最近在体验各类深度调研产品时,我发现了一个普遍的矛盾:想要获得顶级的报告生成能力,就必须依赖云端大模型,这意味着核心数据需要上传到互联网;而选择本地部署来保证数据安全,生成的报告往往逻辑浅薄、难以应用于实际决策。
对于手握公司战略规划、未公开财务数据或科研机密的专业人士来说,这确实是个两难选择。
直到最近,我发现了一个有意思的开源项目——AgentCPM-Report,它试图用一个新思路来破解这个困局。
项目概览
AgentCPM-Report 是由清华大学自然语言处理实验室、中国人民大学、面壁智能与 OpenBMB 开源社区联合研发的深度调研智能体系统。它的核心定位是:一个可完全本地化部署、无需联网、性能媲美顶级闭源系统的报告生成工具。

这个项目的价值在于,它用 8B 参数规模的端侧模型,通过创新的架构设计,达到了与顶级闭源深度调研系统相当的性能表现——这在开源领域相对罕见。
核心功能特性
1. 性能基准对标
在 DeepResearch Bench、Deep Consult、DeepResearch Gym 三大主流评测基准中,AgentCPM-Report 的综合表现值得关注:
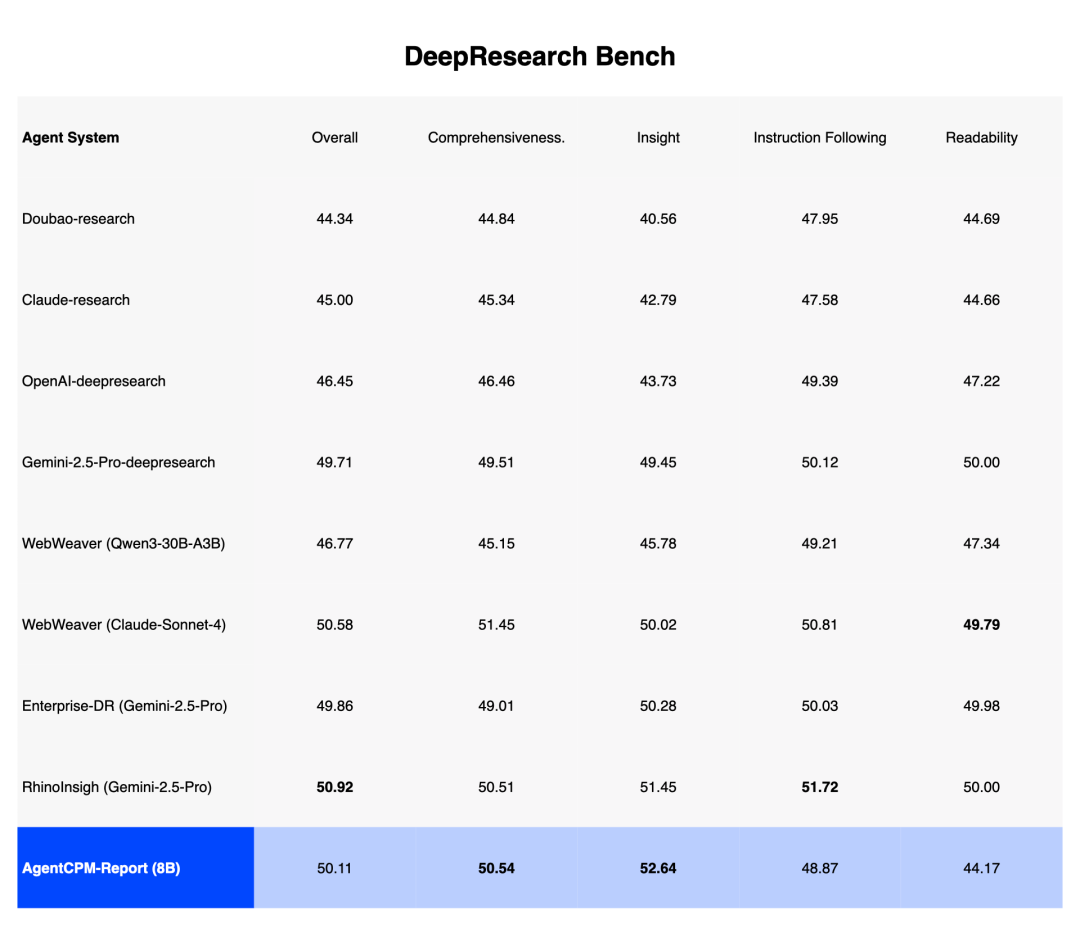
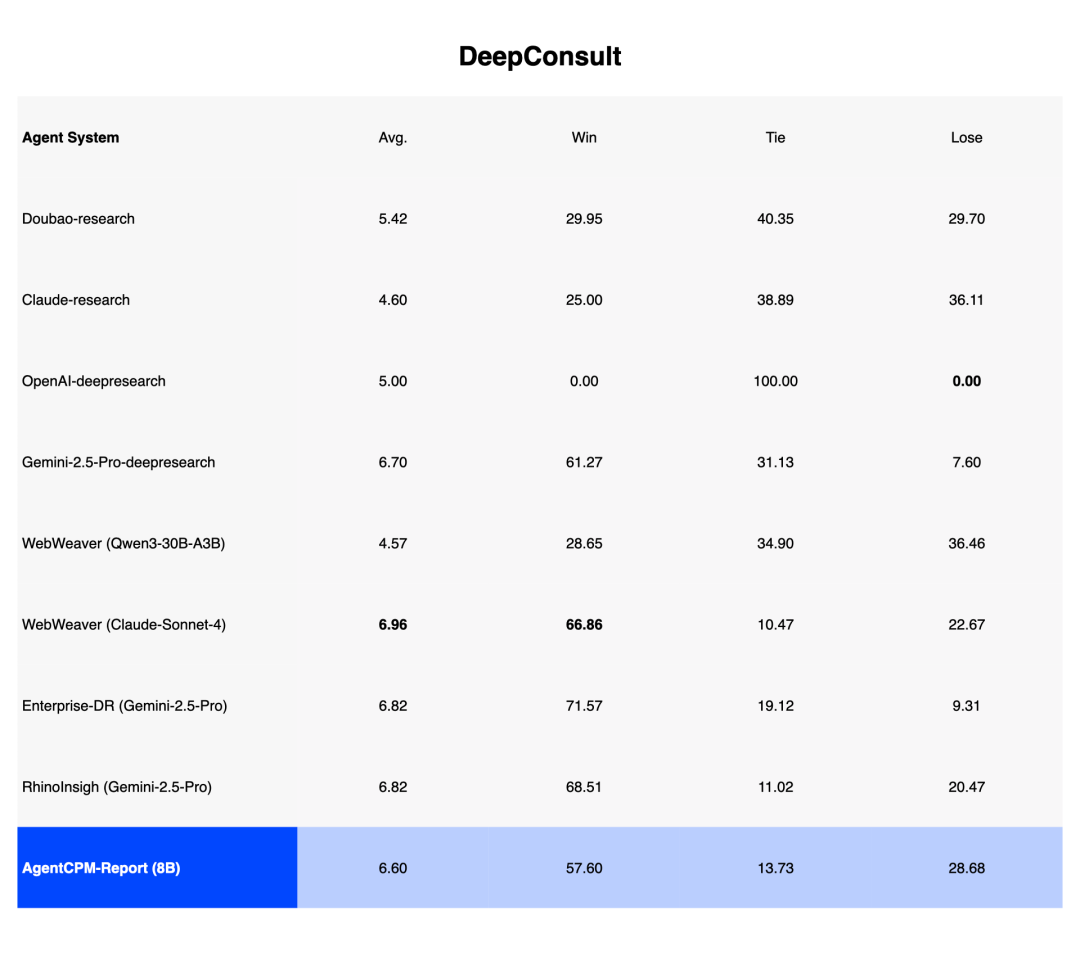

- 在洞察性(深度)指标上排名第一,这反映了生成报告的思维深度
- 在全面性指标上位居第一梯队,仅次于基于 Claude 的商业方案
- 相比参数规模,性能提升比例较为突出
2. 隐私隔绝设计
物理隔绝是这个项目的核心卖点。系统支持:
- 完全离线部署,无需任何网络连接
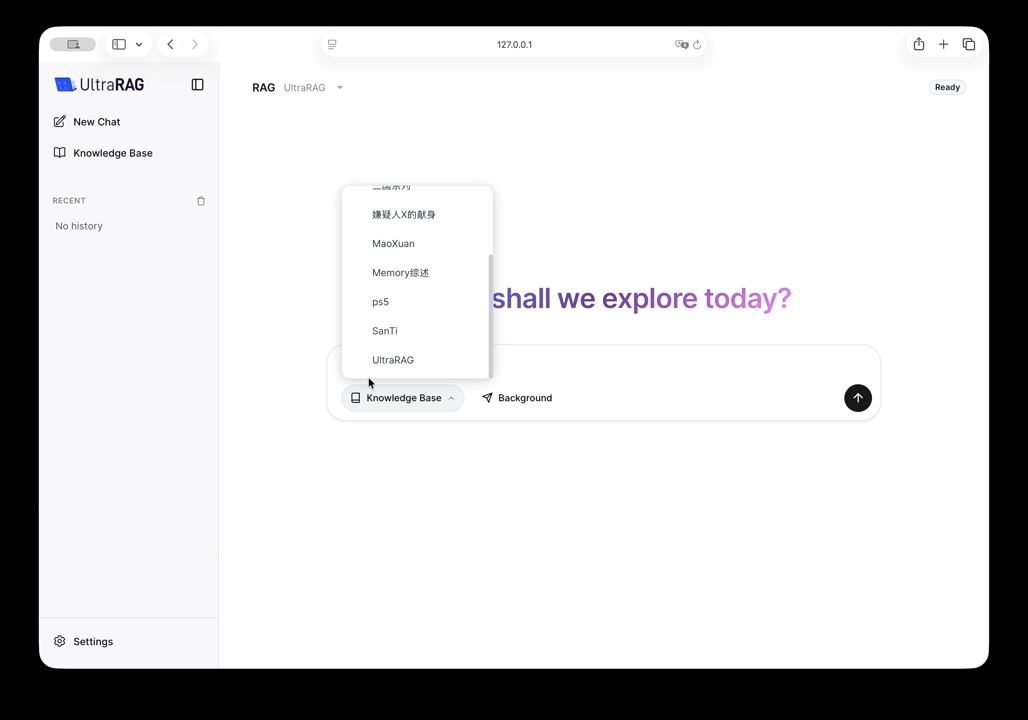
- 基于 UltraRAG 框架,支持本地知识库挂载
- 用户数据完全保留在本地磁盘,不经过任何云端
3. 报告生成流程
系统通过以下步骤生成深度报告:
- 平均 40 轮深度检索,确保知识库中的相关信息被充分挖掘
- 近 100 轮思维链推演,逐步构建逻辑框架
- 生成结构化、带引用的专业长文(通常为万字级别)
技术方案解析
我认为这个项目的技术创新值得关注,因为它提供了一个有参考价值的思路——如何让小参数模型处理复杂任务。
创新设计一:"写作即推理"的迭代框架
传统方案让模型一次性生成完整大纲或内容,容易导致逻辑崩坏。AgentCPM-Report 采用了"边写作、边规划"的策略:
- 两阶段循环:系统在"起草"与"深化"两个状态间交替。这类似于人类专家写作的方式——先产出草稿,然后反思"还需要补充什么",再回头扩展和优化
- 任务拆解:将万字长文拆解为一系列可执行的微观目标。模型在每一轮只需解决局部问题,而非全局规划,降低了认知负担
创新设计二:多阶段智能体学习
训练过程分为两个维度:
能力拆解(四个核心模块)
- 智能检索能力:以召回率为核心优化指标,确保检索结果的相关性
- 流畅写作能力:多维度质量评估,从内容深度到表达清晰度全面把关
- 科学规划能力:对生成的大纲结构进行评估,确保逻辑严谨、层次分明
- 精准决策能力:采用"轨迹剪枝"技术,解决"何时停止深化"的关键决策问题
训练阶段(三层递进)
- 有监督微调:用高质量范文引导基础写作范式
- 原子能力强化:针对每项能力的专项优化
- 全流程优化:端到端强化学习,以最终报告质量为唯一目标
部署与使用
安装流程
整个部署方案相对简洁:
- Docker 一键启动:通过 Docker 拉起 UltraRAG 服务与 AgentCPM 智能体,无需复杂的环境配置
- 知识库构建:支持拖拽式导入 PDF、TXT 等本地文档,系统自动完成分割与向量化索引
- 调研执行:输入研究课题,智能体自动生成结构化报告
适用场景
基于其隐私优先和本地部署的特性,该系统适合以下场景:
- 企业战略分析:处理未公开的内部数据进行战略规划
- 科研报告撰写:基于私密研究数据生成学术报告
- 财务分析:在本地环境中处理敏感的财务数据进行深度分析
- 合规文档生成:在数据不出域的前提下完成合规性调研报告
- 内容创作:为个人或小团队提供深度调研辅助
相关项目对比
在开源生态中,AgentCPM-Report 与以下项目的定位略有不同:
| 项目 | 主要差异 | 适配场景 |
|---|---|---|
| AgentCPM-Report | 端侧模型、本地部署、深度调研专向 | 隐私敏感、需要深度报告的企业/科研 |
| LlamaIndex | 通用 RAG 框架,模型无关 | 灵活的知识库检索应用 |
| Dify | AI 工作流编排平台 | 多模型协作、流程自动化 |
| OpenBMB 其他项目 | 面向基础模型能力增强 | 具体能力任务(总结、翻译等) |
从功能对标来看,AgentCPM-Report 在"深度调研报告生成"这一垂直领域做得比较专注,而不是通用 RAG 框架。
使用建议
基于我对该项目的理解,这里给出几点使用上的建议:
- 硬件要求:8B 模型的推理需要足够的显存(通常建议 16GB+ GPU 或 CPU 推理环境),部署前需评估本地硬件条件
- 知识库质量:报告质量很大程度取决于上传的私有文档质量和覆盖度,建议预先整理和验证源文档
- 迭代优化:第一次运行后,可根据生成报告的不足调整输入的研究课题描述,以获得更符合需求的输出
- 适配场景评估:该系统最适合处理有明确知识库边界的调研任务。如果需要实时网络信息整合,可能需要与其他数据源结合
总结与思考
作为一名长期接触 AI 产品的产品经理,我认为 AgentCPM-Report 代表了一个有意思的方向——用创新的架构设计来弥补端侧模型的性能差距。
它的核心价值不在于"最强",而在于找到了隐私保护与能力表现之间的可行平衡点。对于那些数据敏感但又需要高质量调研报告的组织来说,这个选项具有实际意义。
从开源生态的角度,这个项目也展示了国内团队在大模型应用层的探索进度。将如此复杂的能力集成到本地系统中,并实现性能对标,这在 2024 年是有说服力的。
如果你的工作涉及数据隐私要求较高的深度调研,不妨按照项目提供的教程本地部署体验一下。项目的代码和模型已在多个平台开源(GitHub、HuggingFace、ModelScope 等),上手成本相对较低。
相关资源
- GitHub:https://github.com/OpenBMB/AgentCPM
- HuggingFace:https://huggingface.co/openbmb/AgentCPM-Report
- ModelScope:https://modelscope.cn/models/OpenBMB/AgentCPM-Report
- UltraRAG 框架:https://github.com/OpenBMB/UltraRAG