为什么你的 AI Agent 总是不听话?
做 AI Agent 开发的人大概都经历过这种场景:Agent 跑偏了,于是跑到 Skill 文件里加一句「别这么做」。结果格式不对,又补一句「输出应该长什么样」。改着改着,Skill 文件越来越长,Agent 却越来越笨。
问题可能不在模型够不够聪明,而在 Skill 写得够不够好。
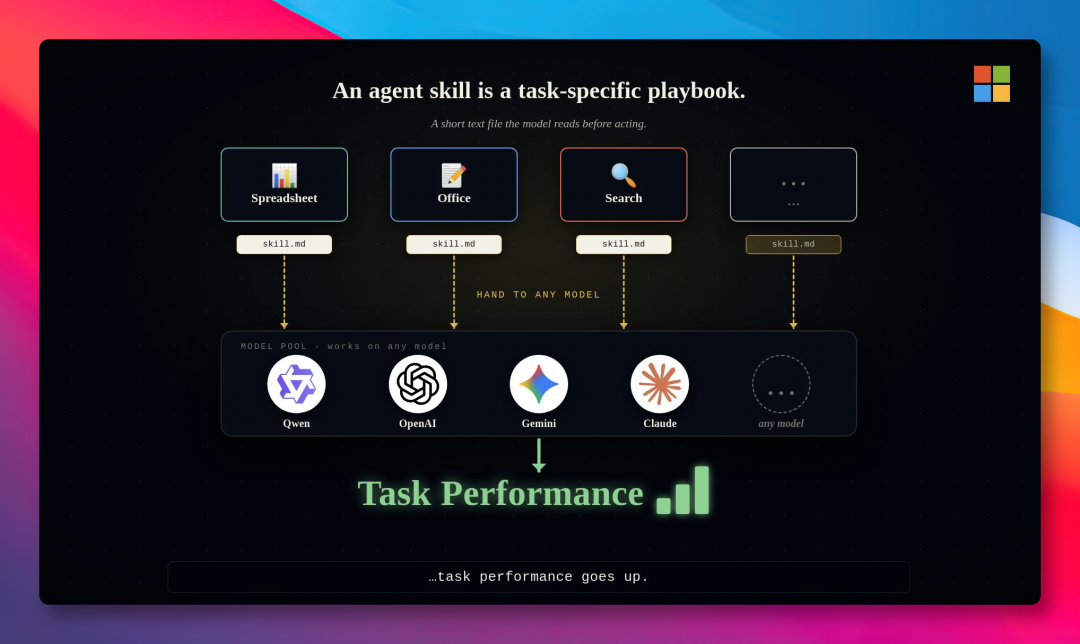
微软最近开源的 SkillOpt,提供了一条全新的解决思路——把 Skill 本身变成一个能自动优化、反复迭代的东西。

SkillOpt 的工作原理
SkillOpt 的核心设计是让两个模型搭班子协作:
- 执行模型:按照当前 Skill 完成一批任务,记录哪些做成了、哪些搞砸了
- 优化模型:复盘执行结果,成功则吸取经验,失败则寻找规律,判断是否在同一个地方反复出错
复盘完成后,优化模型开始动手修改 Skill 文件——增删内容或调整描述。但每次改动都有严格限制,只允许小改几处(论文测试表明控制在 4 处左右效果最佳),防止步子太大把原本好用的规则也改坏了。
经过多轮迭代后,真正被保留下来的核心规则往往只有两三句。这才是 Skill 的精华。

验证机制:改得好才保留
SkillOpt 不是盲目修改。每次改动后,都会用一批新任务来验证效果:
- 结果变好 → 保留改动
- 结果没变好 → 回退到上一版本
被回退的改动也不会白费,系统会将其存入「失败记录」档案。后续优化时就知道哪些路走不通,避免在原地打转。
每跑完一整轮,框架还会做一次全局复盘,重新审视整份 Skill,防止越跑越偏。

实测效果:覆盖 6 类任务,52 次测试全部第一
论文中给出了详细的测试数据。SkillOpt 在 6 类任务场景、7 个不同模型上进行了 52 次测试,全部拿到第一或并列第一:
| 任务类型 | 覆盖场景 |
|---|---|
| 查资料答题 | 信息检索、知识问答 |
| 表格处理 | 数据整理、格式转换 |
| 文档解读 | 长文摘要、关键信息提取 |
| 数学解题 | 逻辑推理、公式推导 |
以 GPT-5.5 为例,使用 SkillOpt 优化后的 Skill,平均分数提升了 23.5 分,其中表格类任务提升接近 39 分。关键点是——这些提升完全是在不修改模型本身的前提下获得的。
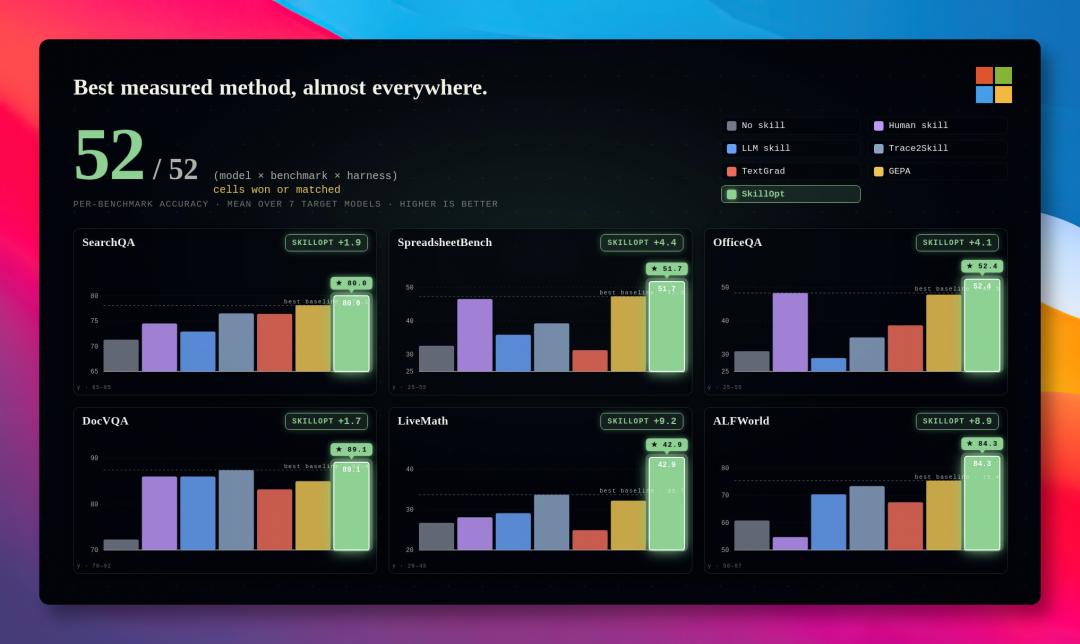
苏米注:这个结果说明了一个常被忽略的事实——很多时候模型已经够用了,真正拉开差距的是你给它的指令质量。
如何上手使用
SkillOpt 目前还没有提供开箱即用的安装包,需要手动安装:
-
克隆仓库并安装:
git clone https://github.com/microsoft/SkillOpt.git cd SkillOpt pip install -e . -
配置模型 API,支持 OpenAI、Anthropic、Qwen 等主流模型
-
准备两份带答案的测试集——一份用于训练,一份用于验证
-
执行一条命令启动优化,等待 Skill 文件输出
工具还提供了 WebUI,可以直观地观察训练过程。安装和启动命令:
pip install -e ".[webui]"
python -m skillopt_webui.app更多参数配置和使用步骤,可以参考 GitHub README 中的详细教程。
写在最后
过去调整 Skill 全凭经验,让 AI 去改,改好了也说不出原因。SkillOpt 把这件事变成了能验证、能回退、能自我迭代的过程——每次失败都成了让 Skill 更稳的经验。
类似的思路在 Hermes Agent 身上也能看到:把重复性复杂任务写成 Skill,后续不断迭代优化。两者路径不同,但方向一致——让 Skill 自己变得更好用。
也许以后,我们真的不用再一遍遍手动打磨 Skill 了。
GitHub 项目地址:https://github.com/microsoft/SkillOpt