最近在浏览开源模型时,我注意到Liquid AI发布的LFM2.5-1.2B-Thinking引起了不少讨论。
作为一名长期关注AI落地的产品经理,我对这类"轻量化推理模型"特别感兴趣——它们正在改变AI应用的部署逻辑。
与其说这是一次模型发布,不如说它标志着设备端推理从概念走向可用的一个节点。让我详细拆解一下这个项目的实际价值。
项目核心定位
LFM2.5-1.2B-Thinking是一个完全设备端运行的推理模型。其核心特征是:
- 极低内存占用:仅需900MB内存,可在任意主流智能手机上部署
- 推理能力支持:内置链式思维推理机制,模型生成答案前会产生中间思考轨迹,支持系统化问题求解
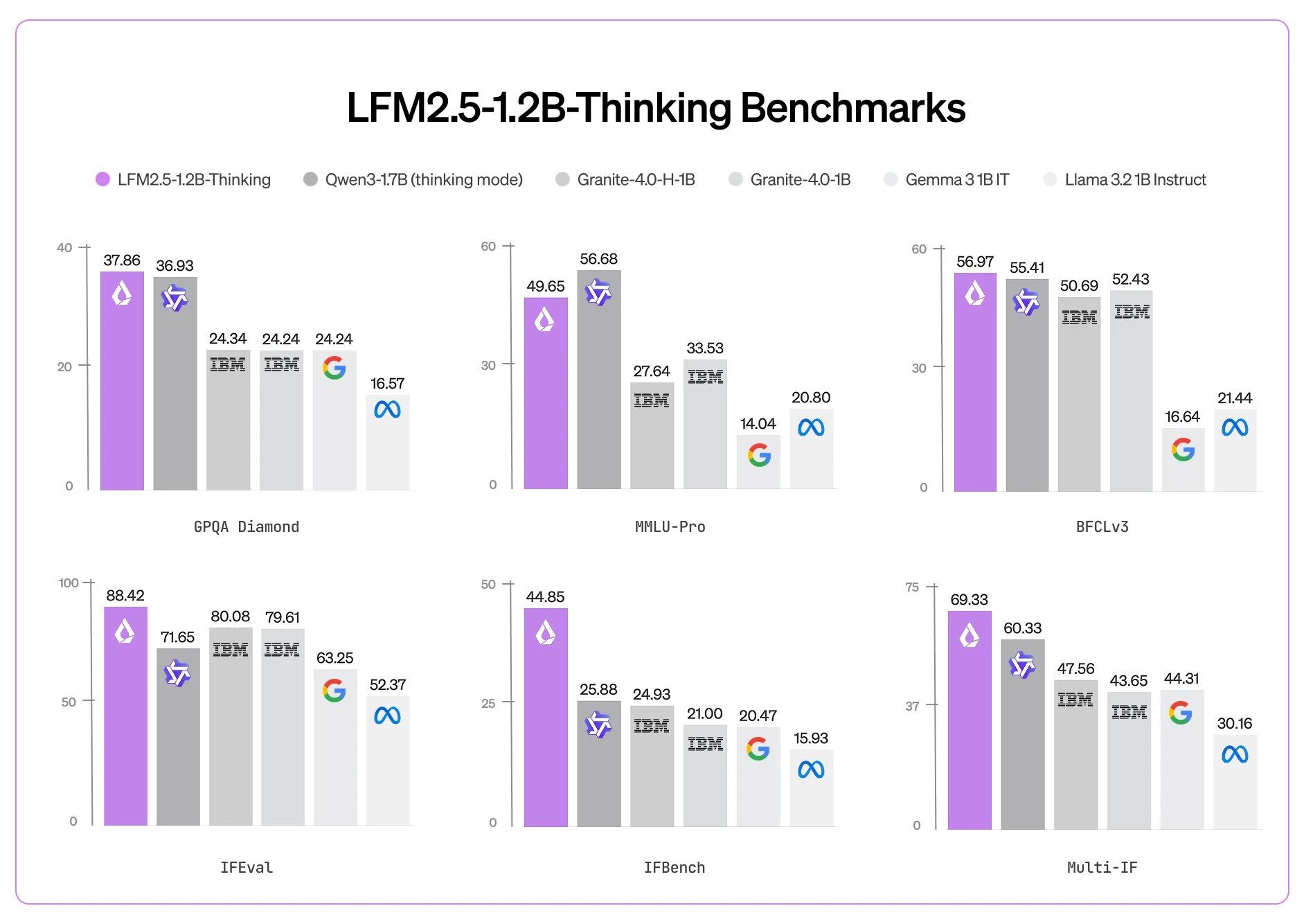
- 参数规模:1.2B参数量,相比同类对标模型(如Qwen3-1.7B)少40%参数,但性能对标或超越
- 开源友好:已在Hugging Face开源,支持多种推理框架集成
性能表现对比
为了理清这个模型的实际能力,我整理了几个关键基准的改进数据:
| 能力维度 | 基准测试 | LFM2.5-1.2B-Thinking | 变化幅度 |
|---|---|---|---|
| 数学推理 | MATH-500 | 88分 | ↑ 25分(相对指令版) |
| 指令遵循 | Multi-IF | 69分 | ↑ 8分 |
| 工具使用 | BFCLv3 | 57分 | ↑ 8分 |
推理性能指标
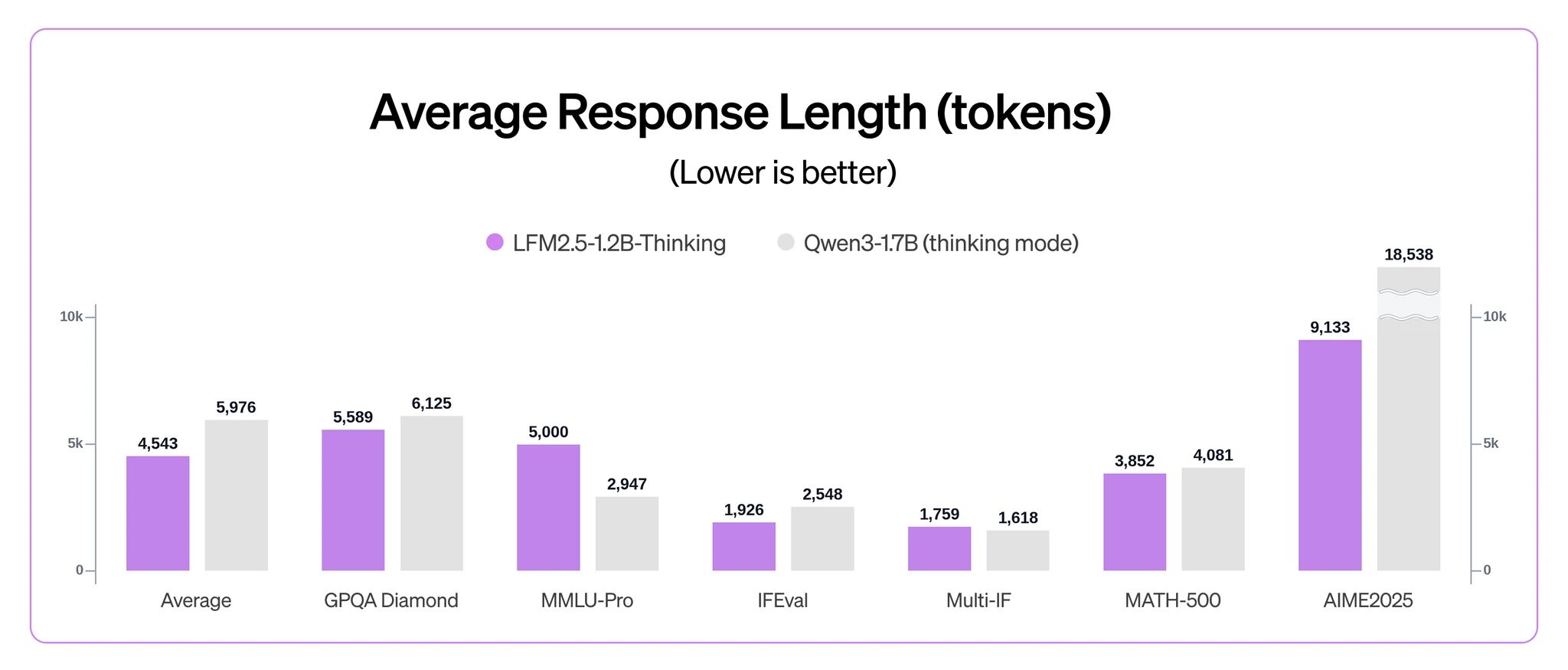
设备端推理的关键指标是解码速度和内存占用。我对比了几个代表性平台的实测数据:
桌面CPU环境(AMD Ryzen 9 3950X):237 tok/s,内存占用853MB
对标Granite-4.0-H-1B:147 tok/s(快60%)
对标Qwen3-1.7B:122 tok/s(快94%)
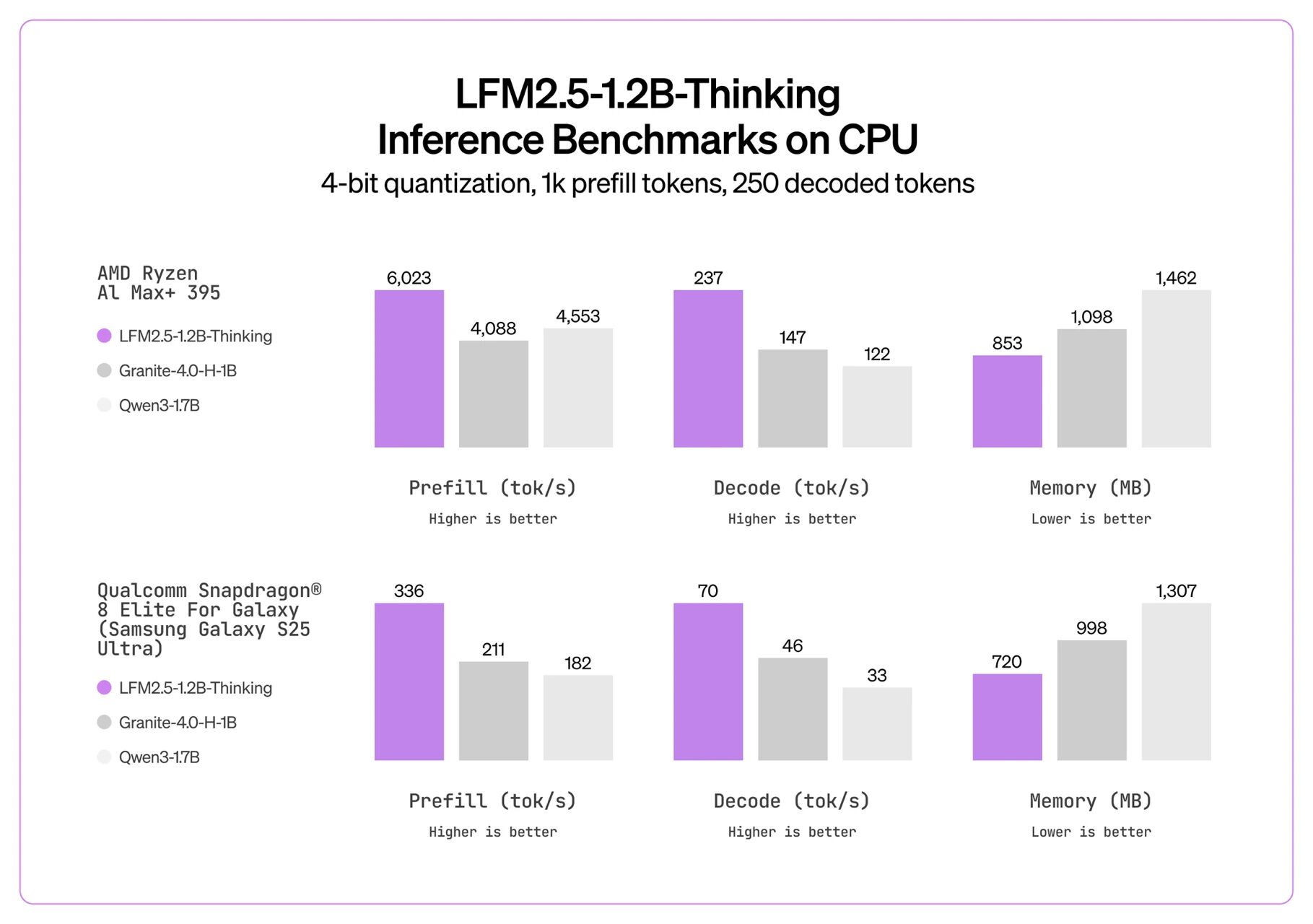
移动端芯片(高通骁龙8 Elite):70 tok/s,足以支撑实时交互
这个速度标志着本地手机推理从理论可行走向实际可用的分界点
应用场景
基于上述特征,这个模型适合以下场景:
- 离线推理应用:无需云端依赖,解决网络延迟和隐私顾虑
- 数学与逻辑推理:考试辅导、工程计算等需要多步推理的场景
- 工具调用场景:支持函数调用和API集成,适合自动化任务流
- 成本受限环境:边缘设备、IoT设备的智能化改造
- 隐私敏感应用:医疗、财务数据处理需要本地计算的领域
技术架构
模型采用混合架构设计:
- 10个双门LIV卷积块(轻量化特征提取)
- 6个GQA块(分组查询注意力,减少内存占用)
- 这种设计在保持参数量小的前提下,维持了推理能力
部署和集成
开源生态支持相对完善:
- 模型获取:Hugging Face、LEAP、Liquid Playground
- 推理框架支持:llama.cpp(CPU推理)、MLX(苹果芯片)、vLLM(服务化)、ONNX Runtime(跨平台)
- 开发者微调:可使用TRL和Unsloth进行模型调优和适配
模型家族生态
Liquid AI的LFM系列包含多个变体,覆盖不同应用需求:
- 基础版(Base):核心推理能力
- 指令版(Instruct):对齐用户指令
- 思维版(Thinking):支持链式推理——本文重点
- 语言特化版:日语优化
- 多模态版:视觉语言、音频版本
这种分层设计让不同业务需求的团队都能找到相应的模型版本。
相似项目对标
如果你对类似项目感兴趣,以下几个项目值得关注:
- Phi系列(Microsoft):类似的轻量化思路,但更侧重语言模型通用能力
- MobileLLM(Meta):针对移动端的专项优化,参数量更小但功能覆盖不同
- TinyLlama:社区驱动的1.1B模型,生态更成熟但性能指标不如LFM系列
- Qwen系列轻量版:国内对标产品,参数量相近但内存占用更多
总结与思考
从产品经理的视角,我认为LFM2.5-1.2B-Thinking的意义不在于"最强"或"最优",而在于它成功跨越了一道门槛——让设备端推理从演示案例变成可部署方案。
几个关键观察:
- 计算范式变化:与其等待云端响应,不如在本地完成推理。这改变了AI应用的延迟、隐私和成本的权衡
- 硬件驱动产品创新:大型手机制造商有动力围绕这类模型设计专门的AI芯片和产品,形成正反馈
- 开发者友好性:支持主流框架、提供微调工具,降低了普通开发者的集成门槛
- 商业化路径**:轻量化模型为边缘计算、设备级服务铺平了道路,这是一个尚未饱和的市场
如果你的产品涉及离线推理、隐私保护或成本优化,这个项目值得深入评估。它代表的不仅是一个具体的模型选择,更是AI应用架构的一种可能演进方向。
相关资源
Hugging Face模型卡:https://huggingface.co/LiquidAI/LFM2.5-1.2B-Thinking