苏米注:MiniMax-M2.7 量化版发布后,Unsloth 团队第一时间推出了 22 个 GGUF 量化版本,从 1-bit 到 8-bit 全覆盖。最值得关注的是 4-bit 动态量化版只需要 108GB,一台 128GB 内存的 Mac 就能跑。今天我来详细拆解本地部署的完整指南。
一、为什么选 Unsloth 量化
Benjamin Marie 对 MiniMax-M2.5(M2.7 同架构)进行了 750 个 prompt 的混合测试,对比各种量化版本的表现。
关键结论:
- UD-Q4_K_XL:准确率比原始模型只下降 6.0 分,错误增加率仅 +22.8%,是质量/体积性价比最高的版本
- 其他 Unsloth Q4 量化(IQ4_NL、MXFP4_MOE、UD-IQ2_XXS)表现接近,准确率 ~64.5–64.9
- Unsloth 量化全面优于非 Unsloth 量化,尽管体积还小了约 8GB
苏米注:为什么 Unsloth 的量化这么强?因为他们用了 Dynamic 2.0 技术——对每一层进行智能化的差异化量化,关键层保留更高精度(8-bit 甚至 16-bit),不重要的层用低精度,配合超过 150 万 token 的高质量校准数据集。
简单说,传统量化是一刀切,Unsloth 是精准手术刀。
二、22 个版本怎么选
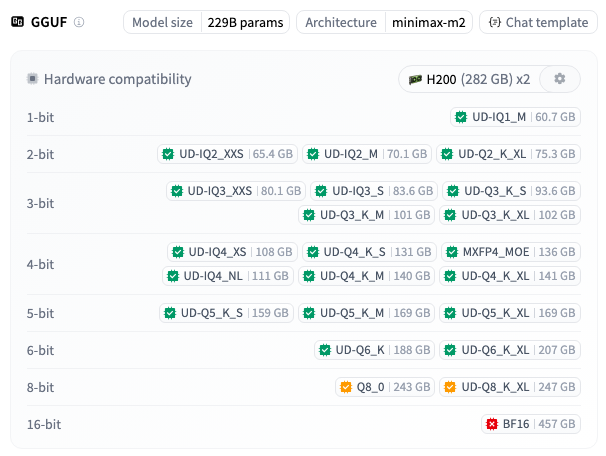
Unsloth 提供了从极致压缩到接近无损的完整量化矩阵:
我的推荐优先级:
| 设备配置 | 推荐版本 | 预期性能 |
|---|---|---|
| 128GB Mac | UD-IQ4_XS(108GB) | 15+ tokens/s |
| 追求最佳质量 | UD-Q4_K_XL(~130GB) | 准确率损失最小 |
| 256GB Mac / 多卡用户 | Q8_0(243GB) | 接近满血,15+ tokens/s |
| 96GB 设备 | UD-Q2_K_XL 或 UD-IQ3_S | 有压缩但还能用 |
| 1×16GB GPU + 96GB RAM | UD-IQ4_XS | GPU-CPU 混合推理,25+ tokens/s |
三、部署方式一:Unsloth Studio(最简单)
Unsloth 最近发布了自己的推理 UI——Unsloth Studio,一行命令安装,内置模型搜索、下载、对话,支持 macOS / Windows / Linux。
安装命令
# macOS / Linux / WSL
curl -fsSL https://unsloth.ai/install.sh | sh
# Windows PowerShell
irm https://unsloth.ai/install.ps1 | iex启动
unsloth studio -H 0.0.0.0 -p 8888打开浏览器访问 http://localhost:8888,首次会要求设置密码。
进入 Studio 后,在 Chat 标签页搜索 MiniMax-M2.7,选择想要的量化版本(如 UD-IQ4_XS),点击下载。下载完成后就可以直接开聊,推理参数会自动设置。
苏米注:这是目前门槛最低的方式,适合想快速体验的朋友。
四、部署方式二:llama.cpp(灵活可控)
如果你更喜欢命令行,或者需要更细粒度的控制,llama.cpp 是最佳选择。
第一步:编译 llama.cpp
# 安装依赖(Ubuntu/Debian)
apt-get update
apt-get install pciutils build-essential cmake curl libcurl4-openssl-dev -y
# 克隆仓库
git clone https://github.com/ggml-org/llama.cpp
# 编译(有 NVIDIA GPU)
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON
# 编译(Mac / 无 GPU)—— Metal 默认开启
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=OFF
# 构建
cmake --build llama.cpp/build --config Release -j \
--clean-first \
--target llama-cli llama-mtmd-cli llama-server llama-gguf-split
cp llama.cpp/build/bin/llama-* llama.cpp踩坑记录:Mac 用户设置 -DGGML_CUDA=OFF 即可,Metal 加速是默认开启的。
第二步:下载模型
方式 A:直接用 llama.cpp 内置下载(最简单)
export LLAMA_CACHE="unsloth/MiniMax-M2.7-GGUF"
./llama.cpp/llama-cli \
-hf unsloth/MiniMax-M2.7-GGUF:UD-IQ4_XS \
--temp 1.0 \
--top-p 0.95 \
--top-k 40这条命令会自动下载 UD-IQ4_XS 量化版并启动交互对话。:UD-IQ4_XS 就是量化类型的选择器。
方式 B:用 huggingface_hub 手动下载
pip install huggingface_hub hf_transfer
hf download unsloth/MiniMax-M2.7-GGUF \
--local-dir unsloth/MiniMax-M2.7-GGUF \
--include "*UD-IQ4_XS*"如果想下 8-bit 版本,把 *UD-IQ4_XS* 换成 *Q8_0*。
第三步:运行交互对话
./llama.cpp/llama-cli \
--model unsloth/MiniMax-M2.7-GGUF/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00001-of-00004.gguf \
--temp 1.0 \
--top-p 0.95 \
--top-k 40苏米注:推荐的推理参数是 MiniMax 官方建议的:temperature=1.0、top_p=0.95、top_k=40。
默认系统提示词:You are a helpful assistant. Your name is MiniMax-M2.7 and is built by MiniMax.
性能调优小技巧
--threads 32:CPU 线程数,根据 CPU 核心数调整--ctx-size 16384:上下文长度,最大支持 196,608(200K)--n-gpu-layers 2:GPU 卸载层数,显存不够就调小,纯 CPU 就去掉这个参数
五、部署方式三:API 服务
如果你要在项目中调用,用 llama-server 部署为 OpenAI 兼容 API 是最佳方案。
启动服务
./llama.cpp/llama-server \
--model unsloth/MiniMax-M2.7-GGUF/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00001-of-00004.gguf \
--alias "unsloth/MiniMax-M2.7" \
--prio 3 \
--temp 1.0 \
--top-p 0.95 \
--min-p 0.01 \
--top-k 40 \
--port 8001
Python 调用示例
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8001/v1",
api_key="sk-no-key-required",
)
completion = client.chat.completions.create(
model="unsloth/MiniMax-M2.7",
messages=[
{"role": "user", "content": "写一个贪吃蛇游戏"}
],
)
print(completion.choices[0].message.content)苏米注:完全兼容 OpenAI SDK,现有代码几乎不用改,换个 base_url 就能从 GPT 切到本地 M2.7。
六、MLX 版本:Mac 原生方案
除了 Unsloth 的 GGUF,MLX 社区也发布了 Apple Silicon 原生的 4-bit 量化版:mlx-community/MiniMax-M2.7-4bit
MLX 是 Apple 的机器学习框架,专为 M 系列芯片优化。
使用方式
pip install mlx-lm
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/MiniMax-M2.7-4bit")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True, return_dict=False,
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)MLX 版本的优势是与 Apple Silicon 深度集成,内存管理更高效。不过目前它的量化方案不如 Unsloth Dynamic 2.0 精细(标准 4-bit 量化,没有层级差异化处理),模型大小约 120GB。
最佳实践:Mac 用户建议优先试 Unsloth 的 GGUF + llama.cpp 方案,Metal 加速默认开启,性能和质量都更有保障。
七、重要提醒(踩坑必看)
1. 不要使用 CUDA 13.2
Unsloth 特别强调:Do NOT use CUDA 13.2 to run GGUFs
这个版本的 CUDA 可能会导致输出乱码或质量严重下降。如果用 NVIDIA GPU,请检查 CUDA 版本,确保不是 13.2。
2. 内存要大于模型文件
确保总可用内存(显存 + 系统内存)大于量化模型文件的大小。如果不够,llama.cpp 会自动回退到硬盘卸载(SSD/HDD offloading),推理速度会大幅下降。
3. 推理参数要设对
MiniMax 官方推荐的参数组合:
- temperature=1.0
- top_p=0.95
- top_k=40
用错参数可能导致输出质量明显下降。
4. 最大上下文长度 196,608
M2.7 支持 200K 上下文窗口,但在量化版本上跑满上下文需要更多内存。建议从 --ctx-size 16384 开始,根据实际需求逐步调大。
八、技术详解:Unsloth Dynamic 2.0
传统的 GGUF 量化(如 imatrix)对所有层使用相同的量化精度。但模型中不同层的重要性差异很大——注意力层、FFN 的前几层通常比中间层更关键。
Unsloth Dynamic 2.0 的核心思路:
- 逐层差异化量化:对每一层单独决定量化精度,关键层保留 8-bit 甚至 16-bit,其他层用低精度
- 模型专属方案:每个模型的量化配置都不同,Gemma 3 的关键层和 MiniMax M2.7 的关键层位置完全不同
- 高质量校准数据:使用超过 150 万 token 的手工策划数据集(包含对话格式),传统校准集只用 Wikipedia 文本
- MoE 专项优化:对 MoE 架构的专家层做特殊处理,MXFP4_MOE 就是专门针对 MoE 结构优化的格式
苏米注:效果上,Unsloth 的 KL 散度(衡量量化与原始模型差异的黄金标准)全面优于标准 imatrix 量化,而且文件体积还小了约 8GB。
九、总结
MiniMax-M2.7 的量化版来得很快,Unsloth 团队再次展现了速度和质量。
核心建议:
| 需求 | 推荐方案 |
|---|---|
| 只选一个版本 | UD-Q4_K_XL,Unsloth 推荐,质量损失最小 |
| 128GB Mac | UD-IQ4_XS(108GB),稳定运行 15+ tokens/s |
| 256GB 设备 | Q8_0(243GB),接近满血体验 |
| 最简单的方式 | Unsloth Studio,一行命令安装,图形界面操作 |
| Mac 原生体验 | MLX 4-bit,Apple Silicon 优化,pip install 即用 |
230B 参数的顶级开源模型,压缩到 108GB 就能在一台笔记本上跑,这在一年前是不可想象的。