最近终于解决了一个头疼很久的问题——AI 生成的图片无法编辑。
经常用 GPT Image 2、Nano Banana 的朋友都知道,无论是图片流 PPT、信息图、技术架构图还是论文配图,做出来可能就一句话的事,但修改起来贼麻烦。虽然可以用自然语言让 AI 重新出图,但可控性和灵活度远远不够。根本没法像在 Visio 或 PowerPoint 里一样自由调整文字、图框和各种素材。
找了很久,都没发现既能把复杂图形完美转为可编辑格式,又不要求本地部署大模型、轻松好上手的方案。于是自己做了这个 Skill——FigEdit · 图易编。
给它一张截图、论文配图、AI 生成的幻灯片、技术架构图,或者任何图片格式的图形,它会把图片拆解重建成可编辑的矢量图形包。从此图片编辑自由不是梦。
这些场景都能用
虽然初衷是解决 AI 图片不可编辑的问题,但实际应用场景非常广。凡有图片矢量化需求,它都能搞定:
AI 生成的图片不能编辑?GPT Image 2、Nano Banana 生成的幻灯片、架构图画面惊艳,但全是像素。FigEdit 把布局提取成真正的 PowerPoint 元素,文本框能编辑、形状能移动、背景能替换。
看到好看的论文图想复刻?想复刻优质图示的图框、形状、布局、配色。FigEdit 把图重建成可编辑结构,30 秒改完标签、替换元素,不用从头画一小时。
图片原始可编辑版本丢失?设计师交付的精美信息图,可编辑源文件丢了或从未共享。FigEdit 拆成可编辑的 SVG,框架变矢量,图标保留为干净的裁切图,文字变成可选中的文本。
转换效果很能打
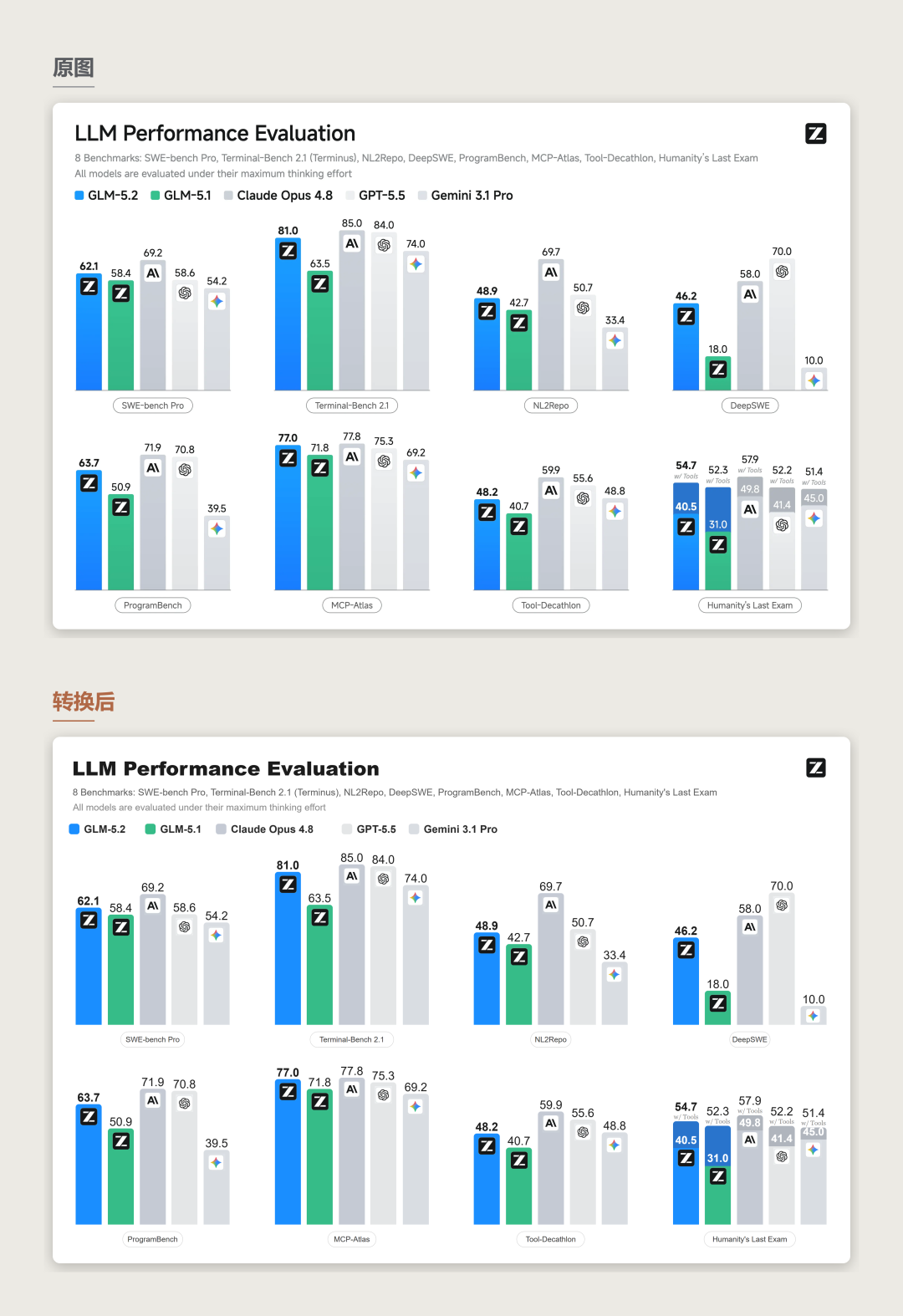
下面八个案例都是原图与 FigEdit 重建结果的对比。很多图几乎可以做到 100% 还原重建,不仔细对比可能看不出差异。
案例一:PPT 结构拆解
对信息图和 PPT 式版面的混合重建,解决 AI 图片流 PPT 不可编辑问题。卡片、标题、文字、箭头和时间线保持可编辑,具有来源特征的插图保留为可替换图片资产。

案例二:图标与结构混合图
常见论文图,图标、公式、结构化面板和流程关系并存时的混合重建。普通文字、框架、箭头和公式保持可编辑,模型标识与来源特异图形保留为可替换图片资产。
案例三:全矢量重绘
简约形状图,FigEdit 实现完整矢量重绘。原图中的面板、曲线、热力图、节点、连接线和普通文字均被重建为可编辑对象,没有使用栅格插图资产。
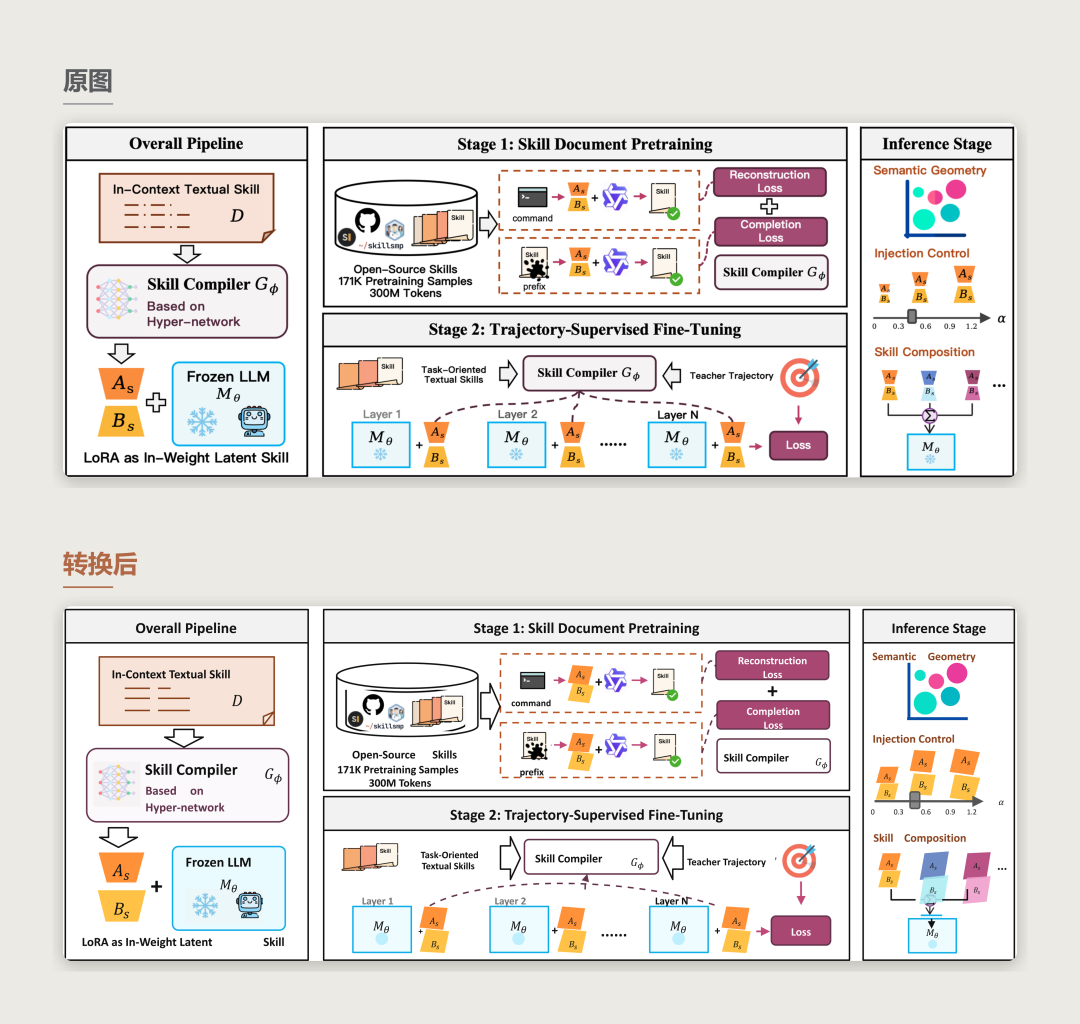
案例四:大量图片资产裁切
以图片资产为主的复杂结构图。面板、标题、分隔线、流程箭头和普通标签被重建为可编辑对象,服装、人物、截图、图标与缩略图则保留为可替换的原始裁切资产。

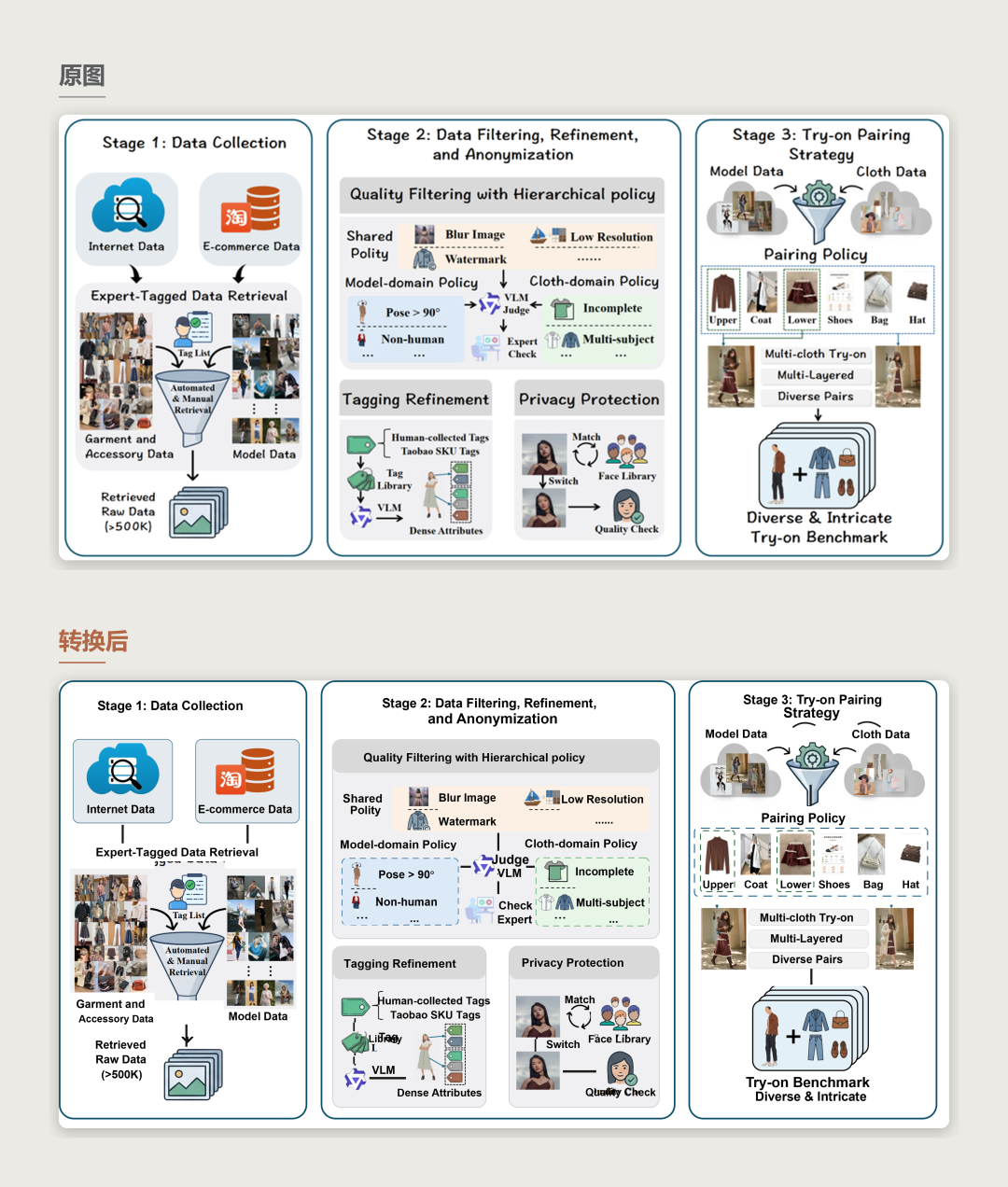
案例五:多要素混合重构
地图、手机界面、路线图、模型标识、指标卡和大量文本共同出现时的多要素混合重建。规则版面和普通文字保持可编辑,地图与来源特异图形作为图片资产保留。
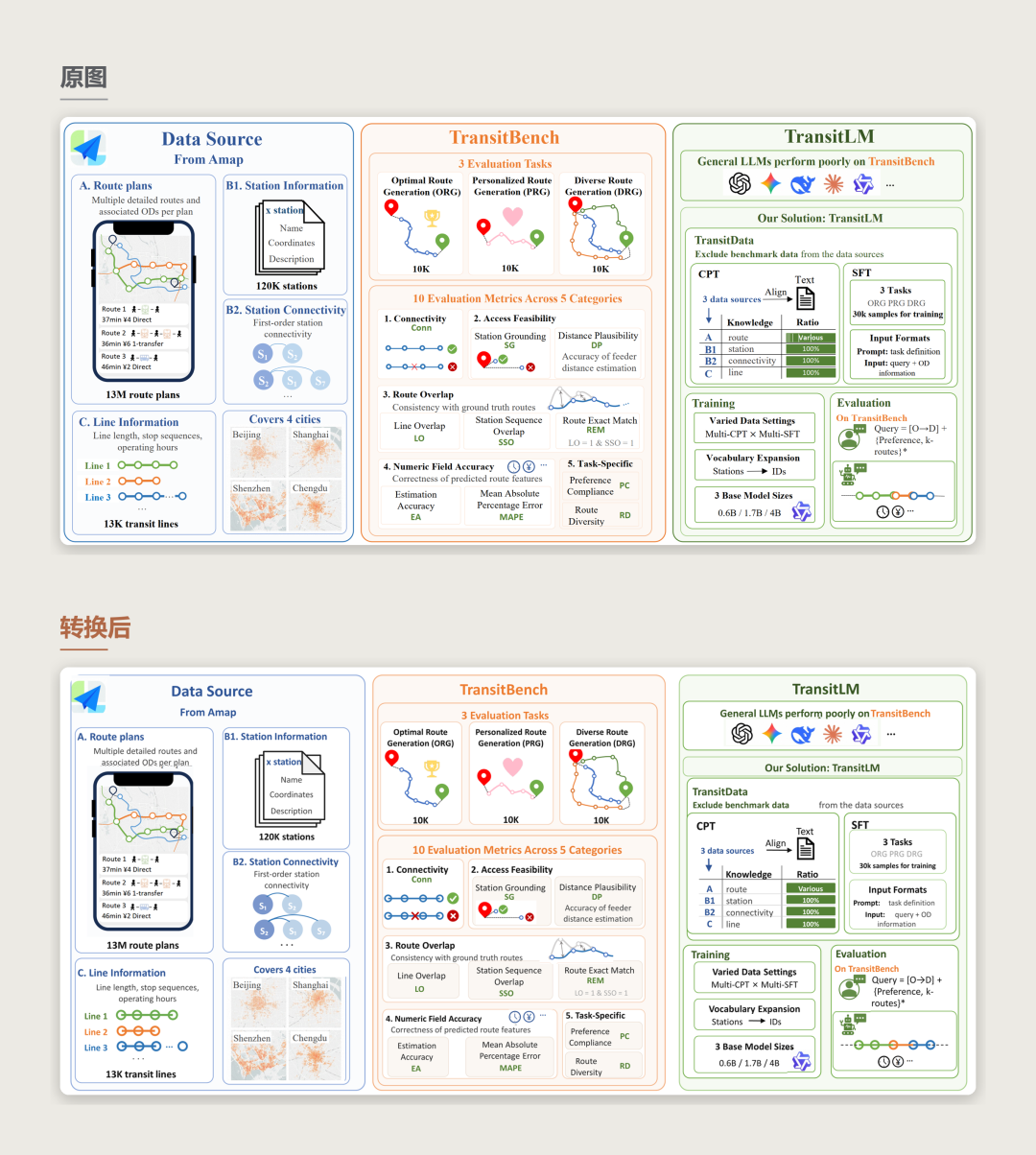
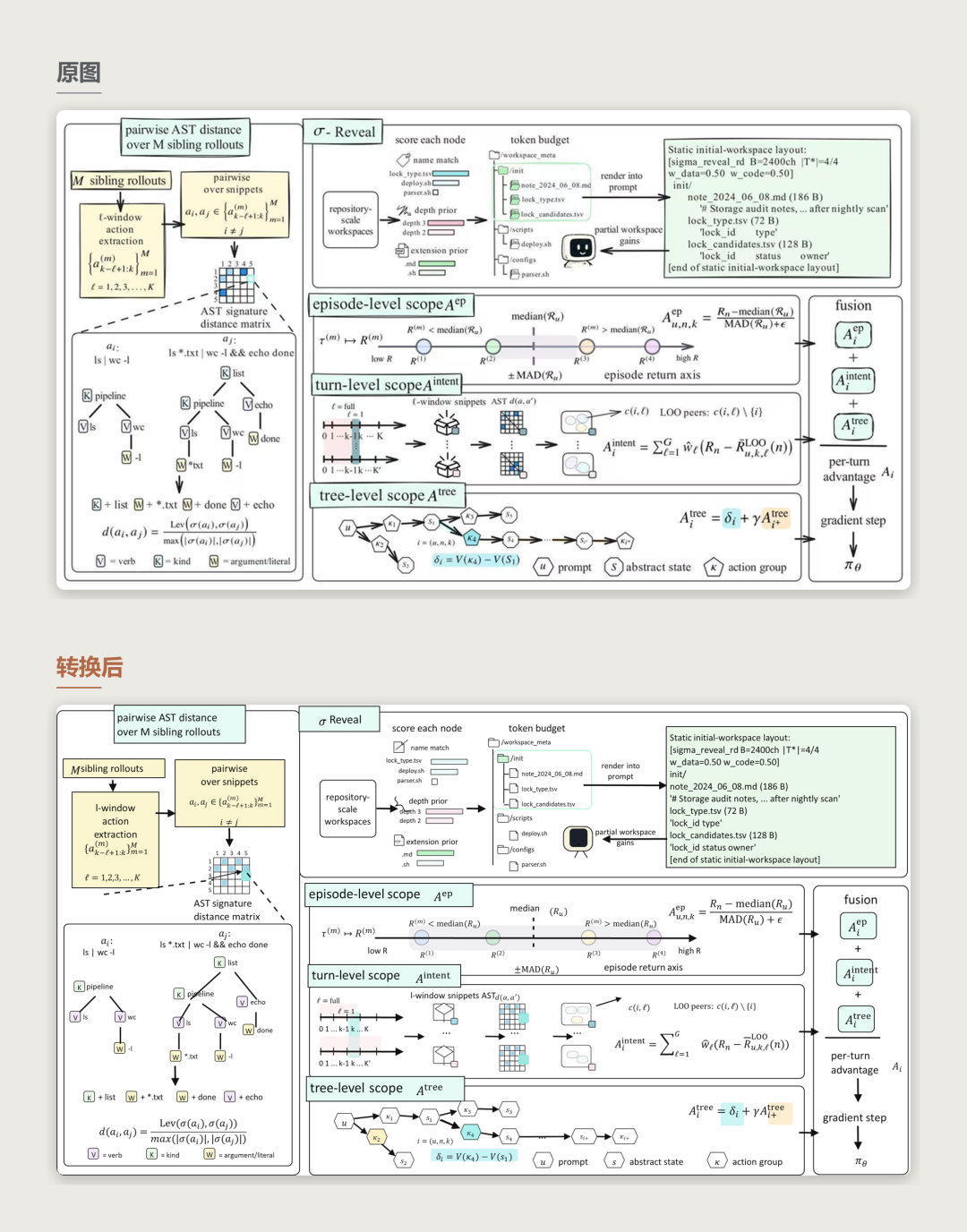
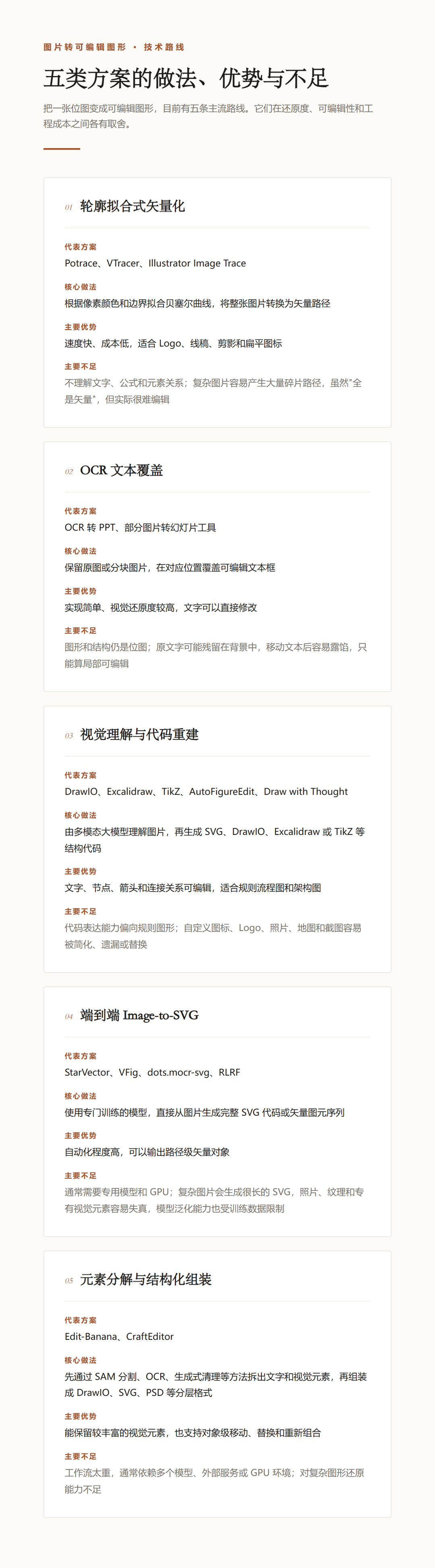
案例六:复杂公式复现
公式密集型论文方法图。FigEdit 重建了多层面板、流程关系、树结构和数学表达式,并将 50 个公式导出为可编辑的 PowerPoint Office Math 对象。
案例七:公式与图片资产混合重建
复杂论文图的混合重建。版面、标题、流程线、张量示意和公式被重建为可编辑对象,视频帧、相机网格和三维图等视觉证据则作为可替换图片资产保留。
案例八:多分组数据图表重建
技术报告图,多分组柱状图的重建。标题、图例、数值、坐标标签、柱体和分组结构均为可编辑对象,模型 Logo 作为可替换图片资产保留。

为什么要用 FigEdit?
把一张扁平图片变回可编辑文件,难点不只是识别画面里有什么,而是判断每个元素应该以什么形式呈现。是让 AI 完全重绘,还是直接裁剪拼接?哪些元素重新生成,哪些要精准提取?真实世界的图片里会出现什么往往不可预测,现有方案各有各的问题。
FigEdit 理念与 Edit-Banana、CraftEditor 类似,但它采用更智能的混合重建策略,只求最完美的可编辑还原:
- 文字、标题、普通标注重建为可编辑文本
- 公式识别为独立的语义对象,并保留原有的格式样式
- 面板、形状、边框、箭头和连接关系重建为矢量对象
- Logo、照片、截图、地图、复杂图标等来源特异的视觉内容,直接从原图裁切保留
- 最终同时输出 SVG、内嵌资产 SVG 和原生可编辑 PPTX
只需要一个足够强的 Agent,就能全自动完成图片分析、拆解、重建、导出和质量检查。
怎么使用?
一句话安装
FigEdit 是基于 AI Agent 环境的 Skill,理论上当前所有 Agent 都能支持运行。不过图片重建质量高度依赖模型视觉理解与 SVG 绘制能力,不同模型表现差异极大。优先推荐 Codex、Claude Code,这两个公认最强的 Agent 搭配最强的模型,可以发挥 FigEdit 的最高上限。
用起来很简单,把项目地址发给你的 Agent,说一句:
帮我安装这个 skill:
https://github.com/giszzt/figedit
装好之后,在 Agent 里发送任意图片说一句话就行,模型会跑完整个流水线,把输出包交付到你的项目目录。
实战案例
以一个典型的技术框架图为例,讲讲 FigEdit 的图片矢量化工作逻辑。这张图每个技术环节都有大量的定制照片、图标素材,这么复杂的图片要素,FigEdit 怎么处理呢?

拿到图它不会盲目开干,先大概判断这属于什么类型的图,识别哪些元素要重绘或者精细裁剪保真。
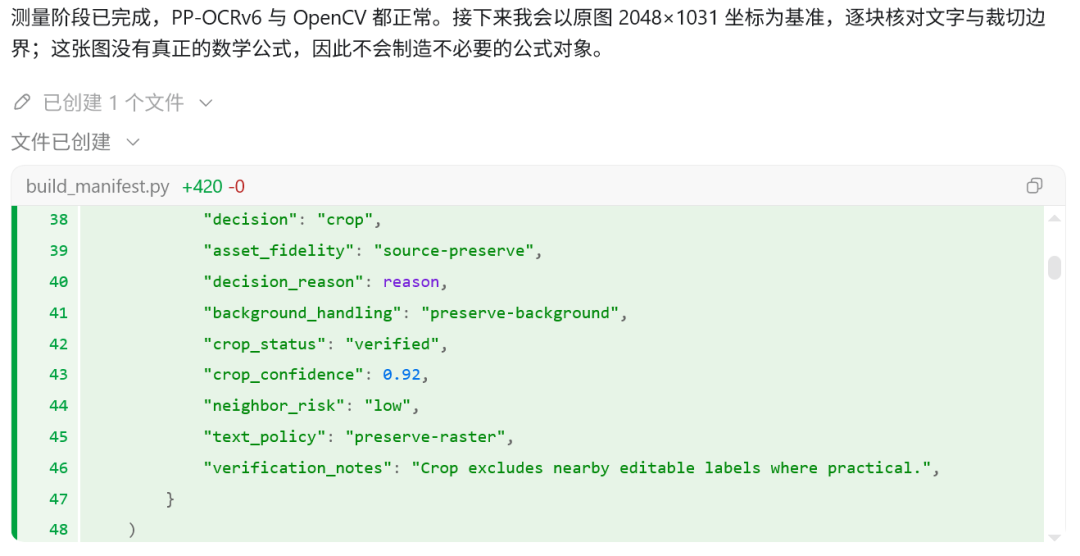
接下来会调用文字与图形识别模块,对原图中的文字、图形化元素、图片大小等信息进行初步识别分析。这一步拿到测量报告传给 Agent 主模型作参考,由模型思考确定整体布局,不同元素如何排列组合。

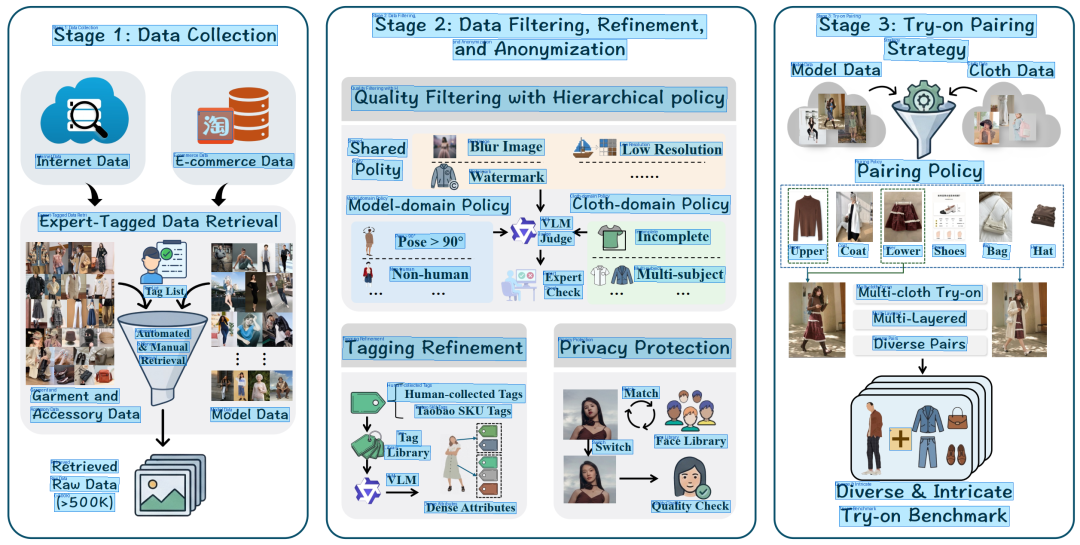
模型分析完结果,定好重建策略,就按施工路线图开干。
生成完初步结果,Agent 会执行自动检查,看看当前重建的图有哪些质量问题。一般而言,最多两轮就会完成所有检查与重构精修,超级复杂的图检查工序可能会多点。
最后输出的结果不仅有直接编辑使用的 SVG、PPTX 文件,还有质量报告、裁剪资源包以及各类说明文档。

如果对结果不满意,本次输出的这些资源也能给下一次优化参考,无需重头再来。通常还原出来的图都有九十分以上了,剩下的小细节可以编辑微调。毕竟 Token 很贵,能省点是一点。
说到成本,ChatGPT Plus 会员用 Codex 处理一张图通常消耗周额度在 5% 以内。除非是特别复杂的图,处理时间一般不会超过 10 分钟,Claude Code 也差不多。
写在最后
这个 Skill 的诞生很意外。原本觉得这种复杂需求必须要专业机构或者研究团队研发,结果那天跟 ChatGPT 随口一聊,它不到五分钟就把图搞出来。虽然很粗糙,但着实把我惊到了。
于是这两周在 Codex 里断断续续打磨 Skill,过程中除了主要的 skill.md 文件,都没怎么看过它生成的各种脚本代码。就这么一路聊过来,提需求、找问题、反馈迭代,稳定跑起来。
很多时候,是人的认知视野和想象力限制了 AI 的发挥空间。不是它做不到,而是你以为它做不到。
只要能把"定义需求——AI 执行——测试结果——反馈问题——AI 执行"这个链路中 AI 以外的部分做好,理论上可以做出任何想要的 Skill,甚至更复杂的产品。不设限,大胆给 AI 提要求,也许就会迸射出意想不到的火花。