阿里巴巴正式发布 Qwen3.7-Plus——将视觉与语言统一为一体化智能体基座的多模态模型。
在 Qwen3.7 强大文本能力的基础上,Qwen3.7-Plus 全面升级了视觉-语言能力,同时保持了在编码、工具使用和生产力工作流方面的完整智能体能力。
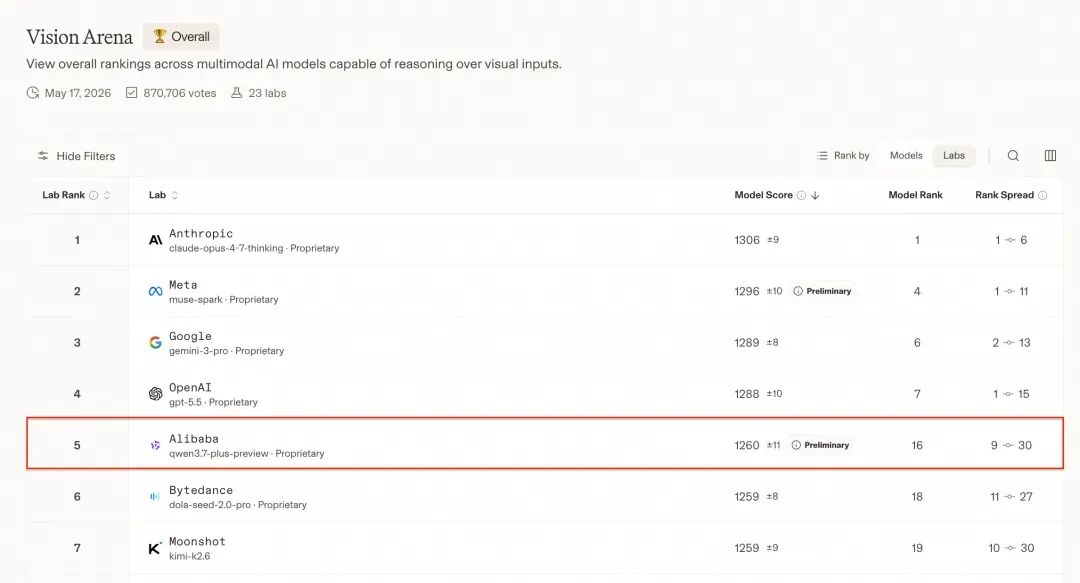
在全球权威视觉模型榜单 Vision Arena 中,凭借 Qwen3.7-Plus,阿里跻身全球前五、中国第一。
五大核心能力
Qwen3.7-Plus 的核心特色在于其作为多模态交互混合智能体的能力。它能够感知真实世界场景、读取屏幕并操作 GUI、基于视觉参考生成代码、端到端导航移动应用,以及基于网络知识回答视觉问题。
- Multimodal Agent:统一处理图像、视频、屏幕、网页和文本输入,在 GUI / CLI / 工具环境中完成任务
- Visual Agent:结合视觉理解、代码解释器和搜索增强,解决视觉谜题、真实世界问答和复杂推理任务
- Visual Coding:从图像或视频生成 SVG、网页和交互式前端,实现视觉参考到代码的端到端转化
- GUI Agent:理解移动端和桌面端界面,进行控件定位、任务规划和多步操作
- Real-world Perception & Reasoning:覆盖真实场景、文档图表、OCR、视频和驾驶场景理解
模型表现
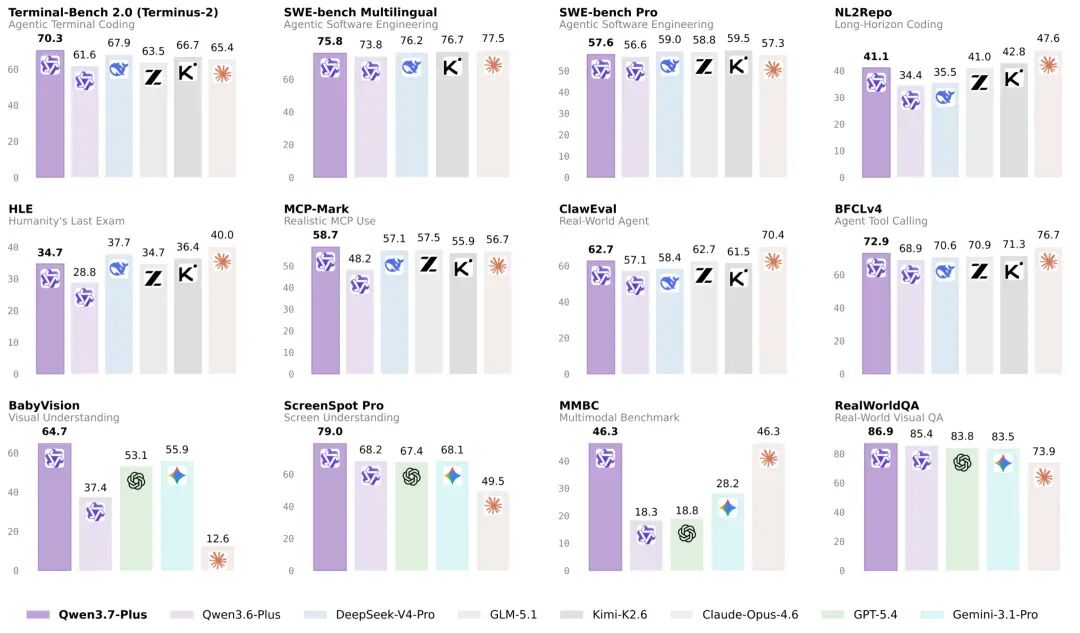
纯文本能力
Qwen3.7-Plus 在纯文本能力上表现出色,整体接近 Max 级别模型。

- 编码 Agent:在 Terminal Bench 2.0、SWE-bench 系列和 SciCode 上表现强劲,能够有效处理真实软件工程和科学编程任务
- 通用 Agent:在 MCP-Mark、Deep-Planning 和 Kernel Bench L3 上展现了稳健的工具使用与规划能力
- 推理能力:在 GPQA Diamond、HMMT 和 IMOAnswerBench 上表现优异,在高难度 STEM 基准测试中位于 Plus 级别模型前列
- 指令遵循与多语言:在 IFBench、WMT24++ 和 PolyMATH 上保持了稳定的高质量表现
多模态能力
Qwen3.7-Plus 的多模态能力提升,不仅是单点视觉理解能力的优化,而是围绕多模态智能体所需的关键能力系统性增强。
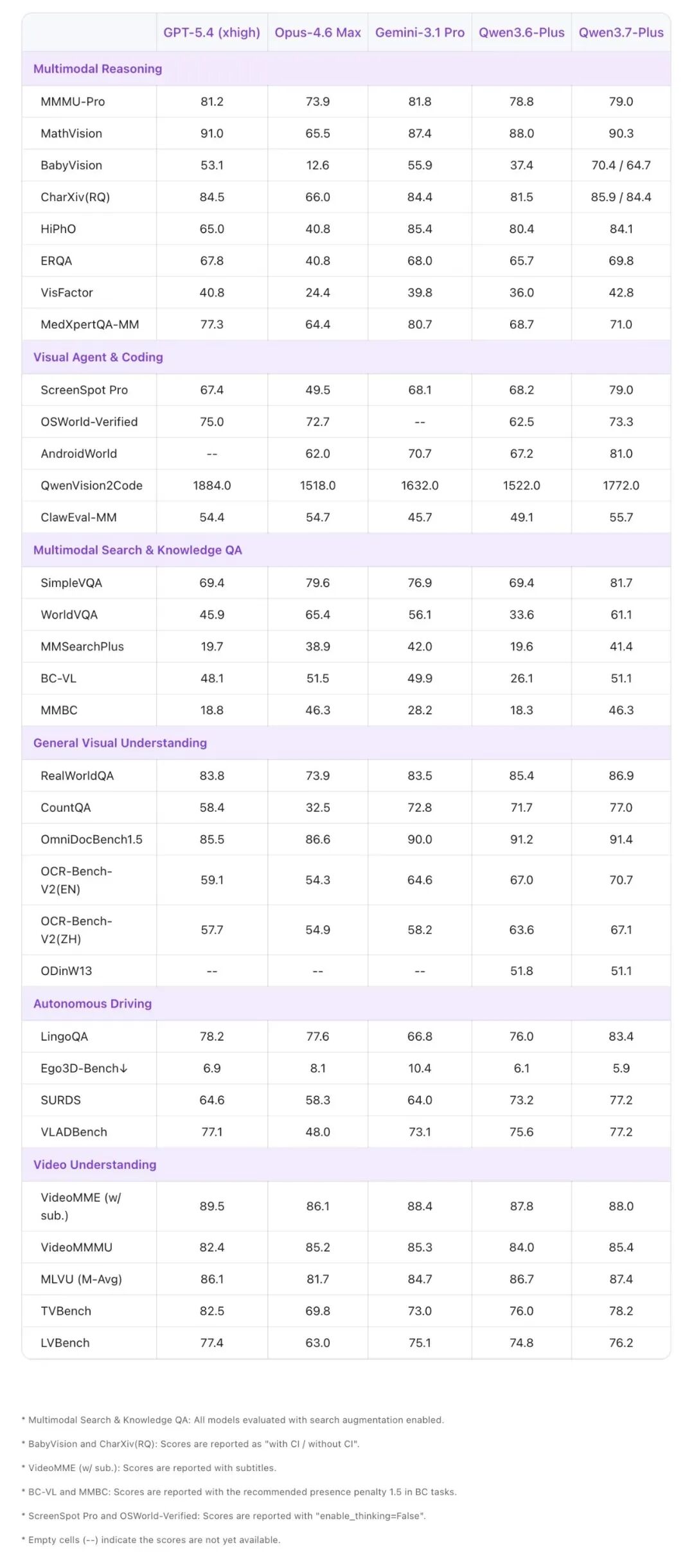
- Multimodal Reasoning:在 BabyVision、MathVision、HiPhO、ERQA 和 VisFactor 等高难度视觉推理基准上取得强表现,尤其在 BabyVision 上相比 Qwen3.6-Plus 有显著提升
- Visual Agent & Coding:在 ScreenSpot Pro、OSWorld-Verified 和 AndroidWorld 上显著提升,不仅能够识别屏幕内容,还能够定位关键 UI 元素并完成多步交互操作
- Multimodal Search & Knowledge QA:在 SimpleVQA、WorldVQA、MMSearchPlus 等任务上明显增强,可以将视觉输入与外部知识检索结合起来
- General Visual Understanding:在 RealWorldQA、CountQA、OmniDocBench、OCR-Bench-V2 等任务上保持强表现
- 视频与驾驶场景:在 VideoMMMU、MLVU、TVBench 等视频任务上能够处理短视频和长视频中的事件、动作、时序和语义关系
案例展示
多模态交互混合智能体
基于 Qwen3.7-Plus 构建的 Hybrid-Agent 智能体系统,将大模型的代码生成能力与 GUI 自动化执行深度融合。
APP 全链路开发:Agent 持续稳定运行 11+ 小时,全程自动完成了一款英语单词学习 APP 的完整研发闭环。累计生成代码超过 10,000+ 行,触发 Agent 调用超过 1,000+ 次,覆盖需求文档生成、代码自动编写、自动化安装部署、测试用例创建、GUI 自动化测试等全生命周期环节。
桌面端专业应用复刻:Agent 全程自主完成了 macOS 原生 Stocks(股市)应用的高保真复刻——自主交互原生应用并理解 UI 布局与功能细节,基于交互记录自动生成 SwiftUI 源码,接入 LongBridge 真实行情 API 获取实时市场数据,自动编译构建并启动复刻应用,最终自主执行 10 项功能验证测试全部通过。
视觉 Agent
Qwen3.7-Plus 可以作为强大的视觉 Agent,将视觉理解与工具使用相结合来解决复杂的视觉任务。通过代码解释器集成,它可以分析图像来找不同、补图块、解华容道、走迷宫、拼拼图——全程通过自主生成和执行代码完成。
结合搜索增强,它能够基于网络知识对真实世界的视觉问题进行多模态推理和回答,支持单图、多图和视频输入。
视觉编程
Qwen3.7-Plus 展现了强大的视觉到代码生成能力。它可以将图像、视频、UI 截图和设计参考转化为可执行代码。

在图像/视频转 SVG 任务中,模型需要理解视觉内容中的几何结构、颜色、布局、层级关系和动态变化,并将这些视觉元素用代码形式精确表达。
在视觉驱动的网页设计中,Qwen3.7-Plus 可以基于视觉参考、视频素材或设计意图生成完整交互式网页,从"给一张参考图"到"生成一个可运行的网页原型"。
浏览器智能助手
基于 Qwen3.7-Plus 构建了浏览器智能助手(Qwen for Chrome 插件)。在该模式下,Qwen 能够感知当前网页内容、理解用户任务、规划操作步骤,并以 Browser Agent 的形式在真实浏览器环境中执行点击、输入、跳转、配置和验证等操作。
面对非科班用户"采购一台最便宜 ECS 服务器"的需求,Agent 能够直接进入云控制台,完成实例规格比价、低成本选型、镜像与存储配置、安全组设置、订单确认等完整操作。
相关链接
- 官方技术博客:qwen.ai/blog
- 阿里云百炼:bailian.console.aliyun.com
- Qwen Studio:chat.qwen.ai
总结:Qwen3.7-Plus 是目前最强的多模态智能体模型之一,将视觉理解与语言推理统一为一体化的智能体基座。它作为多模态交互混合智能体运行——感知真实世界场景、操作图形界面、基于视觉参考编写代码,并在 GUI 与 CLI 环境中端到端完成任务。对于需要多模态能力的开发者和企业来说,这是一个值得重点关注的模型。