最近在体验各类AI创意工具时,我发现一个有趣的现象:短视频创作的门槛正在快速降低。
作为一名长期关注开源AI项目的观察者,我看到了不少试图简化视频制作流程的方案,但大多数要么功能单一、要么依赖专有服务。
直到我接触到Pixelle-Video这个开源项目,才感受到了一种相对完整的、可自主部署的视频创作自动化方案。今天就来深入拆解这款工具的实际能力与适用范围。
项目概览
Pixelle-Video是一款基于Python的开源视频生成引擎,定位于自动化短视频创作。

其核心价值在于:将视频创作流程从"多步骤手工操作"简化为"单一输入触发"的全自动处理。
技术栈特征:
- 框架基础:Python + ComfyUI 模块化架构
- 文案生成:集成GPT、通义千问、DeepSeek、Ollama等多种LLM接口
- 内容生成:支持AI生图、图生视频、数字人视频等多种形式
- 音频方案:Edge-TTS、Index-TTS等主流语音合成引擎兼容
- 部署方式:开源自托管,支持本地或服务器部署
核心功能梳理
1. 全流程自动化生成
输入一个主题或关键词,系统会依次执行:
- 文案生成:调用指定LLM生成解说词
- 视觉素材:为每句文案自动生成或匹配配图
- 语音合成:将文案转换为指定语言和音色的音频
- 背景音乐:自动添加氛围音乐
- 视频合成:组织成完整视频文件
整个流程可在3-5分钟内完成,无需人工介入。
2. 多维度定制能力
| 定制维度 | 可选方案 |
| 模板&分镜 | 多种预设模板,支持竖屏/横屏/方屏等尺寸 |
| 文案生成 | 支持自定义prompt、长度、风格等参数 |
| 配音方案 | 多语言支持、声音克隆、音色定制 |
| 素材来源 | AI生成/用户上传/外部API接入 |
| 视觉风格 | 可替换底层生图模型(如FLUX等) |
3. 高扩展性设计
基于ComfyUI的模块化架构意味着:
- 可自由替换各环节的AI模型(文案、生图、TTS等)
- 支持API接口调用,可集成到现有内容管理系统
- 支持批量任务创建,适配内容工厂式工作流
- 代码开源,允许自定义修改和二次开发
应用场景分析
适配用户群体:
- 内容创作者:快速产出日常更新内容,降低创作成本
- 电商运营:批量生成产品介绍视频、营销素材
- 知识内容方:将文章/主题自动转化为视频形式
- 社区/自媒体:补充内容库,保持更新频率
- 开发团队:作为基础能力集成到自有产品中
使用场景示例:
- 输入"AI工具推荐"→ 自动生成3-5分钟讲解视频
- 输入"产品功能介绍" → 生成带数字人的产品演示视频
- 批量导入话题列表 → 自动产出整个内容周期的视频库
安装与配置
前置环节
安装FFmpeg(视频处理基础):
# macOS
brew install ffmpeg
# Ubuntu/Debian
sudo apt update
sudo apt install ffmpeg
# Windows:从官网直接下载安装包部署步骤
# 1. 克隆项目
git clone https://github.com/AIDC-AI/Pixelle-Video.git
cd Pixelle-Video
# 2. 启动Web界面(推荐使用uv,自动处理依赖)
uv run streamlit run web/app.py首次配置
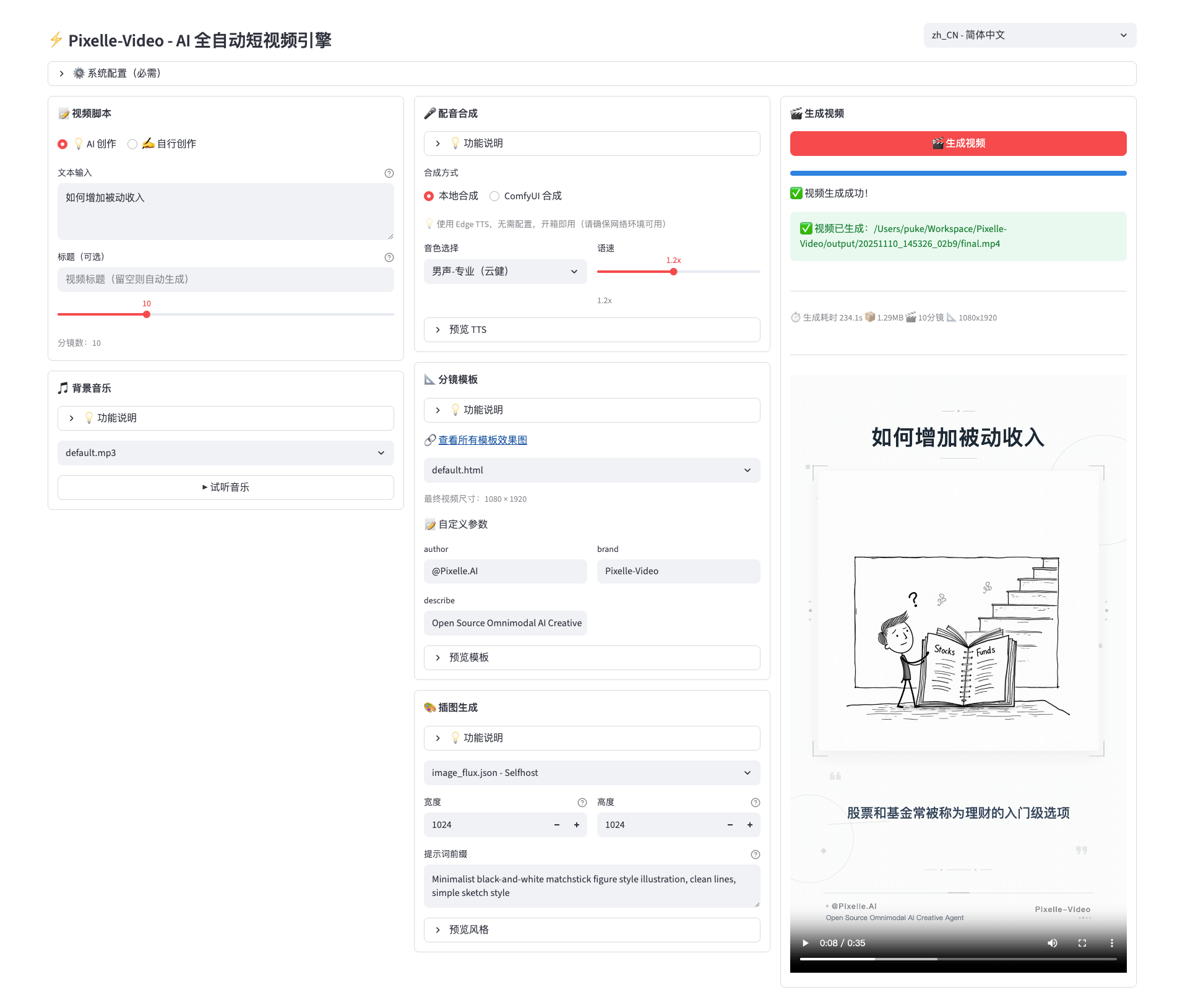
Web界面启动后,需要在"⚙️ 系统配置"面板完成以下设置:
- LLM配置:选择文案生成模型(GPT/通义千问/DeepSeek/本地Ollama),填入对应API Key
- 图像生成配置:配置ComfyUI服务地址或RunningHub API密钥
- TTS配置:选择语音合成方案及语言偏好
- 可选配置:背景音乐库、数字人素材等
配置保存后即可开始创作。
使用方式详解
模块一:快速创作
面向零基础用户的核心功能。工作流为:
- 输入主题或关键词
- 选择模板(竖屏/横屏)和文案风格
- 配置配音语言、背景音乐偏好
- 点击"生成视频",自动完成全流程
适用:快速内容更新、日常分享素材。
模块二:自定义素材
针对有自有素材的创作者。支持上传:
- 视频片段、图片库
- 音频素材(背景音乐、人物音频)
- 字幕或文案文本
系统基于上传素材自动匹配和组织,减少手工剪辑工作。
模块三:数字人口播
生成具有特定虚拟形象的视频:
- 上传或选择数字人形象
- 输入解说词或生成文案
- 自动合成该数字人在不同场景下的视频
适用:品牌统一形象、持续IP化内容。
模块四:图生视频
基于首帧静态图像生成完整视频:
- 上传首帧图片
- 提供视频描述词(动作、转场等)
- 系统生成带动效的视频
适用:静态素材的动态化处理、创意视频生成。
与相似开源项目的对比参考
| 项目名 | 定位 | 核心差异 |
| Pixelle-Video | 全流程视频自动化 | 端到端自动化,模块化设计,多模型支持 |
| Runway | AI视频编辑工具 | 功能强大但商业服务,偏向专业编辑 |
| Synthesia | 数字人视频生成 | 专注数字人形象,功能深度高但单点 |
| Descript | 语音到视频编辑 | 基于音频轨道的编辑逻辑,学习曲线较陡 |
选型建议:
- 追求"最快产出"、"零技能上手"→ Pixelle-Video
- 需要"专业级编辑"功能 → Runway或Descript
- 仅需"数字人"能力 → Synthesia
- 要求"完全自主部署、不依赖云服务" → Pixelle-Video
实用建议与注意事项
顺利使用的前提:
- LLM接口需要有效的API Key(确保余额充足)
- 首次运行会下载模型文件,磁盘空间需预留50GB+
- GPU推荐(可选但性能提升显著),CPU也可运行但速度较慢
- 如使用自托管ComfyUI,需单独部署和维护
优化建议:
- 对于批量创作,建议编写简单脚本通过API接口批量提交任务
- 自定义prompt对文案质量影响显著,值得投入时间打磨
- 预先测试不同模型组合,找到性价比最优配置
总结
Pixelle-Video代表了一类开源AI工具的典型特征:解决明确痛点、降低使用门槛、保留扩展空间。
相比商业化的视频生成工具,它的优势在于:
- 成本可控:仅需付费给底层LLM和生图模型,无平台订阅费
- 数据可控:完全自托管,内容不上传第三方服务器
- 灵活可扩:开源架构允许集成自有模型和业务逻辑
- 使用门槛低:Web界面友好,无需视频编辑基础
但也要认识到局限性:
- 生成质量依赖底层模型,需要合理的prompt设计
- 初期部署和配置存在一定学习成本
- 批量生成时计算资源消耗和成本较高
总的来看,如果你是内容创作者或运营团队,希望在短视频制作上降低成本和时间投入,同时对数据隐私和系统自主性有要求,Pixelle-Video是值得深入体验的选择。它不是"一键出爆款"的魔法工具,但确实能显著降低视频内容生产的门槛。
项目GitHub地址:https://github.com/AIDC-AI/Pixelle-Video