开篇:一次关于知识管理的认知升级
作为一名产品经理,我长期在思考一个问题:如何让AI真正融入日常工作流,而不只是作为一个偶尔调用的工具?答案出现在我开始用Obsidian搭建个人知识系统的那一刻。
过去一年,我把所有专栏文章、选题方案、播客摘要、周计划和项目文档都迁移到一个Obsidian Vault(存储库)中。
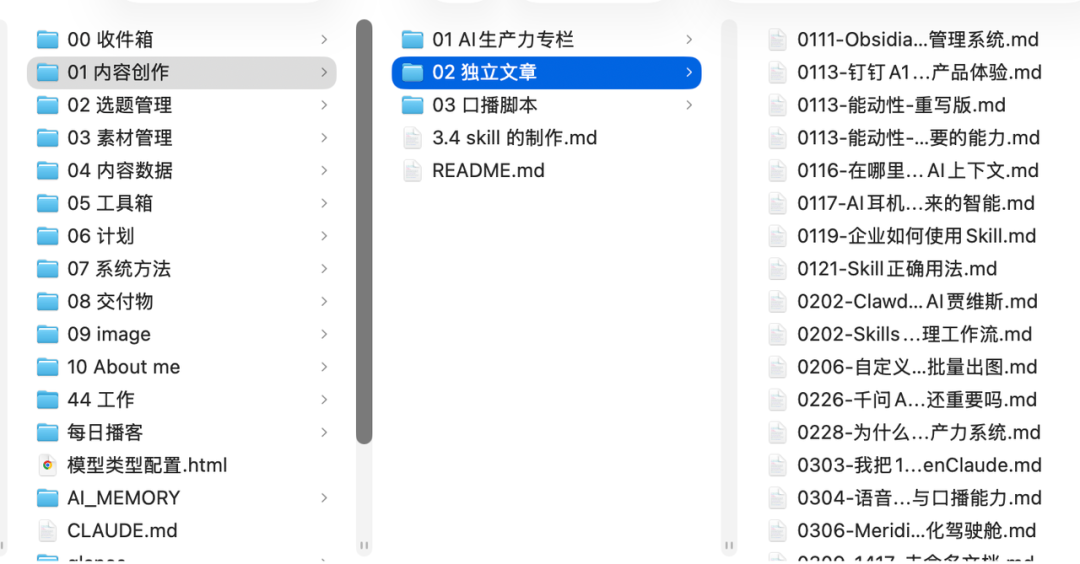
有趣的是,整个系统的价值在AI时代被重新定义了——它不再只是一个Markdown编辑器,而是一个AI可以直接读取、调用、执行任务的工作台。这种转变改变了我对生产力工具的理解。
这篇文章记录了我的完整思考过程,包括:为什么Obsidian适合作为AI的操作系统、如何从零搭建这套系统,以及在实践中总结的具体方法论。
如果你正在寻找一个兼具灵活性和专业性的个人AI生产力解决方案,这篇文章可能会给你一些启发。
一、理解Obsidian:从编辑器到AI工作台
1.1 Obsidian的本质是什么
很多人第一次接触Obsidian,会把它定位为"支持双向链接的Markdown编辑器"。
这个定义不错,但不够全面。从产品角度看,Obsidian更准确的描述是:本地文件夹的可视化编辑界面,加上围绕这个文件夹的工具生态。
具体来说:
- 所有笔记本质上是一个本地文件夹内的.md文件
- 这些文件可以通过CLI命令行被读取、调用
- Obsidian本身是这些文件的图形化编辑器和可视化层
- 在这个界面内,你可以看到AI在读什么、输出什么,保持完全的可控性
这个特性对于AI集成特别重要。相比于云端笔记或专有格式,本地Markdown文件意味着:Agent可以直接用grep、cat、sed等标准命令行工具操作;所有数据完全掌控在自己手里;可以配合任何第三方工具组合使用。
1.2 一个实用的类比:AI的工作桌模型
假设你要雇一个助理帮你处理工作,你会怎么准备?
- 给他一张整洁的桌子,上面分类摆好所有需要的文件夹
- 贴几张便签纸,明确标注哪些规则不能违反
- 放一本SOP手册,规定不同任务的执行流程
- 给他一支笔,让他能随手记录、输出工作成果
Obsidian就是这张桌子的数字化版本。在我的系统里:
- 每个文件夹是按分类整理的"文件柜"
- CLAUDE.md是那几张"便签纸",告诉AI这里有什么、不能碰什么
- 索引文件(JSONL)是那本"SOP手册"
- 与此同时,AI可以直接在这个系统内读、写、执行任务
这种模型相比于每次都要给Claude补充背景信息,效率高很多。AI已经掌握了所有context,工作时更专注、更精准。
1.3 核心方法论:剪藏、Wiki、规则三角
这套方法论来自Andrej Karpathy(前OpenAI联创、Tesla AI总监)在其个人知识系统中的实践。核心包含三个环节:
① 剪藏:信息的统一入口
所有值得保留的内容——文章、播客字幕、推文、想法——都进入Obsidian,而不是分散在浏览器书签、邮件、备忘录中。关键原因是:不在Obsidian里的信息,对AI系统等于不存在。
- 用Web Clipper一键保存完整文章
- 把播客字幕整段复制进来
- 转发有价值的推文到笔记
- 灵感来临时直接开新文件记录
② Wiki:让信息自组织成网络
当你在笔记中写[[概念名]]时,就在建立双向链接。随着时间推移,你的Vault会自然演化成一个个人Wiki——任何一篇笔记都能通过链接关联到背景资料、相似案例、相关概念。这是AI最好的上下文来源。
③ 规则:定义AI的行为边界
有原料、有连接还不够。需要一份明确的规则文档,告诉AI:
- 什么该做、什么不该做
- 写博客要遵循什么风格
- 创建新文件时应该放在哪里
- 不同类型的任务走什么流程
这三个环节形成闭环:信息进来 → 建立关联 → 按规则使用。
1.4 我的Obsidian运作机制:分层结构
基于上述方法论,我设计了一个更具体、更易执行的三层架构:
Layer 1:CLAUDE.md(AI的指引文件)
Agent进入Vault的第一个文件。内容包括:
- 项目概述:这个Vault是什么、核心目标是什么
- 模块地图:每个文件夹的职责和内容范围
- 核心行为规则:比如"JSONL只能追加不能覆盖""写文章前必读写作风格"
- 任务路由表:不同类型的任务走哪个流程、需要读哪些文件
Layer 2:文件夹结构(信息的骨架)
采用"序号+中文名"的命名规范,保证排序稳定、一眼可懂。示例:
- 05 工具箱 — 插件、脚本、Skill
- 06 计划 — 年度 → 周计划 → 每日 → 复盘
- 07 系统方法 — 工作流、迭代记录
- 08 交付物 — 工作交付、甲方内容
- 10 About me — 个人介绍、写作风格、审稿标准
Layer 3:具体文件(执行层)
- 独立文章:MMDD-标题.md
- 专栏文章:章节号-标题.md
- 索引文件:xxx_index.jsonl(记录Agent在该文件夹的执行历史)
Agent的典型执行流程是:读取CLAUDE.md → 判断任务类型 → 确认是否需要调用Skill → 进入指定文件夹 → 读取_index.jsonl查看历史 → 执行任务并输出。每一步都明确且可追溯。
二、从零搭建:实战操作指南
2.1 入门阶段:30分钟快速启动
Step 1:安装和初始化
- 前往obsidian.md下载对应系统版本
- 双击安装,打开应用时选择一个本地文件夹作为Vault
- 建议路径:
~/Documents/GitHub/obsidian(放在Git目录便于版本管理)
Step 2:掌握7个核心功能
| 功能 | 说明 | 应用场景 |
|---|---|---|
| 双向链接 | 在笔记中写[[笔记名]]链接到另一篇笔记,被链接方自动显示反向引用 | 建立知识关联、追踪引用关系 |
| 知识图谱 | 所有双链可视化成节点-连线的网络图 | 发现知识盲区、识别孤立主题 |
| 笔记属性(YAML) | 笔记顶部的结构化元数据,比如author、date、status | 为AI提供笔记的第一印象、便于筛选和分类 |
| Daily Notes | 点击自动创建日期命名的笔记(2026-04-15.md) | 日志记录、日常工作追踪 |
| Templates | 快速复制某个文件框架到新文件 | 周复盘、选题、日报等重复结构 |
| Canvas | 内置白板工具,可画关系图、头脑风暴 | 概念设计、流程梳理 |
| Web Clipper | 官方浏览器扩展,一键保存网页到Vault | 内容采集、素材积累 |
Step 3:学习Markdown语法
Obsidian使用Markdown写作。以下是AI最关键的语法元素:
#→ 标题。h1是文章主题,h2是分论点,AI通过此理解文章结构- / 1.→ 列表。AI识别"这些是并列/有序要点"[[...]]→ 双链。AI理解"这个概念在系统里有专门文档"```→ 代码块。AI识别"这段是代码,不是正文"- Frontmatter → YAML元数据。AI读笔记时的第一印象
#tag→ 标签。用于分类和检索
Markdown不仅给人看,更是给AI的结构化指引。好的格式能直接提升AI的理解质量。
2.2 精通阶段:构建完整的AI操作系统
Step 1:设计你的文件夹模块地图
这是整个系统的骨架。设计原则:
- 序号+中文名:保证排序稳定且一眼可懂
- 每个文件夹有README.md:写清楚这里放什么、不放什么
- 深度不超过3层:太深的目录结构无论对人还是对AI都是负担
参考结构示例:
00_inbox/ # 收件箱(快速捕获) 01_content/ # 内容创作 └─ articles/ # 独立文章 └─ series/ # 专栏系列 02_topics/ # 选题库 03_references/ # 参考资料、摘要 04_resources/ # 工作资源、模板 05_tools/ # 工具脚本、插件说明 06_plans/ # 计划与目标 07_system/ # 系统方法、工作流 08_outputs/ # 交付物 09_images/ # 文章配图 10_about/ # 个人介绍、写作风格、审稿标准
Step 2:编写你的CLAUDE.md
这是Agent进入Vault的必读文件。结构参考:
# CLAUDE.md - Vault 使用指南 ## 项目概述 - 这是我的个人AI生产力系统 - 核心目标:[你的目标] - 主要场景:内容创作、知识管理、项目跟踪 ## 模块地图 - 00_inbox: 快速捕获想法和素材 - 01_content: 所有文章创作过程 - 03_references: 参考资料和知识库 - 06_plans: 年度目标、周计划、日志 - 10_about: 我的个人风格和偏好 ## 核心行为规则 1. JSONL文件只允许追加,绝不覆盖 2. 写文章前必须先读 10_about/writing_style.md 3. 创建新文件前确认应该放哪个子文件夹 4. 每个文件夹下的README是进入该区域的必读文件 5. 输出内容时,优先检查索引文件了解历史执行情况 ## 任务路由表 - 写文章任务: 1. 读 10_about/writing_style.md 2. 访问 02_topics 查看选题 3. 到 03_references 收集素材 4. 在 01_content/articles 创建草稿 5. 完成后追加记录到 articles_index.jsonl ## 关键索引位置 - daily_log.jsonl: 07_system/ - articles_index.jsonl: 01_content/ - goals_tracker.jsonl: 06_plans/
Step 3:建立索引文件(JSONL)
JSONL是纯文本格式的JSON行,每行一条记录。相比JSON和数据库,它的优势是:结构简单、追加成本低、AI操作稳定。
我的系统中跑着四个关键索引:
- daily_log.jsonl(07_system/)- 每日产出记录
{"date": "2026-04-15", "task": "写文章《Obsidian入门》", "status": "completed", "output_file": "01_content/articles/0415-obsidian.md"} - articles_index.jsonl(01_content/)- 独立文章索引
{"title": "从笔记应用到AI操作系统", "filename": "0415-obsidian.md", "status": "published", "date": "2026-04-15"} - goals_tracker.jsonl(06_plans/)- 年度目标进度
{"goal": "完成12篇深度文章", "progress": 8, "target": 12, "deadline": "2026-12-31"} - series_index.jsonl - 专栏进度索引
{"series": "AI生产力", "chapter": 4, "title": "Obsidian系统搭建", "status": "in_progress"}
关键规则:JSONL只追加、不覆盖。这条规则几乎是整个系统最重要的护栏,保证了数据的完整性和追踪的可靠性。
Step 4:沉淀你的个人上下文
AI懂不懂你,取决于你愿不愿意把自己的偏好、风格、历史记录下来。在10_about/文件夹下创建:
- 我的介绍.md - 身份、背景、当前角色、专业领域
- 写作风格.md - 语言偏好、文章结构、禁忌内容、常用表达
- 定位.md - 写什么、不写什么、目标读者是谁
- 审稿标准.md - 发布前要过哪些关、质量要求
- 性格特点.md - MBTI、决策倾向、沟通偏好
初看起来像在写简历,但一旦完成,AI的输出质量会有显著提升。因为它不再需要"了解你",而是直接参考这些文档就能精准输出。
Step 5:搭建你的核心工作闭环
一个完整的AI生产力系统,需要至少3个互相喂养的闭环:
闭环一:内容创作流
选题(02_topics) ↓ 收集素材(03_references) ↓ 起草文章(01_content/articles) ↓ 自审和修改 ↓ 发布 ↓ 归档 + 更新articles_index.jsonl
每一步都绑定到具体的文件夹或文件。AI看到"写文章"这个任务,就能自动沿着这条线走。
闭环二:知识管理流
信息来源(播客/文章/书) ↓ 消化(摘要、金句、观点提取) ↓ 分类存档到03_references ↓ 反哺到选题库 ↓ 用于内容创作
这个闭环的关键是"消化"环节——原始信息进来不能直接放着,必须经过一轮压缩和结构化,才能变成AI可检索的有效素材。
闭环三:周复盘流
每日记录追加到daily_log.jsonl ↓ 周末汇总周计划完成情况 ↓ 对比年度目标进度 ↓ 生成复盘报告 ↓ 制定下周规划
这个闭环让系统实现"自我跟踪"。每周末让AI自动读本周的daily_log.jsonl、对比02_plans中的周计划、计算goals_tracker.jsonl中的目标进度,自动生成复盘。
三、插件生态:让Obsidian真正运转起来
Obsidian生态中有2700+个社区插件。虽然看起来很多,但按"采集 → 整理 → 输出"三个阶段来选,每阶段2-3个就足够了。
3.1 采集层:把信息搬进Vault
AI生产力系统的第一个瓶颈不是"怎么写",而是"写什么"。没有素材,AI再强也是空转。
① Web Clipper(官方)
看到好文章,点一下浏览器扩展,整篇以Markdown存进Vault。保留标题、正文、链接、图片。
为什么这比书签强?因为存进Vault的内容是AI可以用grep检索的素材,而不是躺在收藏夹里永远不看的死链接。
② 微信读书插件
在插件社区搜索"weread"下载。一键同步微信读书的划线、笔记、书评到Vault,每本书一个文件。
价值:写文章时AI能直接搜你划过的关键段落,比从头搜互联网快得多,而且都是你精心筛选过的高质量内容。
③ RSS 订阅
关注播客字幕、技术博客、Newsletter的RSS源。设置自动拉取新内容,以笔记形式存到指定文件夹。
我的03_references/daily_podcasts/文件夹就是这样——AI每天自动从RSS拉字幕,整理成摘要等我消化。
3.2 整理层:把信息变成可查询的知识
① Dataview
用类SQL语法查询笔记库。例如:
列出所有status为"待写"的笔记,按优先级排序: TABLE priority, status FROM 02_topics WHERE status = "待写" SORT priority DESC
Dataview维护的结构化视图,反过来也指导AI的行为——AI看到这个看板就知道该优先处理什么。
② QuickAdd
解决"捕获一个想法要打开Obsidian → 找文件夹 → 新建文件"的摩擦。设置快捷键:
- Ctrl+Shift+A:新增选题到02_topics
- Ctrl+Shift+N:新增笔记到00_inbox
- Ctrl+Shift+L:新增日志条目
按一下,弹出输入框,回车完成。极大降低了信息捕获的摩擦。
3.3 输出层:把知识变成产品
① Kanban(看板视图)
把笔记集合可视化为看板。我用它管理文章创作进度:
[选题] [写作中] [待审] [已发布] 卡片1 卡片2 卡片3 卡片4 卡片5
Claude Code可以直接读取看板状态,知道每篇文章在哪个阶段,自动分配优先级。
② Excalidraw
在Obsidian里画手绘风格的流程图、架构图、概念图。完成后能嵌入笔记或导出图片。
坦白说我用得不多,因为大部分图我直接让AI生成。Excalidraw更适合需要精细手工调整的场景。
四、CLI:Obsidian真正的AI通道
让AI真正用起Obsidian的关键,是**CLI(命令行接口)**。Obsidian支持URI Scheme,即通过obsidian://协议直接操作。
常见的URI命令:
# 新建文件 obsidian://new?vault=obsidian&name=新笔记&content=内容 # 搜索 obsidian://search?vault=obsidian&query=上下文工程 # 打开特定文件 obsidian://open?vault=obsidian&file=01_content/articles/0415-obsidian.md
更关键的是,Agent可以直接执行这些命令,也可以用标准Unix工具操作本地文件:
- cat:读取文件内容
- grep:搜索关键词
- rg(ripgrep):快速全文搜索
- find:按条件查找文件
- sed/awk:文本处理
我的具体用法:
- AI起草完文章后,用CLI打开到创建的文件,我审稿前能快速定位
- Skill调用时返回Obsidian URL链接,点击跳转到对应的参考文档
- 写文章时让AI插入相关笔记的内部链接,读者点击能跳到我的原始笔记
- AI直接遍历整个Vault,用grep按需加载上下文
本地文件+本地CLI,是目前为止AI读写个人知识最低成本、最可控的方案。
五、多设备同步方案对比
Obsidian本身不提供云同步,需要借助第三方工具。选择标准是:数据量、费用、易用性。
| 方案 | 适合数据量 | 成本 | 易用性 | 优缺点 |
|---|---|---|---|---|
| 官方Obsidian Sync | 任意大小 | 10USD/月 | 极高 | 官方方案,加密同步。缺点是较贵 |
| iCloud | <50GB | 6元/月 | 高 | 适合小规模Vault,价格便宜。缺点是大容量贵 |
| Git(GitHub) | <10GB | 免费 | 中等 | 完全免费,版本控制完整。缺点是需要commit,不是实时同步 |
| NAS | >100GB | 一次性投入 | 低 | 完全掌控,无限存储。缺点是需要自己维护、搭建复杂 |
我的建议:
- 如果Vault <10GB且不需实时同步:用Git(GitHub),完全免费
- 如果追求开箱即用:用iCloud(一个月6块钱不贵)
- 如果优先级是安全和官方支持:用Obsidian Sync
- 如果数据量超大且有NAS:自己搭自动同步脚本
总结与反思
很多人现在还把Obsidian看作一个"高门槛的笔记应用",觉得它功能碎片化、学习曲线陡。但在我一年的实践中,我看到了完全不同的一面。
Obsidian的真实价值在于:
- 它是对AI最友好的个人知识系统。本地Markdown文件意味着Agent可以直接用CLI操作,没有API限制、没有第三方依赖。
- 它提供了完整的透明性。在Obsidian里,你能看到AI在读什么、输出什么、是否偏离了你的规则。这种可控性是使用其他AI工具无法获得的。
- 它是个人知识的长期沉淀载体。不像临时性的对话记录,Obsidian里的笔记、链接、索引会随着时间积累变得越来越有价值。
搭建一套完整的AI生产力系统听起来是大工程,但拆开来看就是五个步骤:
- 选一个Vault位置和同步方案
- 搭一套清晰的文件夹结构
- 写一份CLAUDE.md规则文档
- 沉淀你的个人上下文(写作风格、审稿标准等)
- 跑通一两个工作闭环
做完这五步,你就已经拥有一个"懂你"的AI助手了。它不是一个通用的ChatGPT,而是为你量身定制的生产力伙伴——既掌握你的知识库,又遵循你的工作规则,每次交互的质量都远高于一般的AI对话。
如果你正在寻找一个兼具灵活性、专业性和长期价值的个人AI系统,我建议从搭建Obsidian Vault开始。不需要一次性完成所有细节,而是先搭起基础框架,然后在实际使用中逐步迭代优化。三个月后回头看,你会发现这个系统对你的工作方式产生了深刻的影响。
我是一名产品经理,同时也是这个系统的设计者和使用者。这篇文章记录的是我从理论理解到实战操作的完整思考过程。欢迎你在构建自己的系统时参考这些方法,相信也能找到最适合自己的那个版本。