Claude Fable 5 的定价是每百万输出 token 50 美元。上线三天即告失败。而 DeepSeek-V4-Pro 的价格是 0.87 美元——仅为前者的五十七分之一。
Anthropic 最强模型暂时退场,但 AI 领域的价格战不仅没有停止,反而愈演愈烈。据报道,全球已有超过 500 家企业从闭源模型切换到了开源模型,其中最大的赢家正是 DeepSeek。
「Tokenmaxxing」:疯狂刷 token 的时代
过去半年,硅谷流行起一个新词:Tokenmaxxing——Token + Max,疯狂刷 token。今年 4 月和 5 月,约 300 家上市公司在财报电话会上讨论了 AI token 成本问题,而一年前这个数字仅为 93 家。
云存储公司 Box CEO 表示,token 预算已成为公司内部"最重要、也最激烈"的话题。加拿大皇家银行 CEO 透露,公司 token 用量在半年内暴增 500%。甚至有的公司内部搞起了"Claudeonomics"排行榜,按 token 消耗量给员工排名。
AI 编程工具 Factory 的 CEO 透露,一家顶级金融机构的高管向他吐槽:员工每月 token 开销高达几十万美元,有人拿最贵的旗舰模型回答最简单的问题,甚至用来闲聊。
账单来了:AI 预算的残酷现实
Uber 去年 12 月全员推广 Claude Code,三个月后工程团队使用率从 32% 飙升至 84%。但到今年 4 月,全年 AI 预算就已经花光。每个工程师每月 API 费用在 500 到 2000 美元之间。Uber COO 公开质疑:"投入和产出之间的关联性,目前还没有建立起来。"
Meta CTO Andrew Bosworth 在内部提醒员工:"不要为了用 AI 而用 AI,token 用量不等于工作成果。"
微软 将于 6 月底前收回部分团队的 Claude Code 权限,统一切换到自家 GitHub Copilot CLI。
最扎心的一组数据来自 Entelligence AI。他们分析了 2000 多家企业的代码库,覆盖超过 100 万次代码提交:
"企业花在 AI token 上的每一块钱,只有 1 毛 8 最终变成了用户手里的产品。"
剩下的钱去哪了?44% 花在修复 AI 自己写出来的 bug,27% 用在返工和重写,11% 消耗在代码审查。每周写的代码里,四分之一直接就被扔掉了。代码提交量 12 周内翻了 2.6 倍,但回滚量同样增长了 3.7 倍。


OpenAI CEO Sam Altman 在 6 月初的企业客户活动上表示,token 成本"突然变成了一个大问题"。OpenAI 最大的一个企业客户,每月消耗约 1000 亿个 token——几年前,全球最多的客户每月才 10 万个,增长了 100 万倍。
企业的反应:不止"省钱",还有"换人"
AI 助手创业公司 Lindy 两个月前开始测试 DeepSeek-V4,发现处理邮件、管理日程、记录会议的效果不输 Claude Sonnet 4.6,邮件分类甚至更好。关键是便宜了 10 倍。Lindy 最终把全部 AI 用量切换到了 DeepSeek,只有内部编程任务还在用 Anthropic 的更强模型,每年能省下几百万美元。
在 Vercel 平台上,DeepSeek 的 token 份额从 4 月的不到 1% 飙升到 5 月的 17%。在 OpenRouter 上,DeepSeek 从 5 月中旬开始成为使用量最大的 AI 公司。开源模型的使用量增速是闭源模型的 4 倍。
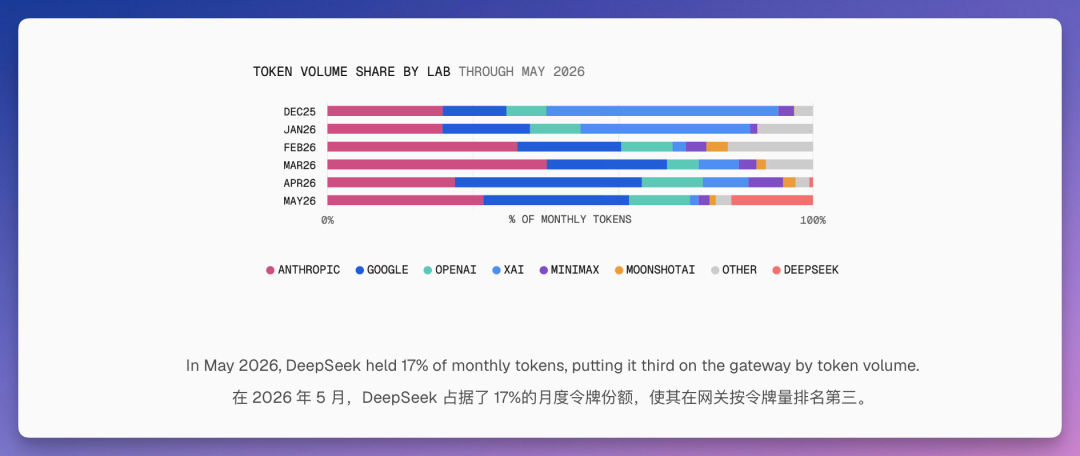
国产模型占了平台 token 总量的近一半——一年前这个数字不到 2%。在 Vercel 的 AI 编程场景里,DeepSeek 处理了 49% 的工作量,但只花了 4% 的钱。Anthropic 处理了 28% 的工作量,却花了 70%。
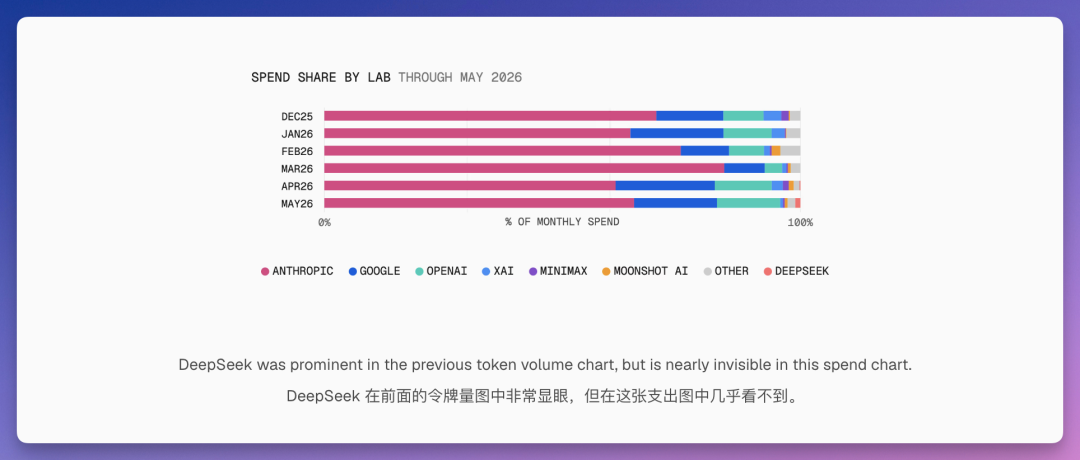
不只是 DeepSeek。阿里 Qwen 系列下载量接近 10 亿次,占全球开源模型下载量的一半以上。开源 AI 生态正在以肉眼可见的速度壮大。
混合模型:未来的 AI 支出策略
不是所有企业都一刀切。更多公司选择了"混合使用模型"。
Factory 搭建了一套自动调度系统:AI Agent 接到任务后,简单任务用便宜模型,复杂任务调用 Claude 或 GPT。这套系统最多可以把 AI 成本降低 95%。Factory 今年 4 月完成了 1.5 亿美元 C 轮融资,估值 15 亿美元。
前谷歌云负责人 Andrew Moore 创办的 Lovelace AI 思路类似:"我们的 AI Agent 现在特别抠门。它们知道怎么从最便宜的模型里榨出结果。搞不定的时候,才临时跳到更贵的模型上。"
专门检测代码 bug 的创业公司 Detail,已将 90% 的工作量从 Claude 和 Gemini 转移到了自研模型和智谱 GLM 系列上。
苏米注:从"一个旗舰模型打天下"到"大模型思考、小模型干活"的混合架构,是企业 AI 应用的必然演进。这不是降级,而是成熟。就像云计算从"所有负载跑在最大实例"演进到了自动扩缩容,AI 模型调度也会走向精细化。
市场用脚投票
开源模型曾经是"平替",现在它们变成了"首选"。OpenAI 感受到了压力,据报道正在考虑大幅降低 token 价格。Anthropic 则回应称,企业更在意的是完成任务的总成本,而非每个 token 的单价——旗舰模型处理复杂任务时用的 token 更少,总成本不一定高。
但市场已经做出了选择。微软近期发布了更小、更高效的 AI 模型。英伟达推出了 Nemotron 系列,定位平价替代。连芯片公司都在帮企业省钱。

一份投行研报追踪的全球 AI 支出指数连续 7 天下跌,创下今年以来最长下跌纪录。但 AI 本身的需求并没有放缓——谷歌云每月处理超过 3200 万亿个 token,是一年前的 7 倍。
增长没停,是增长的方式变了。便宜模型处理大部分任务,旗舰模型只在关键时刻上场。这可能是更有"性价比"的方式。