很多团队说要做知识库,最后往往做成了共享盘、Wiki 或者一个"能搜的文档堆"。这些工具当然有用,但当你希望它能稳定支撑团队协作、甚至接入 AI 问答(RAG)时,就必须重新定义:工程语境里的知识库不是文件的集合,而是一套面向检索与复用的信息系统。
它至少包含五个维度:内容载体、结构与元数据、检索与使用方式、治理机制、反馈闭环。
文档堆 vs 企业级知识库
文档堆的典型特征是资料杂乱——缺少统一命名、没有版本管理、找不到负责人。能搜到但无法判断对不对,一更新就"旧答案复活"。
企业级知识库则要求内容可检索、可定位、可追溯,答案能指向来源,权限可控,上线后可运营、可度量、可持续迭代。如果要接入 RAG 系统,还需要明确哪些 Agent 用哪些知识库,以及分块、召回、重排等系统旋钮由谁管控。
为什么 Demo 容易,生产很难
RAG 的 Demo 确实快:把文件丢进向量库,接上大模型,套个聊天界面,三天就能跑。但交给一线用、交给合规看、交给运维扛稳定性,才会发现它不是"一个模型问题",而是系统工程。
决定项目成败的往往是围绕 RAG 的工程底盘与控制系统——评估、门禁、监控、迭代机制。常见的五个坑:分块策略不当、Embedding 选型失误、上下文导致幻觉、数据预处理不足、缺少反馈闭环。
全链路架构
把企业级知识库当作一条生产线来理解会更清晰:输入是混乱的资料,输出是可检索、可信任、可迭代的组织资产。从内容盘点到上线运营,缺一环都容易掉链子。
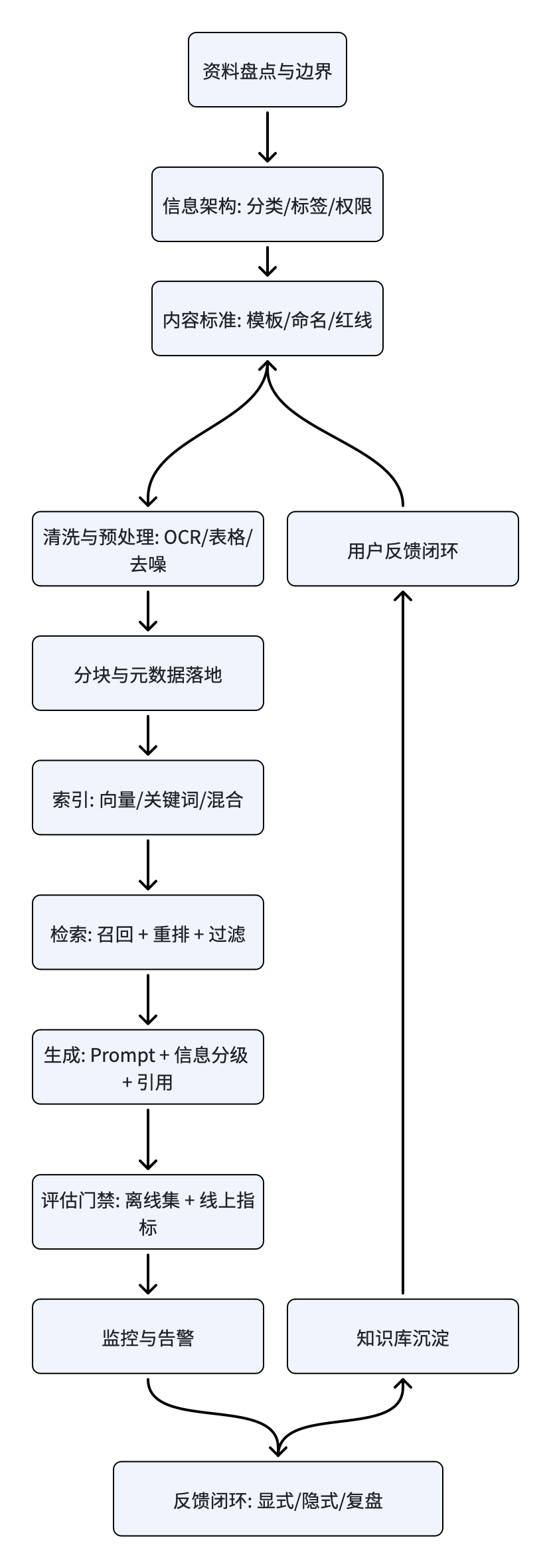
目标与边界:先做对
企业级项目最怕目标模糊。知识库不是越大越好,而是越"对问题"越好。建议用四个问题锁定范围:
- 谁用?研发、运维、一线客服、客户、供应商,还是某个业务线?
- 解决什么?高频问答、排障 SOP、操作指导、制度条款解释,还是交付沉淀?
- 成功标准?命中率、准确率、自助率、工单下降、响应时长下降,选 2-3 个做主指标。
- 不做什么?敏感数据、实时变化数据、未经审核的外部口径,写进排除项。
苏米注:把目标写成"TopN 问题清单 + 验收阈值",例如"Top50 高频问题准确率≥80%",评估和迭代都更有抓手。
知识资产分类:显性、隐性、嵌入式
很多企业只做"文档"入库,但真正的价值常常藏在更深处——老师傅的经验、团队默认习惯、系统里散落的数据。
显性知识:手册、FAQ、制度、架构文档、复盘。难点是版本混乱和过期。建议做成可检索、可追溯的文档,高频问题补 Q&A。
隐性知识:排障直觉、经验诀窍、评审判断标准。难以写清、依赖语境。建议用案例复盘模板化,以"现象-原因-处理-验证"固化。
嵌入式知识:流程习惯、系统配置、规则引擎。散落在系统与配置中。建议把"规则+例外+截图"整理成条目,必要时接 API 实时查询。
先把显性知识做成可检索、可追溯的,再逐步把隐性和嵌入式知识结构化,不要一上来就追求"全公司知识宇宙"。
10 步搭建法
第 1 步:目标与边界——输出《范围说明》《指标与验收口径》,把"不能回答什么"写清楚。
第 2 步:信息架构——至少三层:业务域/系统域 → 流程/模块 → 最小可复用条目,定义元数据字段。
第 3 步:内容标准——发布模板、命名规则、质量红线。SOP 建议每步配图并写"验证/回滚"。
第 4 步:内容盘点与清洗——去重、去过期、补负责人。统一成可维护的主格式。
第 5 步:入库颗粒度——手册/规范走文档型;TopN 高频问题走 Q&A 型,两者结合。
第 6 步:分块与元数据——一段只讲一个主题/动作;保留必要上下文;绑定分类、版本、适用范围与 Owner。
第 7 步:检索策略——召回、父子分块、重排由管理员统一管控,先把内容做好。
第 8 步:生成策略——信息分级、引用来源、置信度声明与兜底策略,让回答"可核对"。
第 9 步:评估与验收——离线评测集 + 线上指标,对 TopN 问题做回归测试。
第 10 步:运营与迭代——显式反馈 + 隐式反馈 + 周期复盘,让知识库持续演进。
数据清洗与预处理:80% 的工程量
企业资料的真实面貌是格式多、结构乱、扫描件多、表格多。把数据处理当成知识库的地基——地基没打好,再高级的检索与模型都救不回来。
推荐做法:先对文档分类,再走不同处理管线。可编辑文档(Word/Markdown)走结构解析;扫描 PDF 走 OCR;表格单独结构化;图片提取为附件并与段落绑定。如果用 Dify 等平台构建 RAG,通常有"提取器 + 分块器 + 知识库节点"的流水线能力,支持图片作为分段附件甚至多模态检索。
分块、检索、重排:让召回靠谱
分块:语义边界优先
固定长度分块(如 512 tokens + overlap)在很多场景能跑,但企业文档常常是"步骤流程""现象-原因-处理"这种结构,随意切会把关键步骤切碎。更稳妥的做法是按标题层级或段落结构分块,必要时做父子分块——子块用于匹配,父块用于提供完整上下文。
| 策略 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 固定长度分块 | 实现简单 | 破坏语义边界 | 结构弱、内容短的文本 |
| 结构化分块 | 保留章节完整性 | 需要解析文档结构 | 手册、规范、SOP |
| 父子分块 | 匹配更准、上下文更全 | 索引更复杂 | 条款密集、步骤密集场景 |
Embedding:通用兜底,领域增强
通用 Embedding 能保底召回,但行业术语、设备名、内部简称会导致语义偏移。很多企业最终走向"双路召回":通用模型兜底 + 领域适配模型精准匹配,再用重排模型做融合。
重排与过滤
召回多不等于好。把无关背景、相似但不同版本、权限不匹配的段落过滤掉,把更权威、更匹配的段落排到前面,才能降低"上下文干扰"。
生成与可信回答
企业场景中的幻觉常见根因是检索到的信息没有分级。当检索内容里混杂了手册、维修记录、聊天记录,大模型不知道谁更权威,就会被干扰。
三段式提示词思路:角色定位(你是谁)→ 信息分级(优先引用谁)→ 置信度声明(不确定就说不确定,并给出"去哪里核对")。
企业级回答应满足三条"可核对"标准:
- 可定位:能指向具体文档/章节/条款(至少给出文档名与段落摘要)
- 可追溯:知道答案来自哪个版本、何时更新、由谁维护
- 可熔断:命中置信度过低时不胡答,转为建议阅读原文或升级人工
治理、评估与闭环
知识库进入生产后,核心问题是答案能不能长期保持正确、能不能持续迭代、出了问题谁负责。
治理:三类角色 + 三条主线
角色:Owner 负责内容,Reviewer 负责审核,Admin 管系统配置与权限。
三条主线:内容线(新增/修改/归档)+ 配置线(分块/检索策略变更)+ 安全线(权限/审计/脱敏)。
评估:离线回归测试 + 线上指标面板
维护一套"TopN 问题评测集",每次改分块/检索策略或大规模更新内容时跑一遍回归,避免历史问题失效。线上重点盯三类指标:
- 检索指标:命中率、无结果率、TopK 相关性
- 回答指标:满意度、纠错率、升级人工比例
- 运营指标:高频问题变化、知识覆盖空洞
反馈闭环
最有效的组合是"三层反馈":回答后让用户点"有用/没用"(显式);追踪复制、追问、离开等行为(隐式);每周抽样复盘,找系统性原因并形成迭代任务。
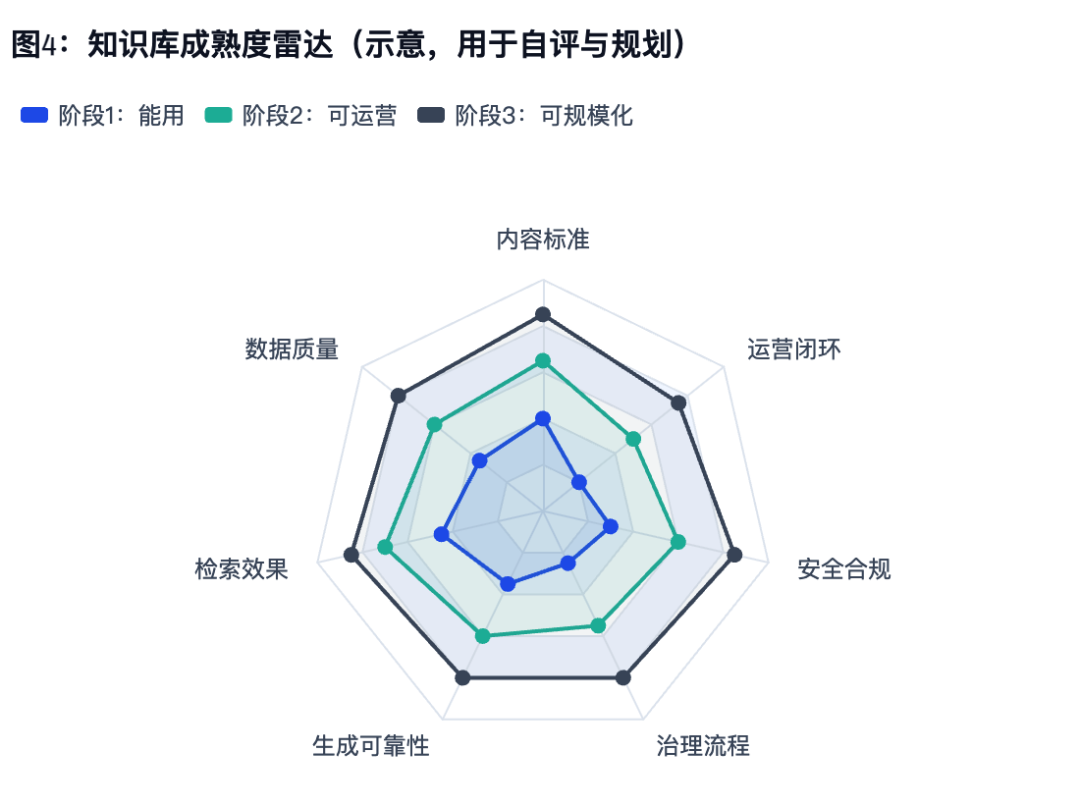
苏米注:从左到右不是"越高越先进",而是看最短的那块板。短板通常优先补——内容标准与数据质量,其次才是模型与参数。
路线图与模板
四个阶段,每个阶段只做最必要的事:
| 阶段 | 目标 | 关键产出 | 验收信号 |
|---|---|---|---|
| 第 0 阶段(1-2 周) | 范围清晰 | TopN 清单、模板、架构 | 所有人对"做/不做"一致 |
| 第 1 阶段(2-4 周) | MVP 可用 | 核心文档入库、分块策略 | TopN 问题可稳定命中 |
| 第 2 阶段(1-2 月) | 可运营 | 评测集、指标面板、反馈入口 | 问题能定位、追溯、闭环 |
| 第 3 阶段(持续) | 可规模化 | 多知识库分域、领域 Embedding | 新增业务线复用成本低 |
三份可直接复用的模板:
- 《知识库范围说明》:覆盖领域、排除项、风险等级、目标用户
- 《内容规范》:FAQ/SOP/规范/复盘四类模板 + 命名规则 + 质量红线
- 《评测与验收》:TopN 问题集、指标定义、回归测试流程、门禁策略
企业级知识库做到最后,你会发现它不只是"一个工具",而是一套组织能力——把知识从"散落与口口相传",变成"可检索、可信任、可演进"。