DeepSeek Agent 的推理过程、工具调用和文件改动都在命令行中运行。信息都在,但盯着黑框看久了,眼睛和脑子都容易累。
最近在 GitHub 上发现一个项目 DeepSeek-GUI,已经有 1300+ Star。它把 DeepSeek TUI (Kun) 的 Agent 体验搬进了桌面窗口,降低了上手门槛。
苏米注:这不是 DeepSeek 官方项目,而是个人开发者对 Kun 运行时做的 GUI 封装。但正是这类社区工具,让 AI Agent 真正走向了更广泛的用户群体。
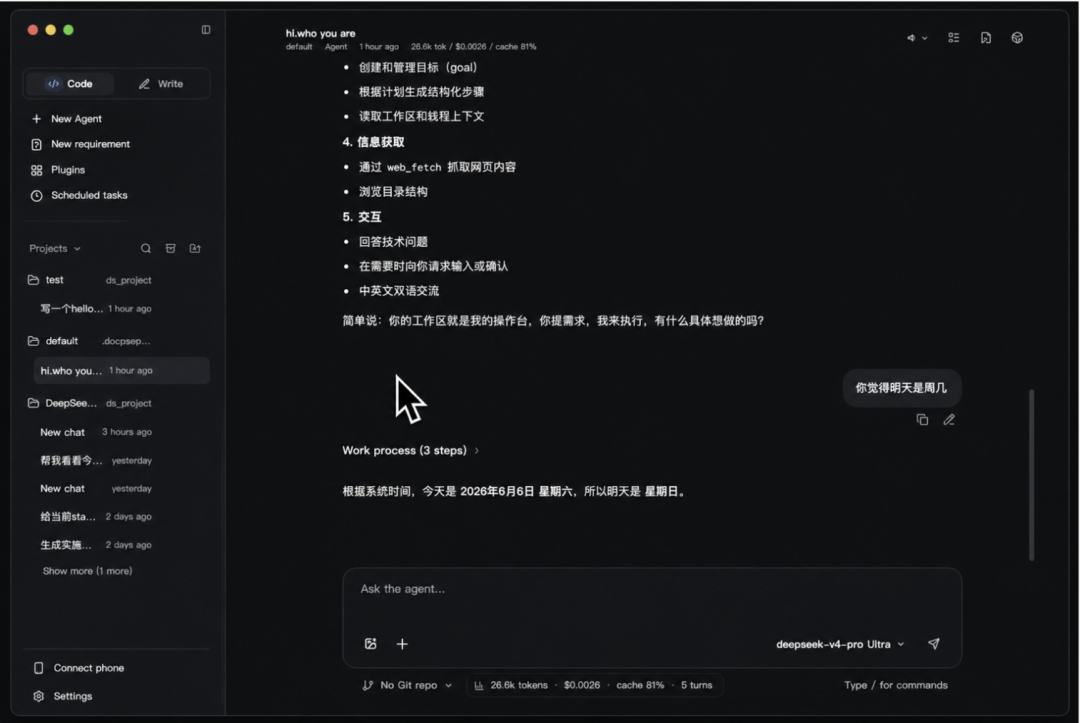
三种工作模式,覆盖不同场景
Code 模式:项目开发主战场
按项目目录组织多个代理会话,实时查看推理过程、工具调用和文件变化。
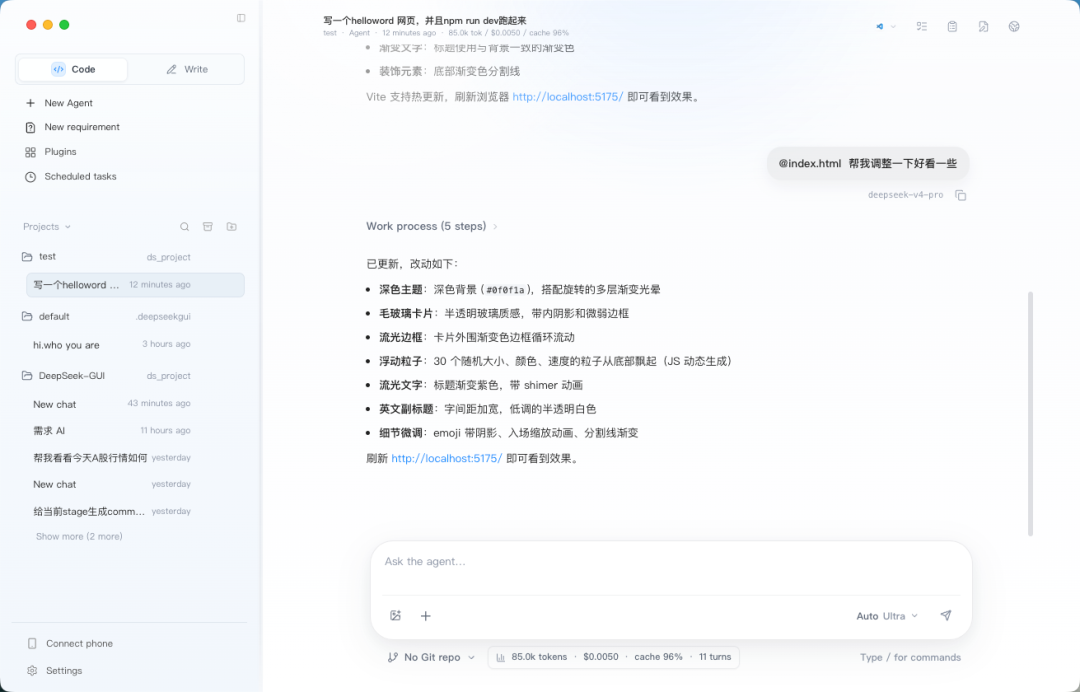
三个核心功能值得关注:
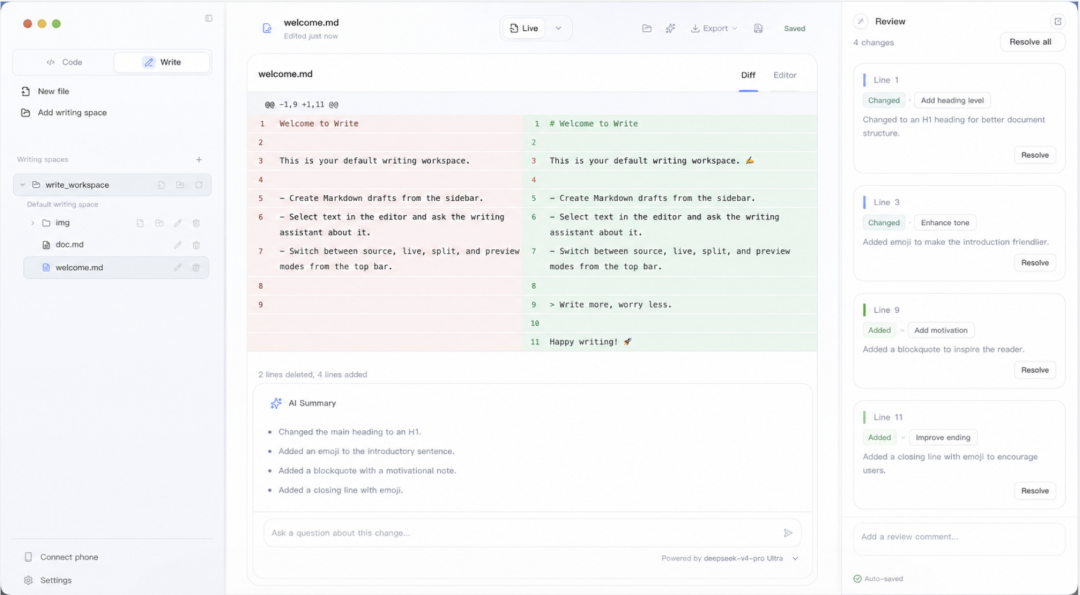
- 变更审核:内联 diff 和侧边审查面板记录每一处文件改动,直接在应用内完成 review。比在终端查看 diff 直观很多。
- 权限控制:提供只读、工作区可写、完全访问三个层次,可设置工具调用前是否需要人工审批。
- 需求规划:先写需求草稿让 AI 帮忙澄清,再生成实施计划。
/plan命令创建可编辑的计划文件,右侧面板同步线程 Todo。
Write 模式:文档写作独立空间
左侧文件树支持新建、重命名与删除。中间是 Live 编辑器——当前行保留 Markdown 源码,其余行实时渲染。
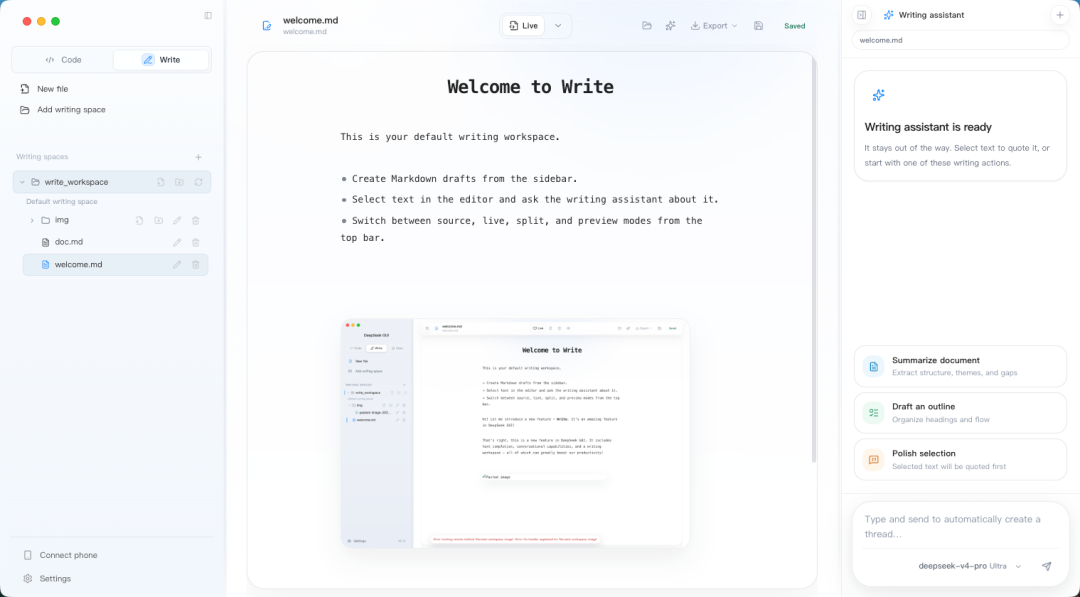
文本补全设计分两种:短补全响应速度快、数量少,适合实时输入辅助;灵感长补全停顿时间长、量大,适合接住写作灵感。右侧还有写作助手,支持摘要、大纲、润色等功能。
Claw 模式:连接手机与 IM 的入口
可以给飞书、Lark、微信配置独立的 Agent,设置不同角色、默认模型和工作目录。
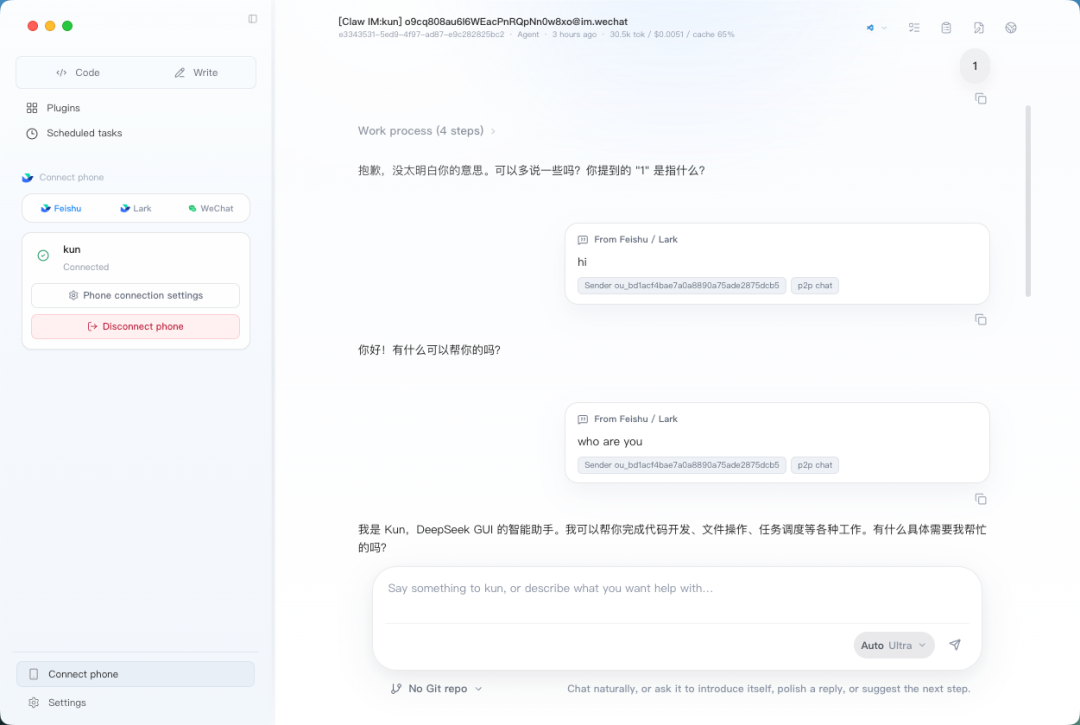
可以在手机上用飞书让 AI 在电脑上新建文件、删除文件、打开 Chrome 搜索,基本上都是秒执行。
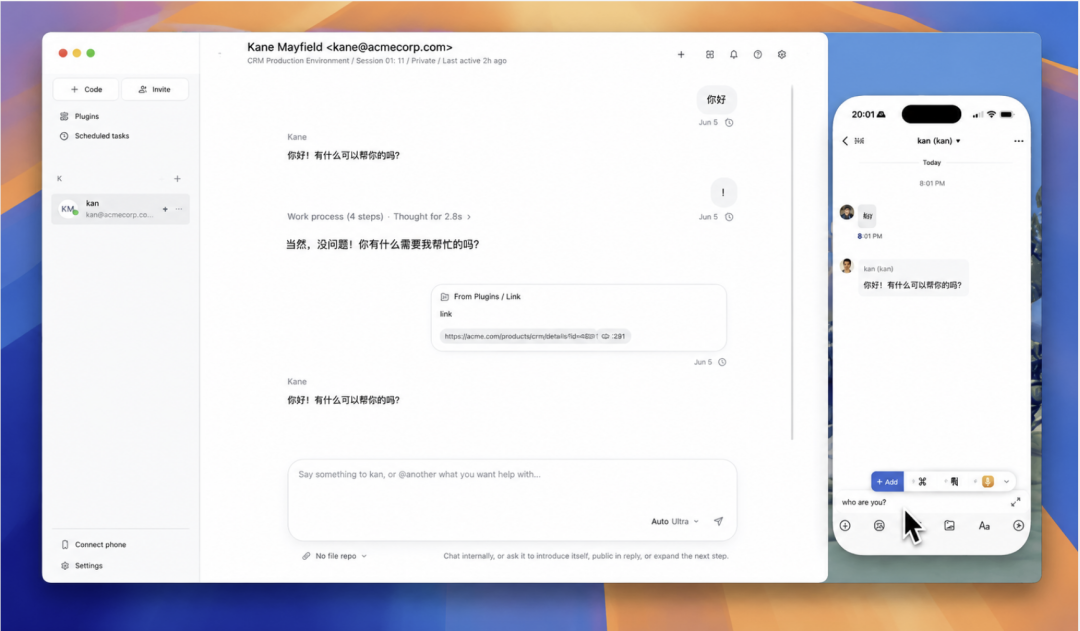
此外还支持定时任务,可创建一次性、每天、间隔或手动任务。人在外面,一句话让家里电脑干活。
底层技术:Kun 运行时的设计亮点
Kun 运行时借鉴了 Reasonix 的 cache-first agent loop 设计理念:
- 能缓存的尽量缓存,日志只追加不修改
- 系统提示词和工具 Schema 基本保持不变,更容易命中 DeepSeek 的缓存
- 统一管理缓存,重复内容不用重新计算,Token 消耗自然降低
跑任务时可以直接看到缓存命中率和 Token 使用量,省了多少成本一目了然。
苏米注:cache-first 的思路很值得学习——通过减少重复计算来降低成本,而不是单纯依赖更便宜的模型。这对长期运行 Agent 的用户来说,成本差异可能很显著。
上手体验
到 GitHub Releases 或官网下载安装包,macOS、Windows、Linux 都有对应版本。
第一次启动会提示选择语言、输入 API Key、选择默认工作目录。建议从 Code 模式开始,选择一个正在做的项目目录,给一个简单任务(比如"帮我整理项目目录结构"),观察 AI 如何分步骤解决问题。
当前局限性
客观来说,有几个需要注意的点:
- 仅支持 DeepSeek API:其他模型暂时不能用
- 非官方项目:稳定性、后续更新、数据安全需要自行评估
- 偶发卡顿:实测中出现过一两次卡顿,重启后恢复
- 反爬限制:让 AI 读百度搜索结果时,有时会被反爬机制挡住
总结
如果想在本地使用 DeepSeek + Agent 但不想接触命令行,DeepSeek-GUI 是个低门槛的入口。推理过程、工具调用、文件修改都在同一界面中呈现,审批和回退也更直观。
项目基于 MIT 协议开源,感兴趣可以到 GitHub 仓库查看源码和文档。
苏米观察:DeepSeek 生态正在快速扩展——从模型本身到周边工具再到应用层封装,整个链条都在加速。AI 的下半场,比拼的不是语言的华丽,而是用更低的成本实现更高的效率。