在GitHub闲逛时,我发现了一个叫xan的命令行工具。作为经常处理数据的产品经理,我平时要么用csvkit,要么写Python脚本处理CSV文件,总觉得流程有些割裂。
xan声称从BurntSushi的xsv fork而来,但几乎完全重写,专门针对社交媒体和网络爬虫数据优化。
更有意思的是,这个Rust写的工具还能在终端里画直方图和散点图——这不像个单纯的命令行工具,更像是一把想在终端里安家的瑞士军刀。
项目概述
xan是一个用Rust编写的命令行CSV处理工具,专门为从shell环境直接处理结构化数据而设计。
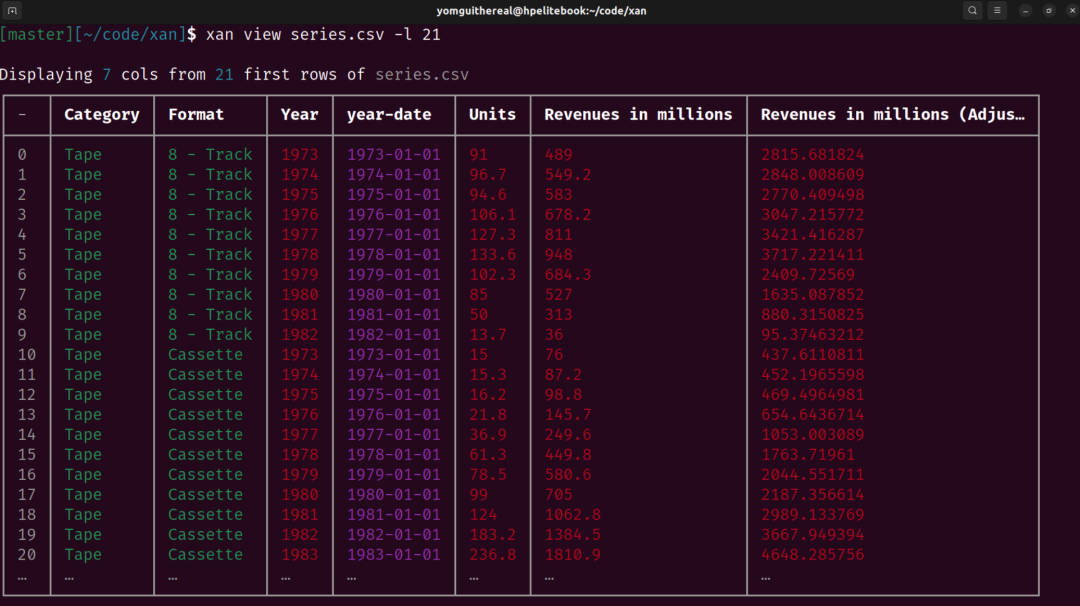
它的核心定位是高性能、低内存占用,能够轻松处理GB级别的大文件。与传统工具不同的是,xan不仅提供基础的数据操作(过滤、聚合、排序、连接、转换),还集成了表达式语言、数据可视化等功能,试图减少用户在多个工具间的切换。
- 开源成就:GitHub 3.6k+ Stars
- 开发语言:Rust
- 项目体积:不到6MB(预编译版本)
核心功能分析
1. 性能与内存效率
xan的立身之本在于性能。采用Rust语言和新型SIMD CSV解析器,使其在处理大文件时相比Python脚本或传统工具有明显优势。官方声称可轻松应对GB级数据,部分计算支持多线程并行处理。对于需要频繁处理日志或爬虫数据的场景,这种性能提升能显著减少等待时间。
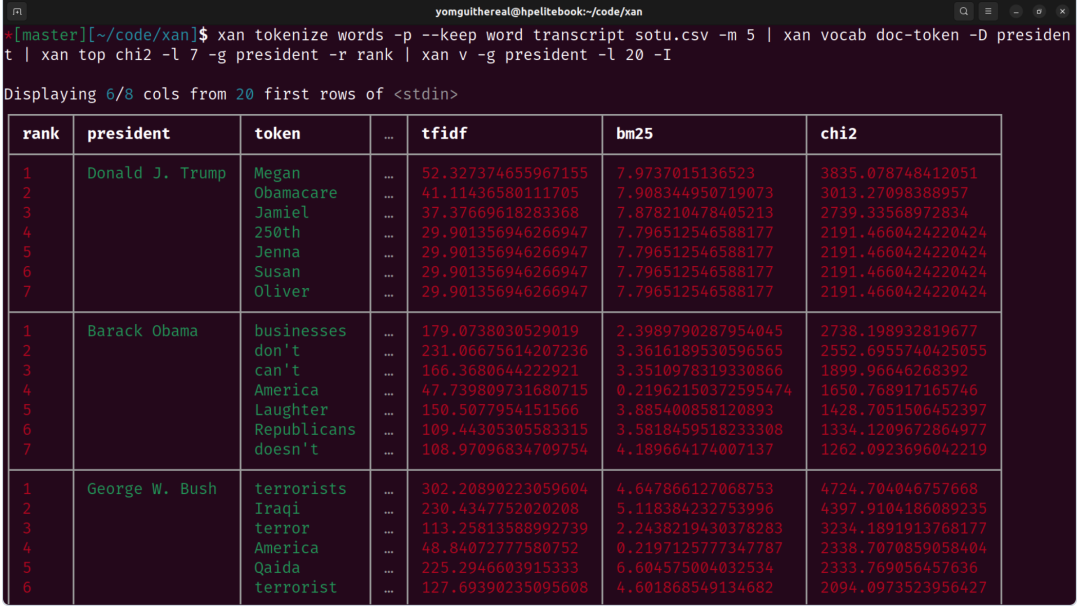
2. 内置表达式语言
这是xan超越同类工具的关键差异化功能。用户无需频繁启动Python解释器,直接通过表达式语言执行过滤和计算:
xan filter 'batch > 1' # 直接筛选
xan filter 'length(name) > 5 AND age < 30' # 复杂条件支持字符串处理、数学计算等常见函数,使用成本在学习曲线和执行效率间取得平衡。
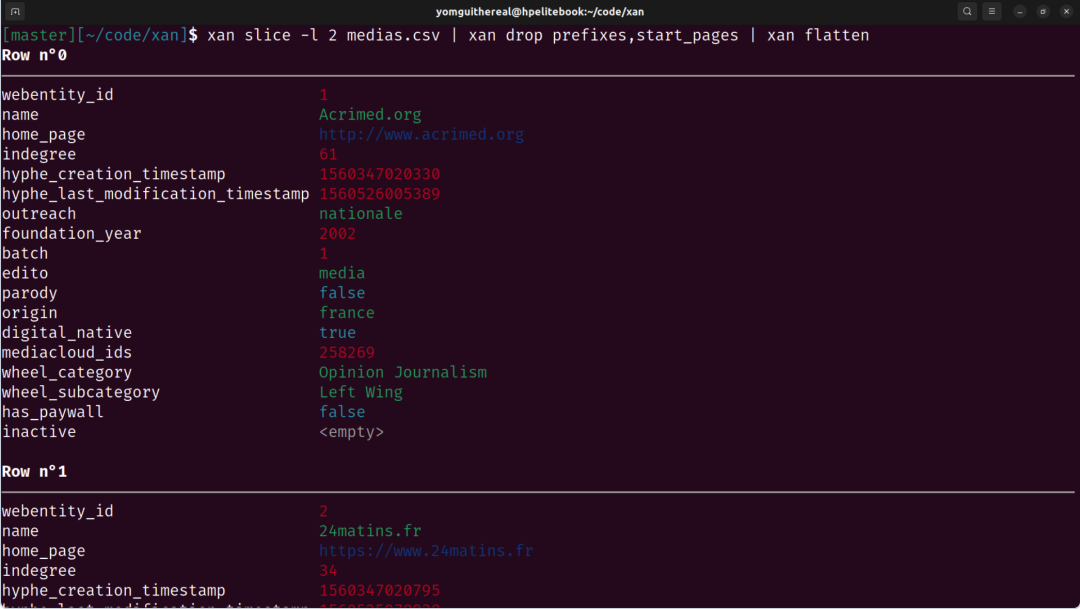
3. 终端内数据可视化
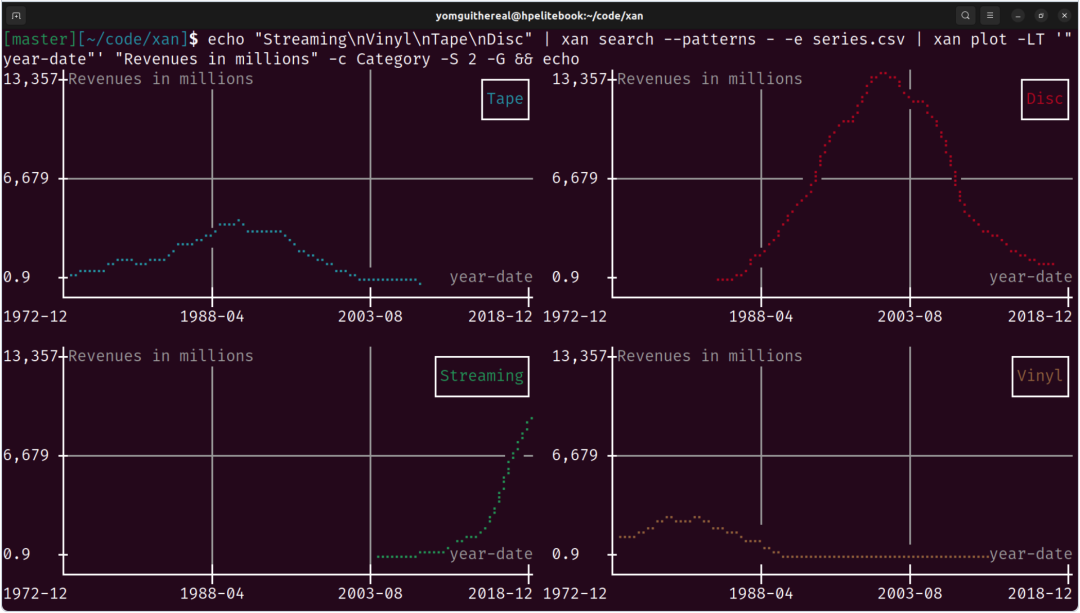
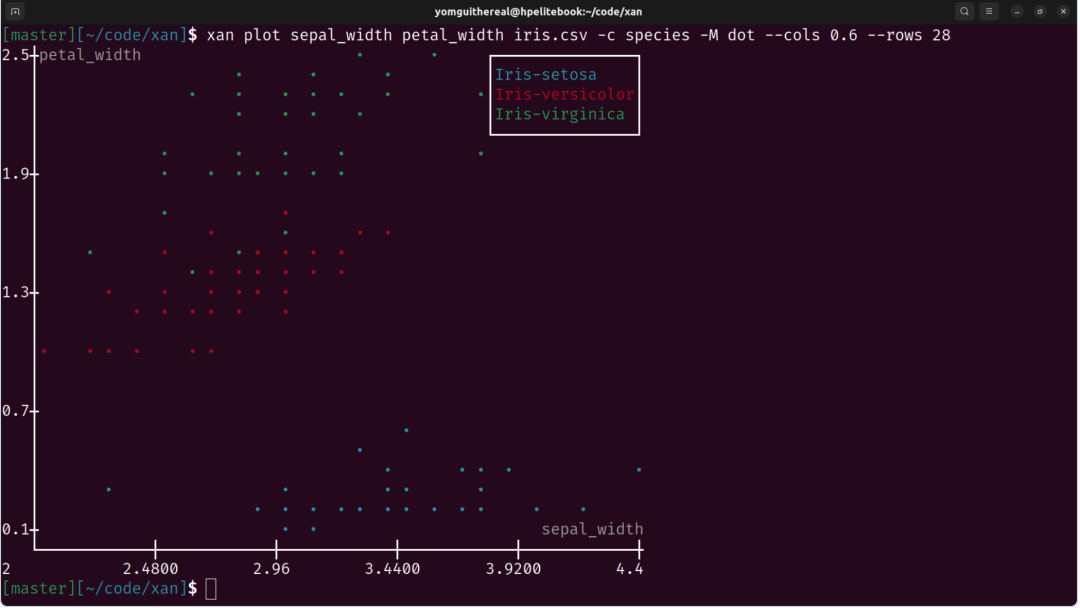
xan在终端中提供基础数据可视化能力,包括直方图、散点图和热力图。虽然采用字符画渲染(视觉上有些"复古"),但实用价值明显:
xan freq -s editor medias.csv | xan hist # 快速查看分布这样的工作流避免了切换到专门可视化工具的开销,适合快速数据探索阶段。
4. 多格式支持
xan不仅支持CSV和TSV,还能处理:
- JSONL(JSON Lines)
- 生物信息学格式(VCF、GTF)
- 压缩文件(.gz、.zst)
- 索引压缩文件(.gzi)用于加速随机读取
默认根据文件扩展名自动推断分隔符,也支持通过-d参数手动指定。这种设计细节说明项目充分考虑了实际使用场景的多样性。
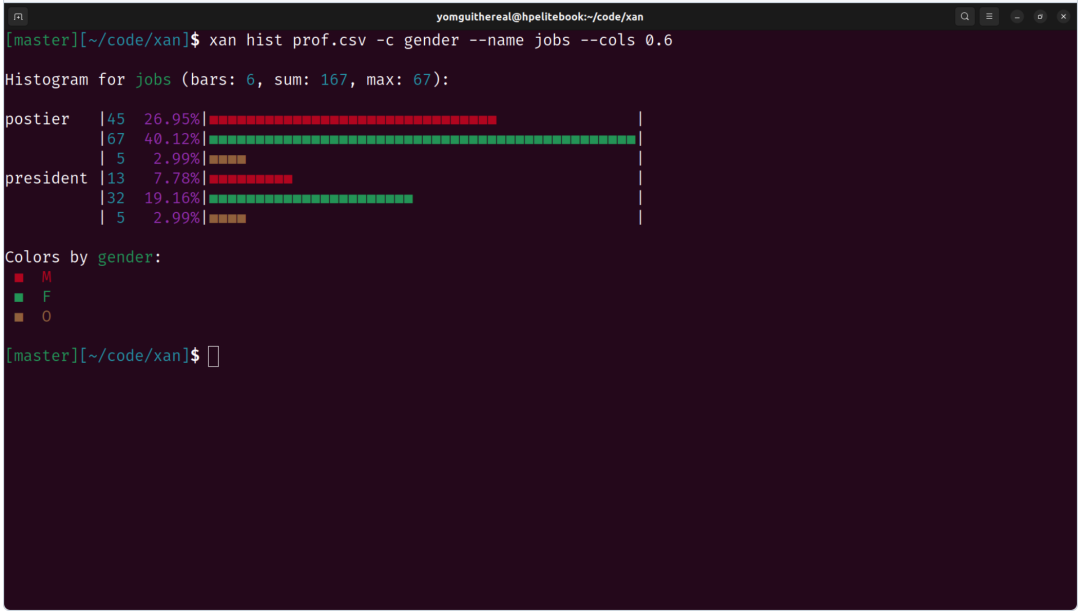
5. 聚合与分组能力
基础操作(sort、dedup)外,xan的groupby和agg命令配合表达式语言,能完成复杂聚合:
xan agg sum,mean,count grouped_col data.csv # 多维度聚合
xan window -w 7 --op mean value.csv # 7天移动平均window功能支持滑动窗口计算,使初步时间序列分析也能在命令行完成。
6. Unix设计哲学
xan遵循传统命令行工具的设计约定:默认从stdin读取,往stdout写出,方便管道串联。所有命令都提供-h帮助文档,支持生成shell补全脚本。这种设计让用户体验相对顺畅,没有与GUI软件"打架"的别扭感。
应用场景
| 场景 | 核心优势 |
| 日志分析与清洗 | 快速过滤、聚合GB级日志;表达式语言支持复杂条件 |
| 爬虫数据处理 | 原生支持多格式;性能优势明显 |
| 数据探索与验证 | 快速可视化分布;避免在多工具间切换 |
| 时间序列初步分析 | window函数支持移动平均、累计计算 |
安装与配置
安装方式
xan提供多种安装途径,用户可根据环境选择:
# 方式1:通过Cargo安装(需要Rust环境)
cargo install xan --locked
# 方式2:Homebrew(macOS)
brew install xan
# 方式3:Scoop(Windows)
scoop bucket add extras && scoop install xan
# 方式4:直接下载预编译二进制
# 从 https://github.com/medialab/xan/releases 获取
配置补全
安装后可通过以下命令获取shell补全脚本:
xan completions -h # 查看支持的shell类型
# 支持补全命令和列名,提升交互体验与相似项目的对比
| 工具 | 语言 | 性能 | 可视化 | 表达式语言 |
| xan | Rust | 高(SIMD) | 是(字符画) | 是(自定义) |
| csvkit | Python | 中等 | 否 | 否 |
| xsv(xan的前身) | Rust | 高 | 否 | 有限 |
| DuckDB CLI | C++ | 非常高 | 否 | SQL方言 |
相比csvkit,xan性能更优;相比xsv(前身),xan增加了表达式语言和可视化;相比DuckDB,xan轻量但功能更专注于快速数据处理。
总结
xan的出现填补了一个细分空间:它不试图成为通用数据库引擎或重型分析工具,而是专注于"从命令行快速处理结构化数据"这一具体需求。对我这样的产品经理来说,其价值在于:
- 减少工具切换开销,工作流更连贯
- 性能优势让处理GB级数据不再是瓶颈
- 内置表达式语言和可视化覆盖80%的日常任务
- 轻量级(6MB)使其易于在各类环境中部署
如果你频繁处理CSV/日志数据,或需要快速探索爬虫结果,xan值得纳入工具箱。它不会是"最强"工具,但在特定场景下是最"恰好好用"的那个。