过去几个月,我几乎每周都换着法子试 Coding Agent:从 Cursor 到 TRAE,再到 Claude Code。
一个越来越明确的感受是——能跑不等于能用。
很多时候,模型把测试跑通了,但把仓库规约、权限边界、审计流程当成“可选项”。
今天 MiniMax 上市后的第一个开源项目 OctoCodingBench 正好击中了这个痛点:把“过程合规”变成可以量化、可复现的评测信号。
背景补充:2026 年初 MiniMax 登陆港股,当前市值约 1100 亿港币。新模型还未到来,他们先开源了一个针对 Coding Agent 的评测数据集与流程,项目在 Hugging Face:
https://huggingface.co/datasets/MiniMaxAI/OctoCodingBench
为什么我会关心?
在我自己的实践里,最让团队头疼的是“结果对,过程不合规”。例如:
- 让 Agent 优化复杂度,结果顺带重构了半个模块,合规性检查、提交规范全乱了。
- 让它清缓存,Agent 直接执行危险命令(社区里有开发者反馈误删磁盘文件的案例)。
真实的软件工程被一堆看似琐碎的规则托住:权限、安全、分支策略、测试策略、发布流程、审计要求……如果 Agent 无法稳定遵循这些规约,就很难进入生产环境协作。这正是 OctoCodingBench 的切入点:不只看“写没写对”,还看“有没有按规矩写”。
OctoCodingBench 在评什么?
OctoCodingBench 的定位是 Coding Agent 的“过程评估”(process evaluation)。相较于主流结果导向评测(如 SWE-bench verified 关注用例是否通过、Bug 是否修复),它把“规则遵循”引入了度量体系:
- CSR(Check-level Success Rate):在所有规则检查项中,遵循的比例。
- ISR(Instance-level Success Rate):在单个任务实例上,是否做到了“所有规则同时满足”。
这两个指标组合能看出“单条守规矩”和“叠加约束下仍守规矩”的差异:很多模型在单项约束上表现不错(CSR 高),但一旦把规则叠起来,成功率会明显下降(ISR 低)。
从工程视角看,一个合格的 Coding Agent 完成任务时需要同时遵循这些来源的规则:
- System Prompt 的全局约束(语言、输出格式、安全策略)。
- User Query 的多轮指令更新。
- System Reminder 提供的脚手架指令。
- 仓库规范文件(如 CLAUDE.md / AGENTS.md)中的代码风格、提交规范等。
- Skills 文档的调用流程。
- Memory/Preferences 记录的用户偏好与项目状态。
换句话说,OctoCodingBench 在测“把静态规范内化为稳定行为”的能力。
数据规模与交付形态
- 实例规模:72 个实例、2422 条可二值判定的检查项,平均每个实例 33.6 条规则检查,覆盖 34 个不同环境。
- 可复现工程链路:题目描述(支持多轮)、系统提示、评估 checklist、可执行的 Docker 环境,以及 Claude Code / Kilo / Droid 等脚手架配置。
我比较看重它把评测“做成工程”的方式:不仅给出题,还把复现环境与自动化检查打包。这让“过程评估”从主观打分,变成类似 CI 的可复现流水线。
初步结果:单项守规矩不难,全程守规矩很难
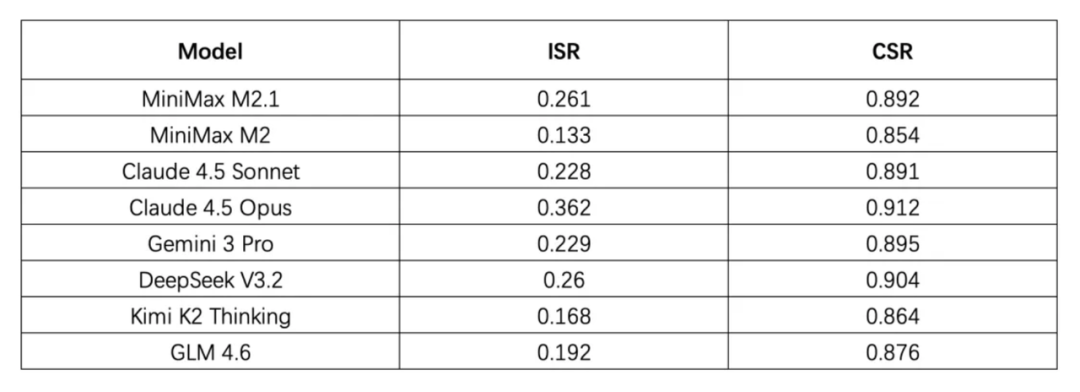
- 整体趋势:多数模型的 CSR 能到 80%+,但 ISR 只有 10%–30%。单项规则能遵循,一叠加就容易失效。
- 长流程脆弱性:多轮交互中,指令遵循能力随轮次增加而下降,长流程任务更容易出现过程违规。
- 具体数据点:Claude Opus 4.5 在该基准上的 ISR 为 36.2%;MiniMax M2.1 与 DeepSeek V3.2 的 ISR 分别为 26.1% 与 26%,在此维度超过了一些闭源模型(如 Claude Sonnet 4.5、Gemini 3 Pro)。
当评测从“结果”转向“过程”,模型的真实短板更容易被显性化。
结果导向 vs 过程导向:差异化在哪里
| 维度 | 结果导向评测(如 SWE-bench verified) | 过程导向评测(OctoCodingBench) |
|---|---|---|
| 关注点 | 测试是否通过、Bug 是否修复 | 任务完成同时是否遵循规约 |
| 评测信号 | 单一通过/失败 | 多维 checklist 的可二值判定(CSR/ISR) |
| 复现性 | 数据与用例 | 数据 + 可执行环境(Docker)+ 脚手架配置 |
| 长流程鲁棒性 | 未专门度量 | 随轮次衡量指令遵循衰减 |
| 训练适用性 | 难转化为过程训练信号 | 可用于过程监督与强化学习信号构建 |
| 工程规则覆盖 | 弱 | 强(系统/用户/仓库/技能/记忆等) |
适配性分析
- 功能范围:评估 Coding Agent 在复杂约束下的合规与完成度,不涉及通用问答或纯算法题。
- 技术特征:基于 checklist 的多源规约约束,提供可复现 Docker 环境,支持脚手架集成,指标为 CSR/ISR。
- 使用门槛:中-高。需要能拉起容器、配置 Agent 脚手架、理解仓库规约体系(CLAUDE.md/AGENTS.md/Skills/Memory)。
- 适合人群与场景:
- 研究者:把“过程合规”拆成可监督的原子约束,作为过程监督或 RL 信号。
- 工具链/产品团队:作为合规标尺,指导 IDE/Agent 工具迭代与插件生态设计。
- 企业工程团队:用于模型选型与准入评估,将过程合规纳入 CI/CD 流水线。
怎么在团队里落地
- 基线评测:选 2–3 个候选 Agent(闭源 + 开源),在同一仓库上跑一轮 OctoCodingBench,记录 CSR/ISR,并分解失败项类型。
- 规约固化:在仓库内补齐 CLAUDE.md / AGENTS.md / Skills / Memory,明确提交规范、命名规则、权限边界。
- 流水线集成:把 checklist 自动化嵌入 CI,夜跑长流程用例,观察多轮指令下的衰减曲线。
- 训练/微调信号:把高频违规项转为显式负反馈,迭代提示词与调用流程;有条件的团队可尝试过程监督或轻量 RL。
- 选型策略:不再只看榜单分数,增加“ISR 阈值 + 关键违规项红线”作为准入标准。
风险与局限
- 覆盖度:当前 72 个实例、2422 条检查项,属于可运行但仍在扩展期的规模,行业实践多样性仍需持续补充。
- 场景偏差:对特定语言栈、组织流程的适配程度需要验证;企业可基于其范式自定义扩展 checklist。
- 指标使用:ISR 对“短板效应”敏感,需结合 CSR 与失败分类分析,避免单一指标决策。
对社区与企业意味着什么
- 社区:把“Agent 守不守规矩”从经验判断变成可验证的基础设施,为过程监督与训练提供公共语料与信号。
- 工具与产品:评测覆盖仓库协议(CLAUDE.md/AGENTS.md/Skills/Memory),有利于形成更一致的 Agent 协作约定。
- 企业:引入 Coding Agent 的门槛从“谁的结果更高”转向“谁能稳定守规矩”,风险显性化,有利于进入生产环境。
结论
对 Coding Agent 来说,“写得对”只是起点,“写得合规、过程可审计”才靠近生产。
MiniMax 选择先开源一个过程导向的 Bench,而不是直接卷模型性能,方向感是清晰的。
对我这种需要把 Agent 接入真实工程的产品经理来说,它提供了可操作的标尺:把规矩写清楚、可复现、可对比,然后再谈规模化落地。
如果你的团队正在评估 AI 编程工具,建议把 OctoCodingBench 加入评审流程。稳住过程,结果通常不会差。