会议上,业务方抛来一句话 “上个月新增的客户有哪些?”而数据分析师的第一反应是打开SQL编辑器,手动去查表、写查询、调语法。
这时我就在想,如果AI能“理解”这句话并自动生成SQL,再直接查出结果,是不是就能让非技术同事也能自由访问数据?
于是,有了这么一个项目:一个由 LangChain + FastAPI + Streamlit + SQLite 组成的 Text-to-SQL 聊天机器人。
它能把自然语言问题转成SQL语句,再从真实数据库返回结果。整个过程无需用户懂SQL。
什么是 Text-to-SQL?
SQL 是数据分析的核心语言,但同时也构成了信息壁垒。
在许多公司里,只有少数人能用SQL数据库操作,而多数人只能被动等别人查数据。
Text-to-SQL 的目标,就是让每个人都能直接提问数据库。
用户问:“上季度最畅销的商品是哪些?”
系统自动生成并执行 SQL:
SELECT product_name, SUM(sales) FROM orders WHERE quarter='Q3' GROUP BY product_name ORDER BY SUM(sales) DESC LIMIT 5;
这个能力的关键,在于让AI理解数据库结构。单纯的语言模型无法做到这一点,因为它不知道你有哪些表、列、关系。
这就是 RAG(Retrieval-Augmented Generation,检索增强生成) 派上用场的地方。
核心原理
RAG 的思路其实很直白:
| 阶段 | 功能 | 举例 |
|---|---|---|
| 检索 Retrieval | 先查数据库的结构信息(schema) | “customers 表中有哪些字段?” |
| 生成 Generation | 再基于这些上下文生成 SQL | “SELECT name FROM customers WHERE created_at > …” |
换句话说,在模型写SQL之前,我们给它一张“数据库小抄”,告诉它有哪些表、哪些列。
这能极大地减少模型的幻觉——避免生成不存在的表名或错误的字段。
RAG 的工作流程如下:
User Question
↓
Retrieve Schema Info
↓
Generate SQL (LLM)
↓
Validate + Execute
↓
Return Results
↺
系统架构设计
这个项目分成了六个核心模块:
-
SQLite — 数据源,存放真实业务数据。
-
Embeddings 层 — 将表结构信息转成语义向量。
-
Chroma 向量数据库 — 存储 schema 向量,用于语义检索。
-
LangChain — 构建 RAG 流程链。
-
FastAPI — 封装接口,构建后端服务。
-
Streamlit — 提供交互式前端。
完整流程如下:
User (Streamlit)
↓
FastAPI Backend
↓
LangChain RAG Pipeline
├── Retriever (Chroma)
├── Embedding Layer (Hugging Face)
├── LLM (SQL Generator)
↓
SQLite Database
↓
Results → Streamlit UI
动手搭建
Step 1:准备数据库
先创建一个简单的 SQLite 数据库:
import sqlite3, os
os.makedirs("sample_db", exist_ok=True)
DB = "sample_db/sample.db"
conn = sqlite3.connect(DB)
cur = conn.cursor()
cur.execute("""
CREATE TABLE IF NOT EXISTS customers (
id INTEGER PRIMARY KEY,
name TEXT,
email TEXT,
created_at TEXT
);
""")
cur.execute("""
CREATE TABLE IF NOT EXISTS orders (
id INTEGER PRIMARY KEY,
customer_id INTEGER,
total_amount REAL,
status TEXT,
created_at TEXT,
FOREIGN KEY(customer_id) REFERENCES customers(id)
);
""")
并插入一些示例数据:
customers = [
(1, "Alice", "alice@example.com", "2025-01-01"),
(2, "Bob", "bob@example.com", "2025-02-01"),
]
orders = [
(1, 1, 120.5, "completed", "2025-03-01"),
(2, 2, 80.0, "pending", "2025-03-10"),
]
cur.executemany("INSERT OR REPLACE INTO customers VALUES (?,?,?,?)", customers)
cur.executemany("INSERT OR REPLACE INTO orders VALUES (?,?,?,?,?)", orders)
conn.commit()
conn.close()
Step 2:创建 Embeddings 索引
我们要让AI理解数据库结构,需要先把schema内容向量化并存入Chroma:
from langchain_community.embeddings.huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
import sqlite3, hashlib
def row_to_text(table, cols, row):
return f"Table: {table}\n" + "\n".join([f"{c}: {v}" for c, v in zip(cols, row)])
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
vectorstore = Chroma(collection_name="sqlite_docs", persist_directory="./chroma_persist", embedding_function=embeddings)
conn = sqlite3.connect("sample_db/sample.db")
cur = conn.cursor()
cur.execute("SELECT name FROM sqlite_master WHERE type='table'")
tables = [t[0] for t in cur.fetchall()]
for table in tables:
cur.execute(f"PRAGMA table_info({table});")
cols = [c[1] for c in cur.fetchall()]
cur.execute(f"SELECT {', '.join(cols)} FROM {table}")
rows = cur.fetchall()
docs = [row_to_text(table, cols, r) for r in rows]
vectorstore.add_texts(texts=docs)
Step 3:LangChain 构建 RAG 流程
from langchain_core.prompts import PromptTemplate
from langchain_google_genai import ChatGoogleGenerativeAI
sql_prompt = PromptTemplate.from_template("""
You are a SQL generator. Based on the following context, generate a SINGLE READ-ONLY SQLite SELECT query.
Context:
{context}
Question:
{question}
Return only the SQL SELECT statement.
""")
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
llm = ChatGoogleGenerativeAI(model="gemini-2.0-flash", temperature=0)
Step 4:FastAPI 封装后端接口
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI(title="Text-to-SQL API")
class QueryRequest(BaseModel):
question: str
.post("/query")
async def query(req: QueryRequest):
docs = retriever.get_relevant_documents(req.question)
context = "\n\n".join([d.page_content for d in docs])
prompt = sql_prompt.format(context=context, question=req.question)
sql = llm.invoke(prompt).content.strip()
return {"sql": sql}
Step 5:Streamlit 前端交互界面
import streamlit as st
import requests
st.title("💬 Text-to-SQL Chatbot")
question = st.text_input("输入你的问题:", "上个月加入的客户有哪些?")
if st.button("查询"):
resp = requests.post("http://localhost:8000/query", json={"question": question})
st.code(resp.json()["sql"])
运行:
uvicorn server:app --reload
streamlit run app.py
此时,你就可以在浏览器中输入自然语言问题,实时看到AI生成的SQL语句。
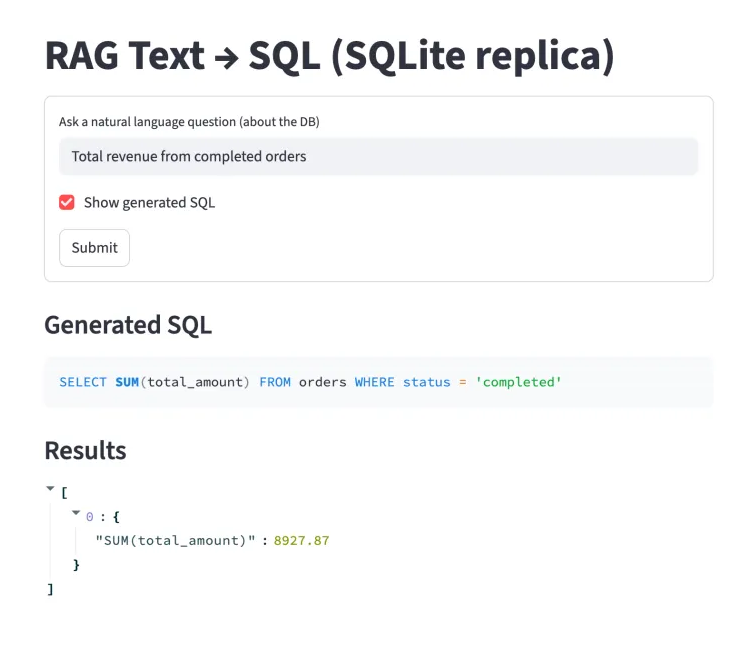
运行效果与验证
例如输入:
“列出2025年1月之后注册的客户。”
生成的 SQL 可能为:
SELECT name, email FROM customers WHERE created_at > '2025-01-01'
系统返回的结果:
| name | |
|---|---|
| Bob |
总结
整个项目虽然只是一个原型,但对我而言有三点启发:
RAG 的落地关键在于“上下文管理”
AI不是凭空聪明,而是要被喂上下文。数据库schema就是这种上下文的典型形式。
LangChain让复杂的AI流程标准化
把检索、生成、执行逻辑模块化,方便调试与扩展。
FastAPI + Streamlit 是实验型项目的理想组合
前后端用纯Python实现,既能快速验证,也方便分享和部署。
Text-to-SQL 的应用场景非常广:从BI系统、数据看板,到客服报表,都能受益于这种“自然语言 + 数据查询”的交互方式。
这也是我最喜欢AI工具实践的部分——用AI降低门槛,而不是取代专业。
如果你也想尝试这个项目,可以直接从 GitHub 运行示例仓库,或者在自己的业务数据库上做一次“小实验”,看看AI能不能帮你“问出答案”。
GitHub :