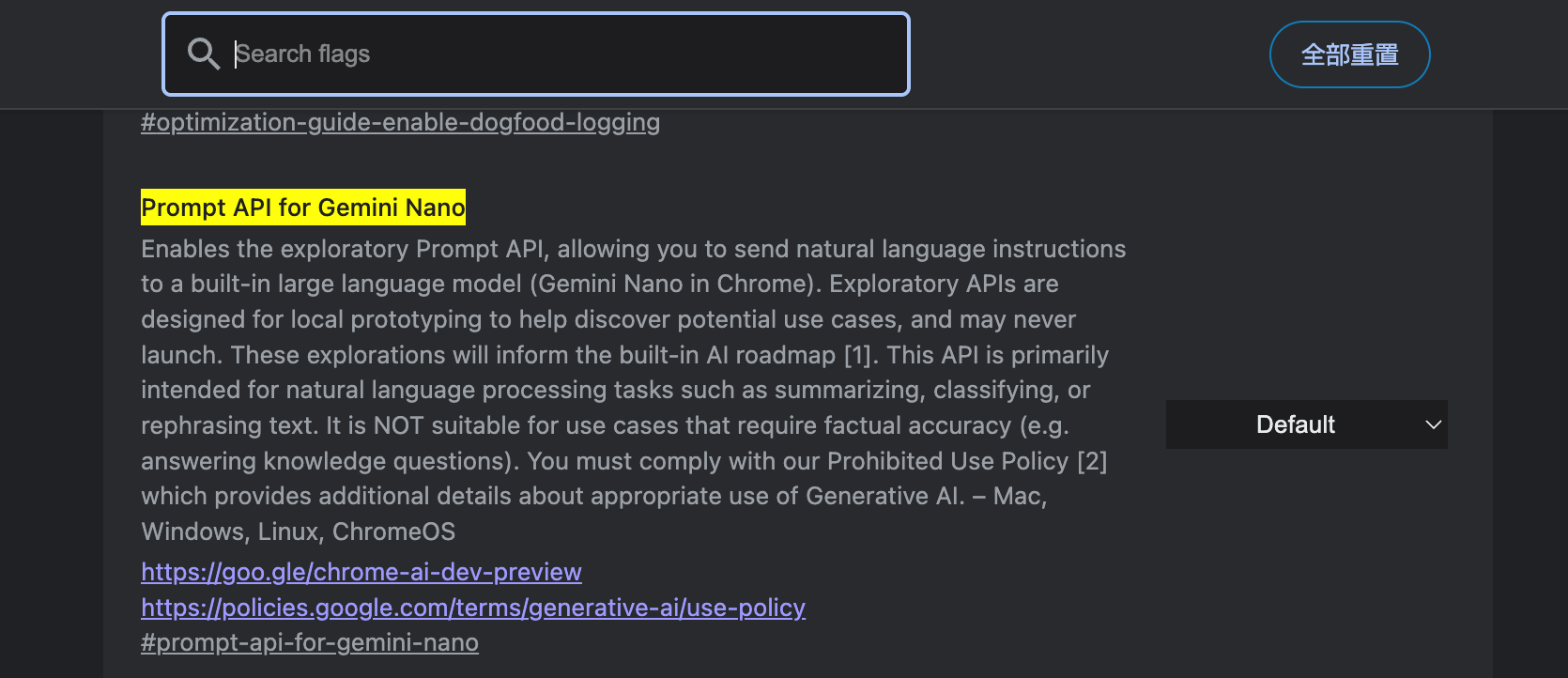
Chrome 浏览器内置了 Gemini Nano 本地推理能力,但默认隐藏且配置繁琐。一个名为 gemini-nano-chrome 的开源项目提供了一套开箱即用的解决方案——自动配置 Chrome 启动参数、下载模型、启动服务,并提供三种使用方式。
GitHub 仓库:https://github.com/Ar9av/gemini-nano-chrome
核心功能
本地推理,隐私安全 — 模型运行在用户自己的电脑上,所有聊天记录保存在本地,不涉及云端传输。支持流式输出,响应呈现打字机效果。
OpenAI 接口兼容 — 工具会在本地启动一个 HTTP 服务器(默认端口 8788),API 格式与 OpenAI 完全一致。这意味着可以将现有 ChatGPT 客户端的 Base URL 指向 http://localhost:8788,即可无缝切换。也可以用 Python 的 openai 库或 curl 直接调用。
开发者友好 — 支持强制返回 JSON 格式输出。例如发送情绪分析请求,模型会直接返回 {"sentiment": "positive", "confidence": 0.95} 这样的结构化数据,无需额外解析。
一键配置 — 无需手动在 chrome://flags 中寻找隐藏开关,脚本自动配置 Chrome 启动参数,并自带进度条显示模型下载状态。

前置要求
项目要求
| 浏览器 | Chrome 138+(推荐 Dev 或 Canary 版本,稳定版可能不支持) |
| 系统 | Windows 10/11、macOS 13+、Linux 或 ChromeOS |
| 硬盘 | 至少 22 GB 可用空间(模型文件约 4GB) |
| 硬件 | 独立显卡 4GB+ 显存,或 16GB 内存 + 4 核以上 CPU |
| 网络 | 首次运行需下载约 4GB 模型文件 |
快速开始
需要 Node.js 环境,三条命令即可:
git clone https://github.com/Ar9av/gemini-nano-chrome.git
cd gemini-nano-chrome
npm start脚本会自动完成:以正确参数启动 Chrome → 启动 API 服务器 → 打开聊天页面。
首次运行需要下载约 4GB 的模型文件,请保持网络畅通并等待下载完成。之后每次启动即可秒开。
已知限制
限制项说明
| 上下文窗口 | 最大 9216 tokens(输入+输出总和),超出会报 QuotaExceededError |
| 生成速度 | 约 50 tokens/秒 |
| 不支持图片输入 | 仅支持文本 |
| 不支持 max_tokens | 该参数无效 |
| 不支持 embeddings | /v1/embeddings 端点不可用 |
苏米注:Gemini Nano 作为浏览器内置的本地小模型,9216 token 的上下文确实有限,适合短文本处理场景(如情绪分析、摘要、翻译)。但它的优势在于零延迟、零成本、完全离线运行。对于不需要云端 API 的轻量任务,这是一个实用的选择。4GB 模型下载一次后,后续使用完全免费。