最近,我在GitHub上发现了一个令人兴奋的项目,它提供了一条全面的学习路线图,让每个对大语言模型(LLM)感兴趣的科研人员和工程师都能轻松上手。

这不仅是一个免费的LLM课程,还涵盖了科学家和工程师两条路径,配备了实际操作的Notebook、论文资源以及初学者所需的一切工具。
项目简介
该课程由Maxime Labonne开发,它分为三个主要部分:
-
LLM基础(可选):涵盖数学、Python和神经网络的基本知识,适合初学者回顾。
-
LLM科学家:深入讲解如何训练最佳的大语言模型,涵盖数据准备、架构选择、微调技术等具体环节。
-
LLM工程师:专注于构建LLM应用,包括如何运行模型、构建向量数据库、实现检索增强生成(RAG)系统、开发AI代理以及优化推理性能。
核心功能
项目中包含的几大核心工具,都是为了降低技术门槛而设计的:
-
LLM AutoEval:自动化模型评估,省却手动测试的繁琐。
-
LazyMergekit:一键合并不同模型,无需强大的GPU支持。
-
AutoQuant:支持多种格式的模型量化。
-
LazyAxolotl:实现云端模型微调,方便快捷。
这些工具的引入确实为用户大大简化了模型使用的复杂性,尤其是在诸如模型评估和合并等方面。
应用场景
该课程适合多种学习场景,无论是正在进行学术研究的科学家,还是希望应用AI技术的工程师,这里都有高质量的资源可供参考。

通过此课程,参与者可以系统化地掌握如何构建、训练和部署大型语言模型,提高在AI领域的竞争力。
安装部署与配置
项目适用于Google Colab,用户只需在Colab上打开提供的Notebook链接,即可开始学习和实践。
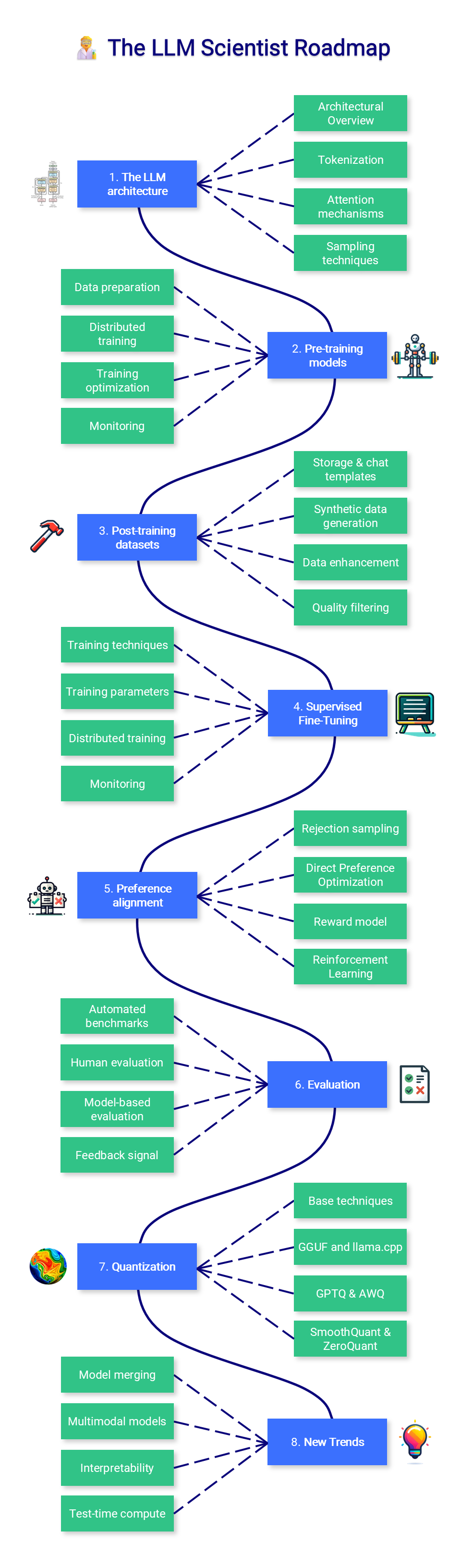
具体的安装步骤和配置细节在项目的README文档中也有详细说明。此外,保持关注该项目,作者会持续更新并添加新工具,以便不断丰富课程内容。
结尾总结
在这个日新月异的AI时代,系统化的学习路径显得尤为重要。这条免费的LLM课程不仅为每位学习者提供了必要的知识框架,还包含了丰富的实践材料,使得任何人都可以轻松入门LLM应用开发。作为一名产品经理,我深知这样的资源在探索复杂技术时的不可或缺性。无论你是LLM领域的新手还是老手,这门课程绝对值得一学。
期待你在这条学习旅程中获得更多启发和收获!
开源地址: