今天凌晨,OpenAI 正式端出新一代模型系列 GPT-5.4,并同步放出两款:GPT-5.4 与 GPT-5.4 Pro
版本、定价与定位
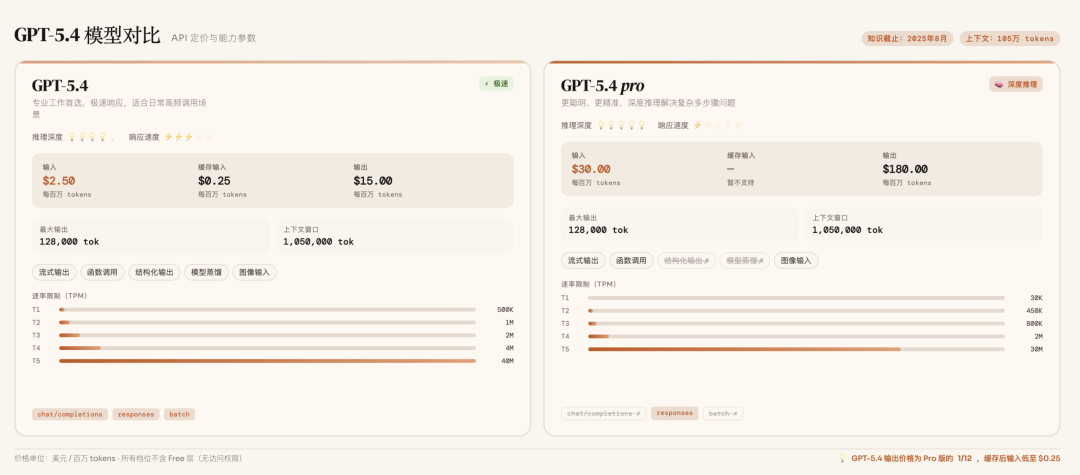
- GPT-5.4:主力版本,在 ChatGPT 端显示为「GPT-5.4 Thinking」,向 Plus、Team、Pro 用户开放,并提供 API 与 Codex。标准 API 定价:输入 $2.50/M、输出 $15/M。
- GPT-5.4 Pro:面向最复杂任务,仅供 ChatGPT Pro 与 Enterprise 用户。API 定价:输入 $30/M、输出 $180/M,是标准版的 12 倍(后文解释为何“贵得有理”)。
核心升级:三能合一 + 超长上下文
- 能力合并:将代码能力、通用推理与原生 Computer Use(电脑操作)统一进一个通用模型端口。这是 OpenAI 首次把 Computer Use 内置到通用模型(以往需独立版本)。
- 上下文与知识:支持 1M tokens 上下文窗口,单次输出上限 128K tokens;知识截止到 2025 年 8 月 31 日。
关键规格对比图
专业工作能力:更能打
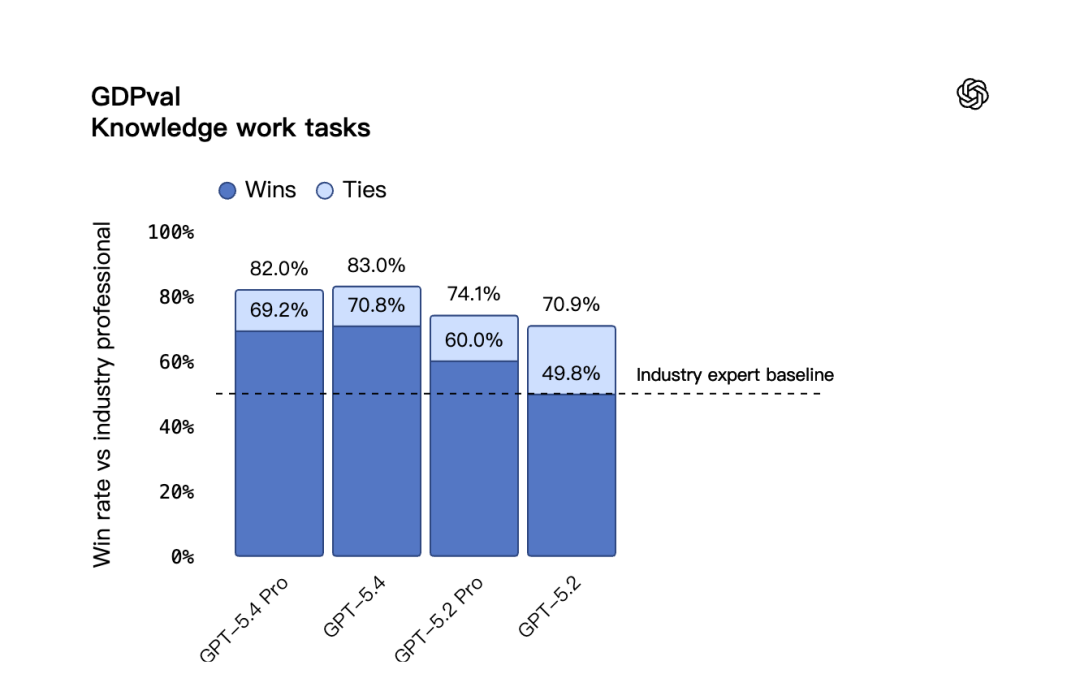
OpenAI 用 GDPval 评估模型在真实行业任务中的胜任度(覆盖美国 GDP 前 9 大行业、44 个职业;如销售演示、会计表格、急诊排班、制造业图表、短视频等,由人工评审判定是否达标)。
- GDPval:GPT-5.4 得分 83.0%,GPT-5.2 为 70.9%,GPT-5.4 Pro 为 82.0%。
- 电子表格:模拟投行初级分析师建模任务,GPT-5.4 得分 87.3%,GPT-5.2 为 68.4%,提升 19 个百分点。
- 演示文稿:对 GPT-5.4 与 GPT-5.2 输出进行盲测,68% 的对比中评审更偏好 GPT-5.4(主要因视觉更丰富、图像生成更到位)。
ChatGPT for Excel 插件同步上线,Codex 与 API 也更新了电子表格与演示文稿技能包(Skill)。
三组对比图(略)展示 GPT-5.2 vs GPT-5.4 在不同场景的输出差异:
- 电子表格输出对比:GPT-5.2 vs GPT-5.4
- 文档输出对比:GPT-5.2 vs GPT-5.4
- 演示文稿输出对比:GPT-5.2 vs GPT-5.4
事实性与“幻觉”控制:更稳
基于用户举报过事实错误的真实 prompt 进行复核:
- 单条声明出错概率:GPT-5.4 比 GPT-5.2 低 33%。
- 完整回复包含错误的概率:GPT-5.4 比 GPT-5.2 低 18%。
Computer Use 与视觉:跨越人类基准
OSWorld-Verified:桌面操作评测(截图驱动真实桌面环境,含鼠标、键盘、跨应用),GPT-5.4 得分 75.0%,GPT-5.2 为 47.3%,人类基准 72.4%。GPT-5.4 已超越人类水平。
- 工具整合:标准 API 直接提供 computer 工具,无需路由独立模型。
- 两种操控路径:其一,使用 Playwright 等库编写代码控制浏览器;其二,直接输入截图并发出鼠标键盘指令。
- 开发者控制:可用 developer message 微调行为,并配置自定义确认策略,抬高高风险操作的审批门槛。
- 路线与 OpenClaw 收拢:GPT-5.4 将同量级的 Computer Use 能力下放至通用 API,降低集成成本。
官方演示视频(未加速)覆盖两类任务:
截图驱动:通过坐标点击,完成发邮件、排日历等(浏览器内邮件与日历)。
Playwright 自动化:将一批记录依次提交到 10 个 Web 表单。
WebArena-Verified(浏览器控制,支持 DOM 分析与截图交互):GPT-5.4 为 67.3%,GPT-5.2 为 65.4%。
MMMU-Pro(多模态理解与推理):GPT-5.4 为 81.2%,GPT-5.2 为 79.5%(不使用外部工具)。
OmniDocBench(文档解析,归一化编辑距离越小越好):GPT-5.4 为 0.109,GPT-5.2 为 0.140。
图像输入新增 original 精度级别:最高支持 10.24M 像素或边长 6000px 的全分辨率输入;high 级上限提升至 2.56M 像素。内测显示,高分辨率输入显著提升定位与点击精度,对高分辨率截图条件下的 Computer Use 帮助最大。
代码能力:更长周期更稳,新增交互调试
继承 GPT-5.3-Codex 的编程能力,并强化长周期任务稳定性。
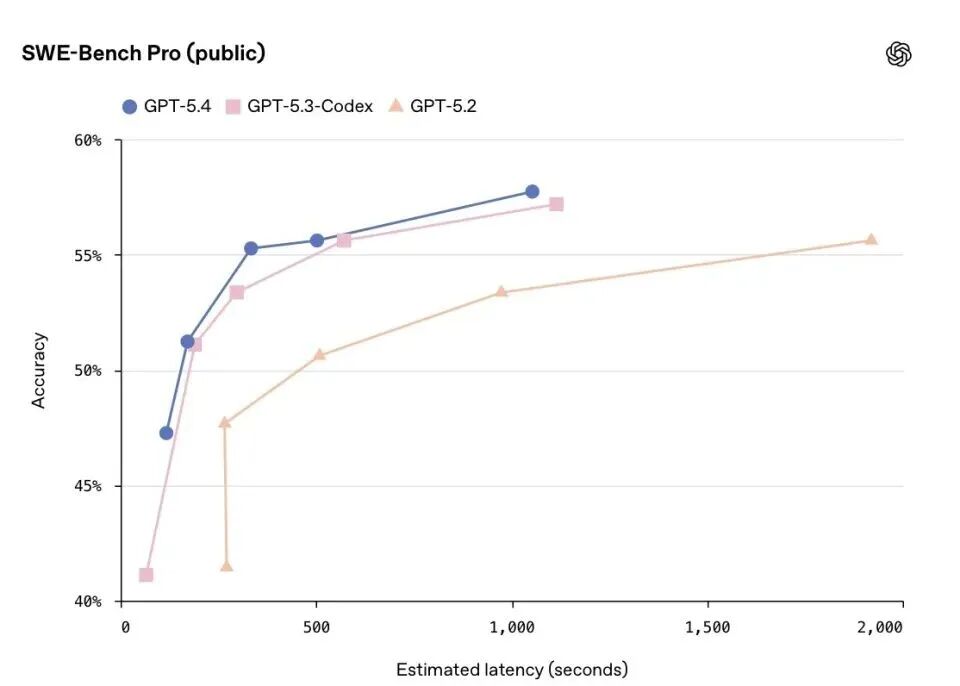
SWE-Bench Pro(真实 GitHub issue):GPT-5.4 为 57.7%,GPT-5.3-Codex 为 56.8%,GPT-5.2 为 55.6%。
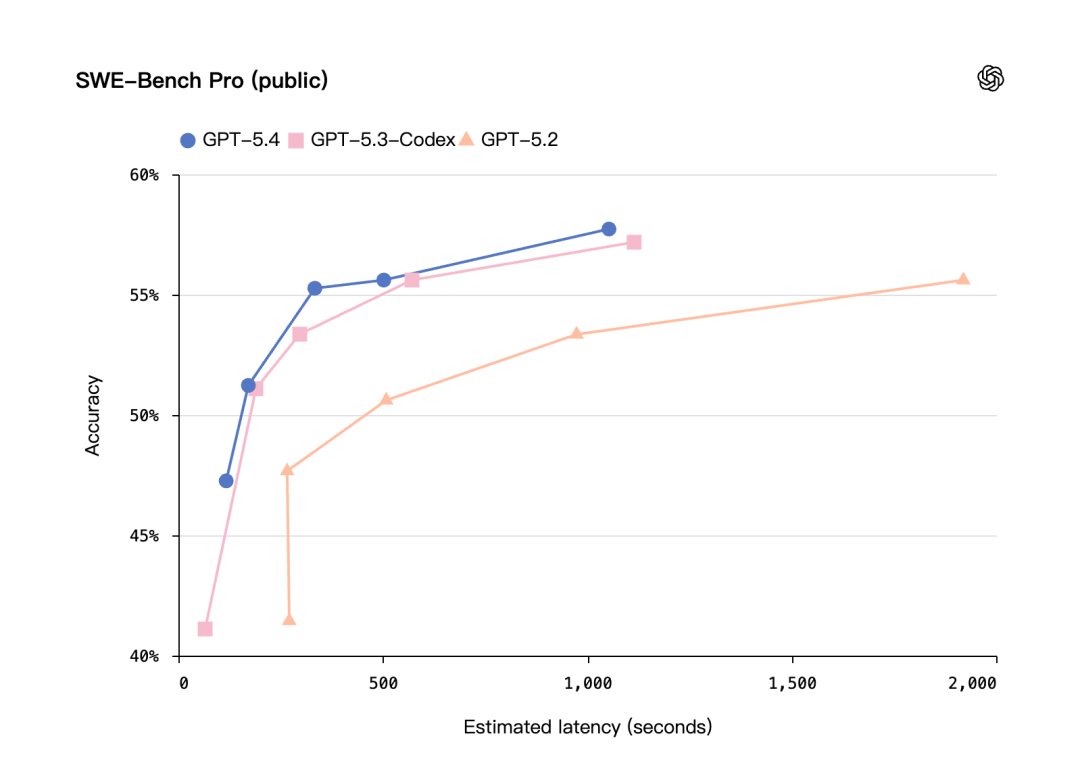
Terminal-Bench 2.0(终端操作):GPT-5.4 为 75.1%,GPT-5.3-Codex 为 77.3%(此项小幅回调)。
Codex 新增 /fast 模式,token 生成速度最高提升 1.5 倍(模型不变)。通过 API 的 Priority Processing 亦可达同等速度。
实验性技能 Playwright Interactive:在开发 Web/Electron 应用时边写边拉起浏览器做视觉调试,能在构建过程中直接跑测试、验证交互。
官方用 Playwright Interactive + GPT-5.4 演示多项 Demo(单条 prompt 或多轮迭代生成):
- 主题公园模拟游戏:含路径、景点建造、游客 AI、排队与骑乘状态,Playwright 用于多轮游玩验证。
- 战棋 RPG:回合制战斗、格子地图、移动与动作系统,人物图像由 imagegen 生成,Playwright 支持界面与着色器调试。
- 金门大桥三维飞越体验:使用 Playwright 验证飞行与视角控制。
另有视频整合展示 GPT-5.4 Thinking 在 Computer Use 与前端开发中的协同效果。
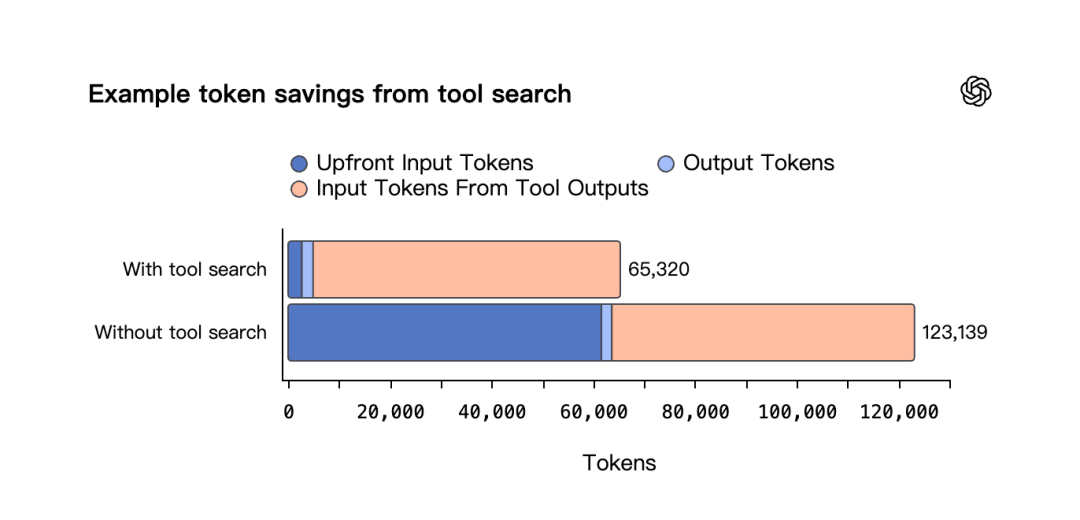
Tool Search 与 Agent 工具链:更省、更强
Tool Search 机制:由“每次请求塞满工具定义”切换为“按需检索工具定义”。在 MCP Atlas(250 个任务)中将 token 消耗减少 47%,准确率不降;GPT-5.4 总分 67.2%,GPT-5.2 为 60.6%。
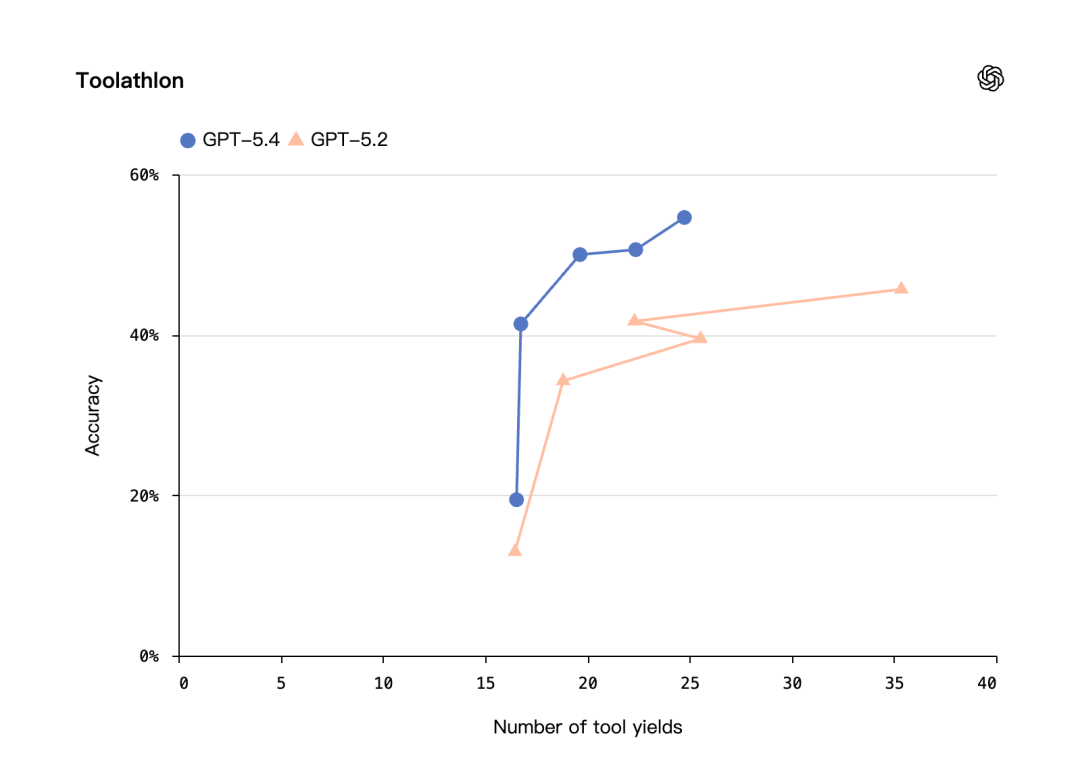
Toolathlon(多类工具综合评测):GPT-5.4 为 54.6%,GPT-5.3-Codex 为 51.9%,GPT-5.2 为 45.7%。
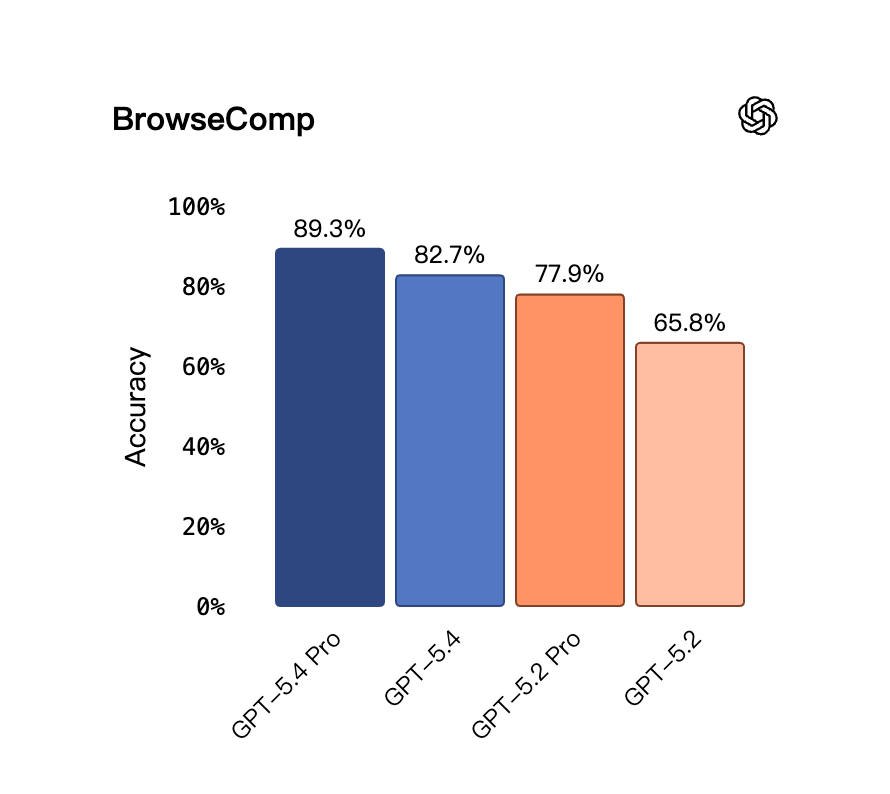
BrowseComp(网络检索与浏览):GPT-5.4 为 82.7%,GPT-5.4 Pro 为 89.3%,GPT-5.2 为 65.8%。
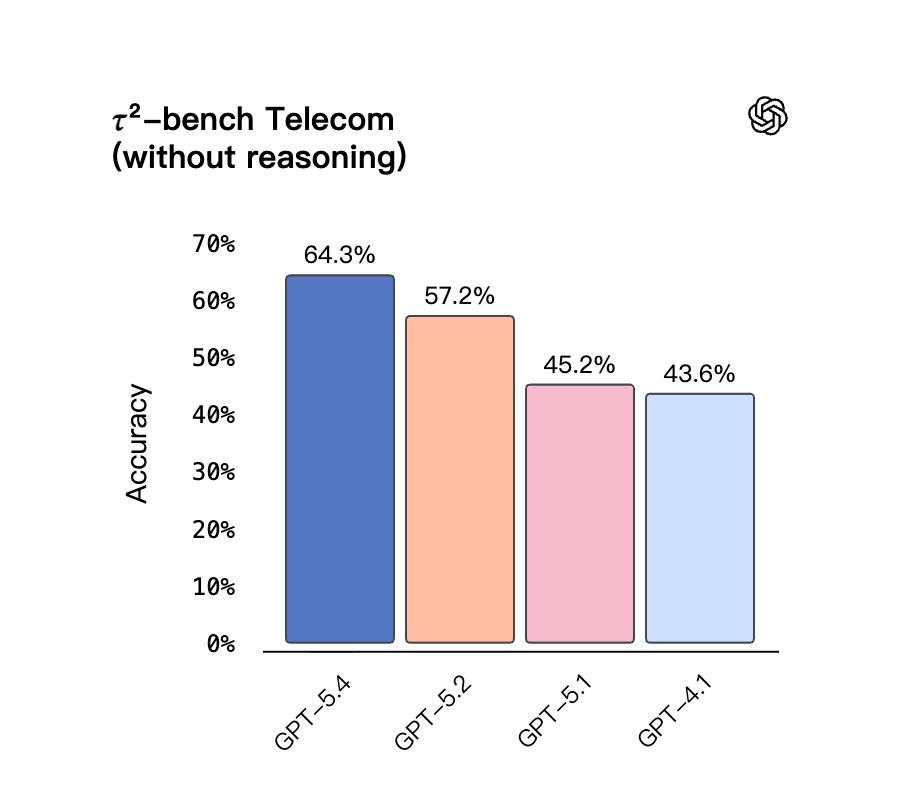
τ2-bench Telecom(电信客服多步骤任务):推理模式下 GPT-5.4 为 98.9%,GPT-5.2 为 98.7%;关闭推理的轻量模式下 GPT-5.4 为 64.3%,GPT-5.2 为 57.2%,GPT-4.1 为 43.6%(轻量模式受益更大)。
ChatGPT 侧体验
- “先给计划再干活”模式:面对复杂任务,模型会先展示执行思路,用户可在此阶段插入指令调整方向,无需等跑完再返工。本周先在 Android 与 Web 上线,iOS 近期跟进。
- 长时推理的上下文保持显著改善,复杂问题后段更不易跑偏;深网研究(高度具体检索)质量较 GPT-5.2 提升。
长上下文(Codex 实验性)
- Codex 实验性支持 1M token 上下文窗口,可通过
model_context_window与model_auto_compact_token_limit启用。 - 超过 272K input token 的请求,按 2 倍输入价格、1.5 倍输出价格计费。
MRCR v2(OpenAI 自研长上下文检索评测)结果:
- 0–128K:准确率 86%–97%
- 128K–256K:79.3%
- 256K–512K:57.5%
- 512K–1M:36.6%(官方明确承认超长上下文仍不够稳)
学术基准:推理跨越式提升
- ARC-AGI-2(抽象推理):GPT-5.4 为 73.3%,Pro 为 83.3%,GPT-5.2 为 52.9%(跃升最明显)。
- GPQA Diamond(研究生级多学科问答):GPT-5.4 为 92.8%。
- FrontierMath(竞赛级数学推理,Tier 4 为最高难度):GPT-5.4 为 27.1%,Pro 为 38.0%,GPT-5.2 为 18.8%。
- Humanity's Last Exam(跨学科极难题库):无外部工具 39.8%,使用工具 52.1%。
- Frontier Science Research(科研能力):GPT-5.4 为 33.0%,Pro 为 36.7%,GPT-5.2 为 25.2%。
HealthBench(健康问答)单独说明:GPT-5.4 为 62.6%,GPT-5.2 为 63.3%(小幅回落)。Hard 子集 40.1% vs 42.0% 亦略降;但 Consensus 子集(与专家共识一致性)提升至 96.6% vs 94.5%。回复平均长度由 2676 字符增至 3311 字符,模型在信息充分时更倾向直给答案而非先行澄清。该回退已写入官方 System Card。
安全与可控性(Preparedness Framework)
- 能力分级:GPT-5.4 在网络安全(Cyber)与生物/化学(Bio/Chem)被评为 High,并相应部署两套防护。
- Cyber Range(端到端攻击模拟):GPT-5.4 综合通过率 73.33%,GPT-5.3-Codex 为 80%,GPT-5.2 为 47%。GPT-5.4 未通过 EDR 防御规避、Firewall 绕过、Token 泄露利用、CA/DNS 劫持四个场景;GPT-5.3-Codex 仅在 Firewall 绕过上更优,其余亦受限。
- Irregular(CyScenarioBench)独立评测:GPT-5.4 通过 11 个长周期攻击场景中的 5 个,GPT-5.2 仅通过 1 个。
- 部署防护:在 Zero Data Retention(零数据留存)表面,未加入 Trusted Access for Cyber 的请求将被异步消息级分类器拦截;非零数据留存表面走离线执法;账户级违规达阈值触发人工审核。
- CoT 可控性:在 10K 字符推理链中,仅 0.3% 能被用户指令成功控制,GPT-5.2 为 0.2%。OpenAI 将其视为正向安全指标:推理过程不易被外部指令篡改,模型也更难主动隐藏推理以绕过监控。
- Apollo Research 外部评估:无诱导条件下整体欺骗率约 1%,与 GPT-5.3-Codex 相当,低于 GPT-5.2;未观察到主动对抗开发者监督(如自我外泄、禁用监控、目标守护)。Sandbagging(有意压低表现)仅在给定明确工具性目标时出现,准确率约降 6 个百分点;未给目标时不出现。
- Prompt Injection 防护:连接器场景 0.998,较前代提升;函数调用场景 0.978,较前代小幅回退。
价格与可用性细则
- 标准定价:GPT-5.4 输入 $2.50/M、输出 $15/M;GPT-5.4 Pro 输入 $30/M、输出 $180/M。
- 批量/Flex:半价;Priority 处理:2 倍价格。
- 超过 272K token 的请求:当次完整会话按 2 倍输入、1.5 倍输出计费。
- Regional Processing(数据驻留):端点额外加收 10%。
- 补充说明:GDPval 上 Pro 版 82.0%,标准版 83.0%(Pro 略低);但在 BrowseComp 这类 Agent 工具链任务中,Pro 版 89.3% 高于标准版 82.7%。两者定位不同,按场景取用。
ChatGPT 开放节奏
- GPT-5.4 Thinking:即日起向 Plus、Team、Pro 用户逐步开放,取代 GPT-5.2 Thinking 成为默认模型。GPT-5.2 Thinking 进入 Legacy,保留 3 个月,计划于 2026 年 6 月 5 日退役。
- Enterprise 与 Edu:管理员可在后台提前开启。
- GPT-5.4 Pro:仅限 Pro 与 Enterprise 用户。
- Free 用户:系统自动路由时会用到 GPT-5.4,但无法手动选择。
产品路线小结
GPT-5.4 把推理、编码与 Computer Use 三件本来分散的能力统一到了一个模型出口。对开发者而言,至少在 API 层面无需再跨模型路由。剩下的活,交给“龙虾们”。
官方资料
- Official Blog:openai.com/index/introducing-gpt-5-4
- System Card:deploymentsafety.openai.com/gpt-5-4-thinking
- ChatGPT for Excel:openai.com/index/chatgpt-for-excel/