MiniCPM5-1B:1B 参数的端侧基座模型,AA 榜单 2B 以下最强
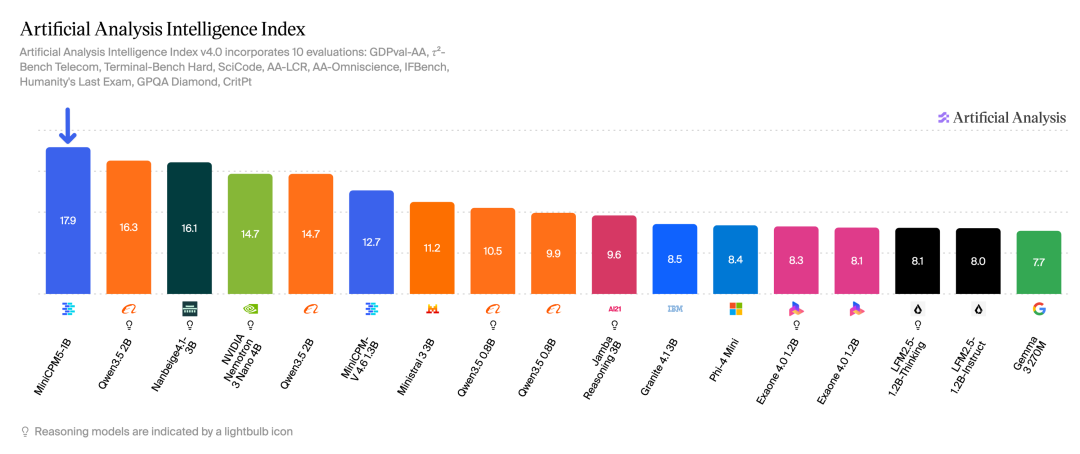
5 月 25 日至 29 日,面壁智能与 OpenBMB 联合举办「端侧大模型开源周」,每天发布一个端侧大模型的关键能力。第二弹推出的 MiniCPM5-1B 是由面壁智能联合清华大学、OpenBMB 开源社区发布的新一代端侧文本基座大模型,仅 1B 参数规模,在 Artificial Analysis Intelligence Index(AA-Index)上超越了所有 2B 参数以下的模型,得分 17.9 分位列小尺寸模型第一。
相比 3 个月前发布的 Qwen3.5-2B,MiniCPM5-1B 效果更优,参数量减少一半。这一结果验证了智能密度定律:大模型的智能密度正以约每 3.5 个月翻一番的速度持续提升。
1B 参数能做什么:AI 桌宠
MiniCPM5-1B 的一个典型应用是「AI 桌宠」——跑在手机、电脑或浏览器里的轻量级 AI 陪伴应用。项目基于 clawd-on-desk 二次开发,GitHub 地址:OpenBMB/MiniCPM-Desk-Pet。
部署成本几乎可以忽略:不需要 GPU 集群,不需要云端 API,一台普通笔记本、一部手机、甚至一个浏览器标签页就能运行。INT4 量化后权重仅 0.5GB,断网也能跑。
苏米注:端侧 AI 的核心价值不是把云端大模型打折后塞进小设备,而是让适配端侧环境的小尺寸模型本身就足够强,强到能独立驱动真实应用。MiniCPM5-1B 正是这个方向的最新验证。
评测表现:全面超越同尺寸模型
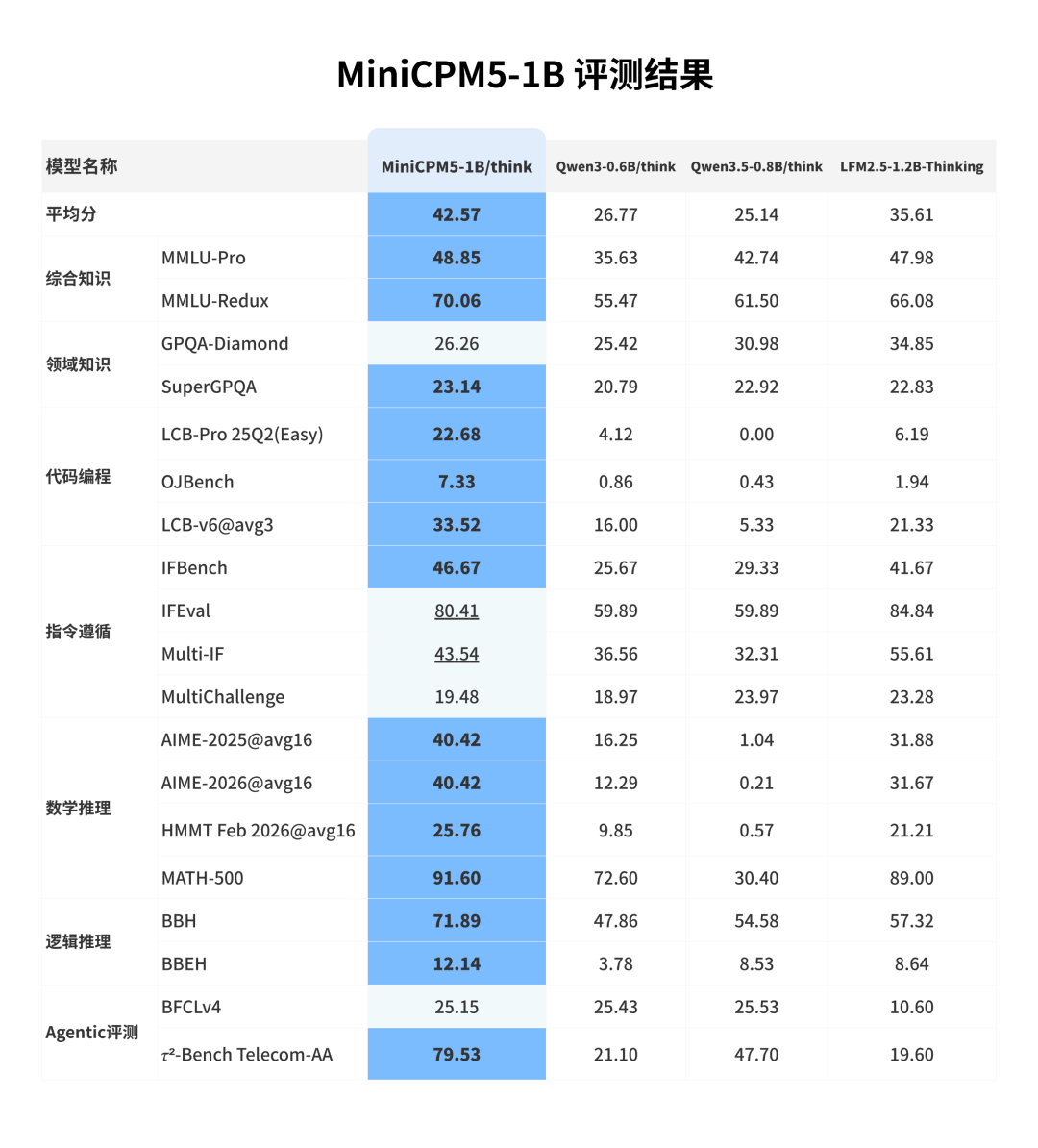
在综合知识、数学推理、代码推理、工具调用等维度上,MiniCPM5-1B 全面超越 Qwen3.5-0.8B、LFM2.5-1.2B-Thinking 等同尺寸基座模型。这不是某个单项上的微弱领先,而是全面、系统性的超越。
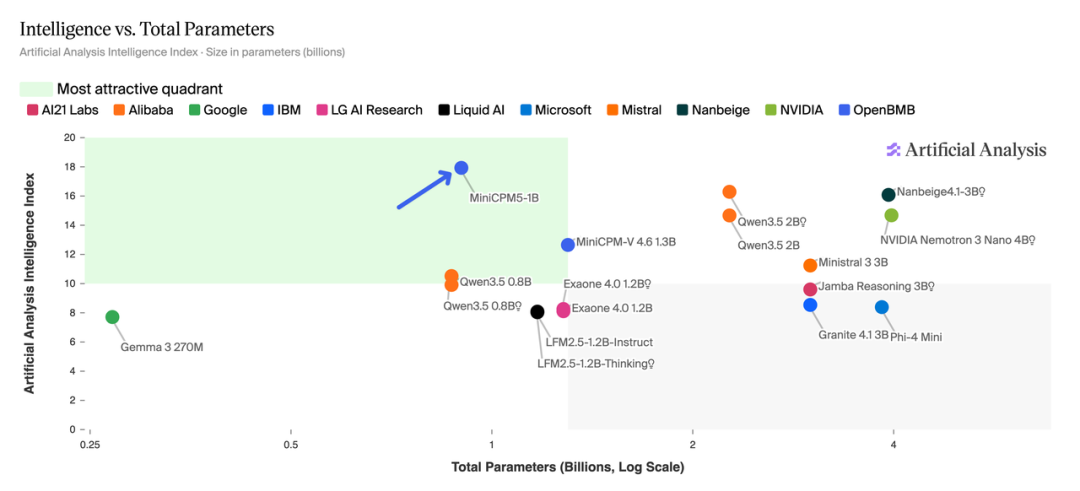
在 AA 榜单的散点图中,MiniCPM5-1B 位于「最具吸引力象限」——高智能指数、低参数量,参数效率显著优于同级模型。
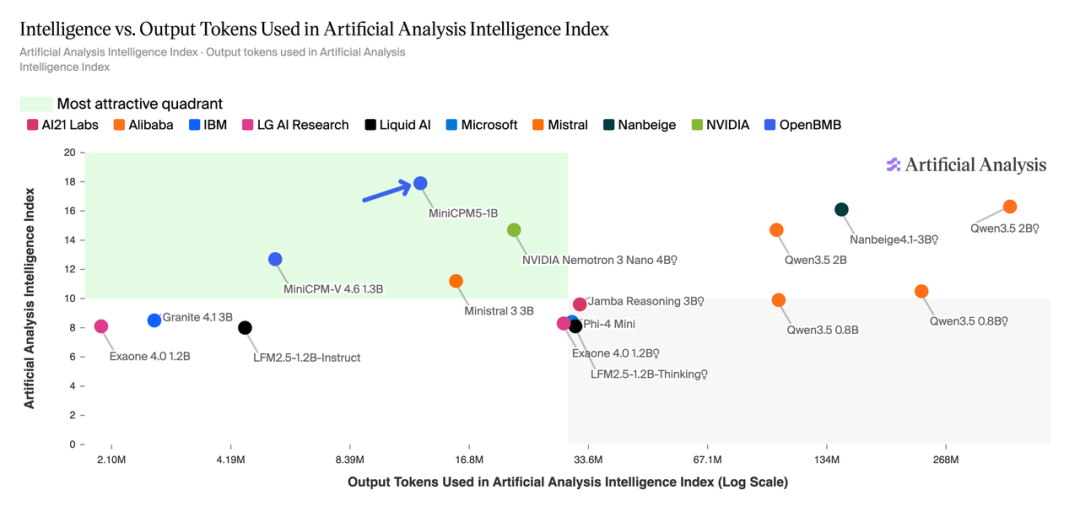
另一张散点图展示了智能指数与输出令牌消耗量的关系,MiniCPM5-1B 同样位于高效率区域。
数据治理:高智能密度的关键
1B 模型要达到出色性能,训练数据的质量比参数量更重要。MiniCPM5-1B 在训练中构建了分级数据治理体系,将预训练数据按质量划分为 L0 至 L4 五个等级,每级对应不同的清洗、筛选和质量控制标准。
研究团队针对三个关键语料方向开展了大规模高质量数据合成:
- 高知识密度中文网页语料
- 高知识密度英文网页语料
- 高质量数学合成语料
核心理念是:与其用海量低质数据灌出一个模型,不如用精选高密度数据养出一个模型。高质量合成数据集 Ultra-FineWeb-L3 将随模型一起开源。技术报告:arxiv.org/pdf/2602.09003。
ForgeTrain:AI 编写的训练框架
MiniCPM5-1B 的 Base Model 版本由面壁智能自主研发的 AI 训练框架 ForgeTrain 在华为昇腾上预训练完成。ForgeTrain 是全球首个完全由 AI 编写的生产级大模型训练框架,零人类程序员参与编写框架代码。
在英伟达 H100 上,ForgeTrain 的训练速度比英伟达 Megatron 框架快 10%,相当于训练成本下降 10%。这组数据进一步验证了「AI 制造 AI」的路径可行性——一个完全由 AI 编写的训练框架,能够训练出全球同尺寸最优的基座模型。
端侧部署:0.5GB 跑满全平台
MiniCPM5-1B 的部署门槛极低,覆盖从服务器到手机的全场景:

- 有 GPU:直接跑 FP16,性能拉满,权重约 2GB
- 只有 CPU:面壁智能联合清华大学、OpenBMB 开源了自研 CPU 推理框架 ArcLight,专门为纯 CPU 环境做了深度优化
- 浏览器运行:可直接在浏览器中运行,零安装、零配置
苏米注:INT4 量化后仅 0.5GB,比一部短视频还小。这意味着普通用户的手机就能本地运行一个能力出色的文本大模型,不需要任何云端依赖。
开发者友好:一行代码唤醒桌宠
MiniCPM5-1B 从设计之初就围绕开发者友好来设计:
- 主流微调框架全覆盖:支持 Llama_factory、ms_swift
- 推理框架适配:SGLang、vLLM、llama.cpp、ollama、Hugging Face、ArcLight
- 安装 Skills:如果使用 Claude Code 或类似 AI 编程工具,可以直接让 AI 帮你完成环境配置和部署
开源地址
- HuggingFace:openbmb/MiniCPM5-1B
- GitHub:OpenBMB/MiniCPM
- ModelScope:MiniCPM5-1B
- GitCode:MiniCPM5-1B
- 魔乐社区:MiniCPM5-1B