最近在梳理GitHub上的AI Agent项目时,我注意到一个有趣的现象:很多开源项目都在追逐通用性和大而全,但真正解决具体痛点的反而显得稀缺。
ChatLab就属于后者——它专注于一个非常具体的需求:如何将非结构化的聊天记录转化为可分析、可理解的数据资产。作为经常接触各类数据分析工具的PM,我认为这个项目很值得关注。
项目定位与核心价值
ChatLab是一个本地化部署的聊天记录分析平台,定位明确:帮助用户对已导出的即时通讯数据进行结构化分析和智能挖掘。
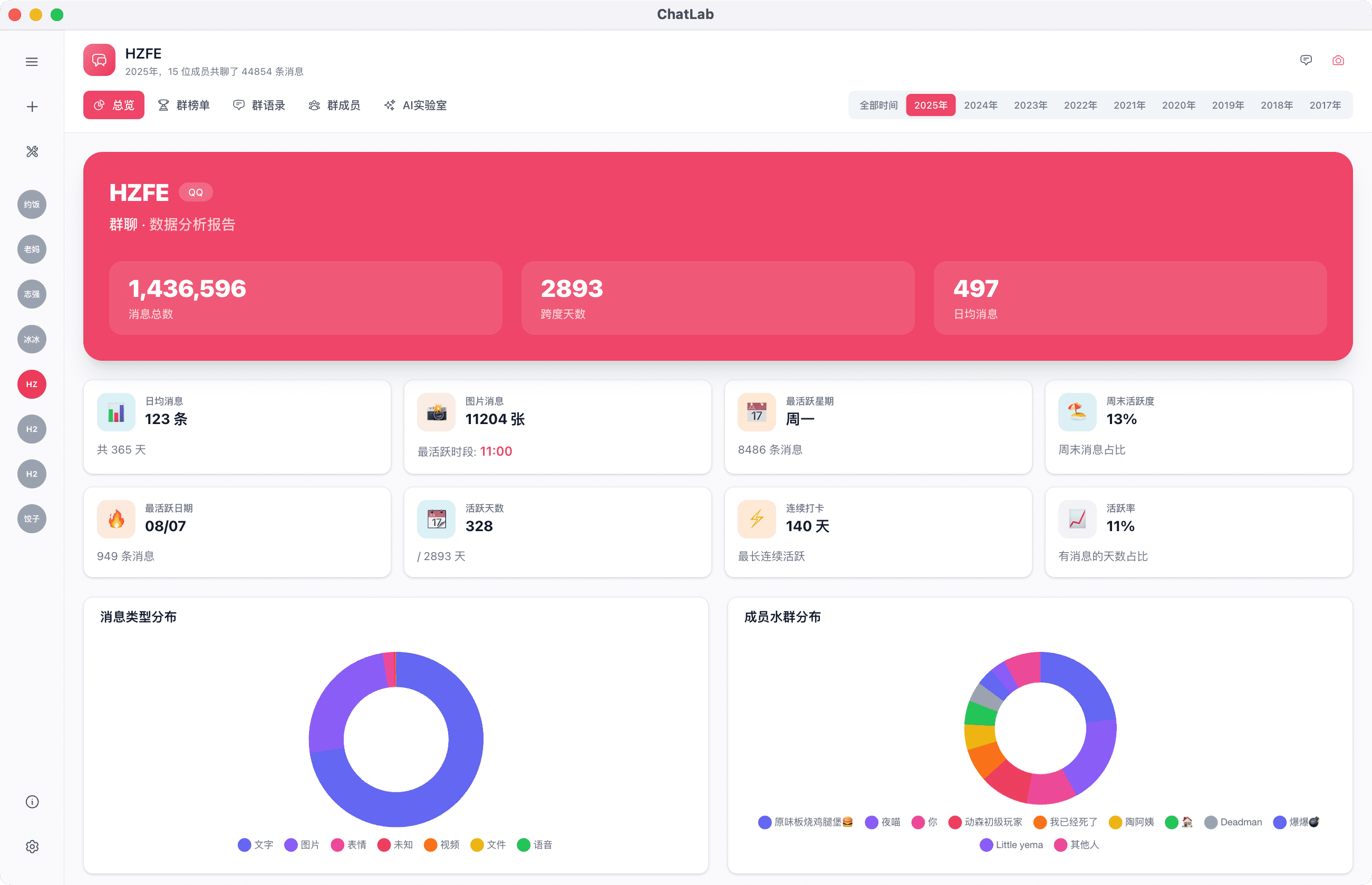
与许多试图做"全能工具"的项目不同,它的约束非常清晰——
- 仅支持对已导出数据的分析,不涉及数据抓取
- 核心计算在本地进行,涉及AI功能时才调用外部模型
- 支持多平台(微信、QQ、Telegram等)的数据统一处理
这种克制的设计反而让它的定位更清晰、使用门槛更低。
核心功能模块

1. 性能与基础设施
- 采用流式计算 + 多线程架构,可处理百万级聊天记录
- 本地数据库存储,避免云端传输带来的隐私风险
- 标准化数据抽象层,平滑处理不同平台的格式差异
2. 数据分析维度
| 分析维度 | 具体指标 | 应用场景 |
| 用户活跃度 | 发言频率、发言量排行、活跃时段分布 | 识别核心贡献者、理解群体节奏 |
| 内容热度 | 高频话题、传播链路、复读统计 | 捕捉社群热点、识别讨论焦点 |
| 时间规律 | 按小时/天/周的消息分布 | 理解用户使用习惯、群聊活跃规律 |
| 用户画像 | 发言风格、互动模式、关键词偏好 | 初步用户分层、社群结构分析 |
3. AI Agent能力
项目集成10+个Function Calling工具,支持动态调度。这意味着你可以用自然语言向AI提问聊天记录相关的问题,而不仅限于预设的统计维度。例如:
- "最近一个月谁是话题的发起者"
- "找出所有讨论产品反馈的对话片段"
- "分析这个群聊的主要话题演变过程"
这种交互方式对习惯了搜索和问答的用户更加友好。
4. 数据可视化与导出
- 内置多维度可视化图表(趋势图、分布表、排行榜等)
- 年度榜单自动生成
- 表结构全开放,支持自定义SQL查询和二次分析
- 同时支持群聊和私聊数据分析
使用流程与部署
ChatLab的工作流程相对标准化:
- 数据导出:使用平台官方功能或社区提供的第三方工具导出聊天记录
- 数据上传:将导出文件拖入ChatLab的上传区域
- 自动解析:等待系统完成数据抽象和入库
- 分析与挖掘:通过可视化面板或AI Agent进行多维分析
项目提供了详细的导出指南(https://chatlab.fun/usage/how-to-export.html),覆盖主流即时通讯工具的导出方式。
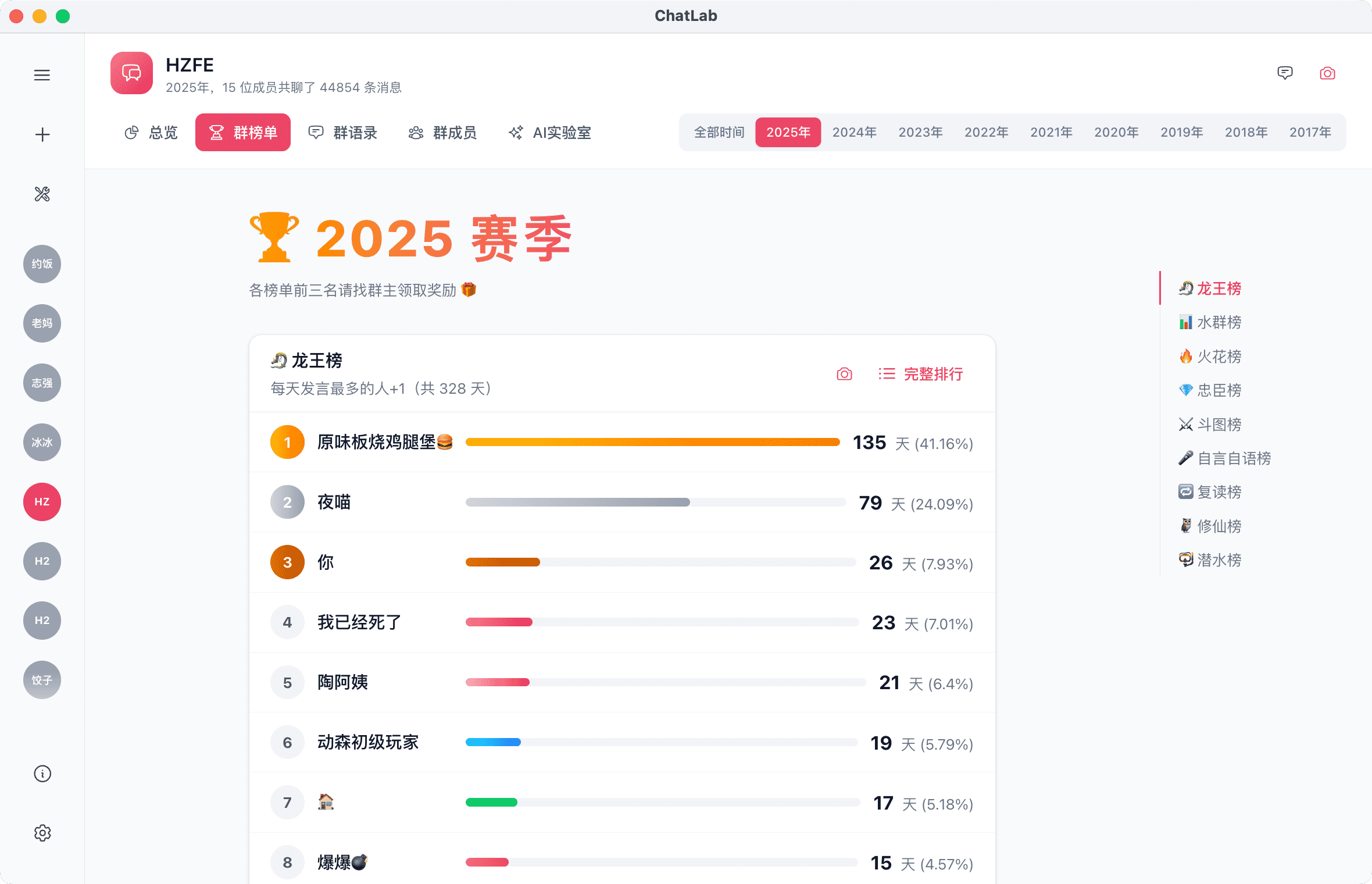
对于技术团队,表结构全开放也意味着可以基于本地数据库进行自定义分析。
典型应用场景
从我接触的案例来看,这类工具的价值主要体现在:
- 社群运营分析:理解群体活跃度、识别核心贡献者、发现讨论热点
- 用户研究:通过真实对话数据进行初步用户画像和需求分析
- 内容审查与合规:快速检索和分析特定主题的对话内容
- 知识提炼:从碎片化的对话中挖掘有价值的讨论和观点
- RAG/知识库构建:将结构化后的聊天记录作为知识源进行向量化存储
如果你之前接触过日志分析、知识库构建或RAG系统,会比较直观地理解这类工具的价值。
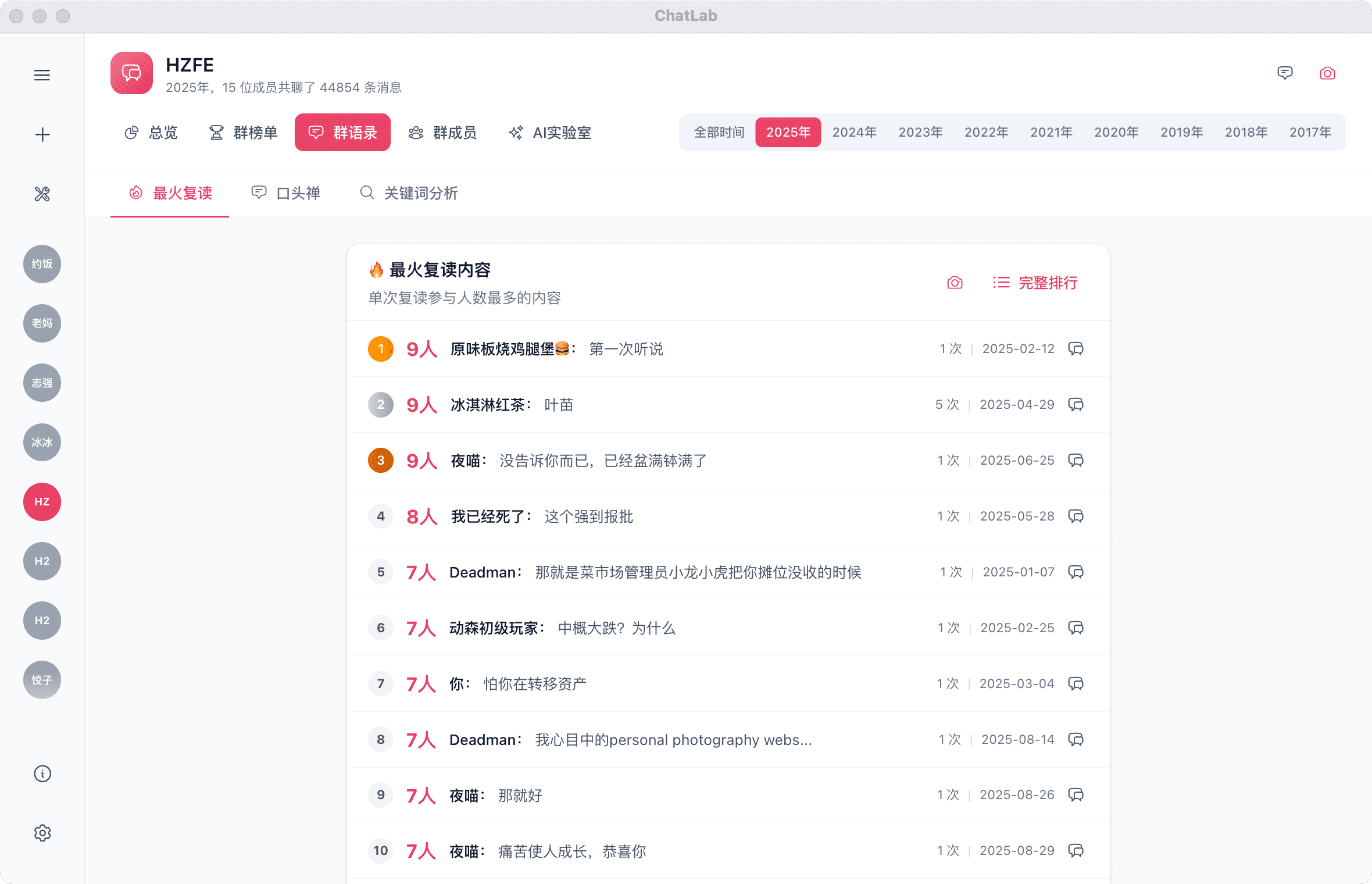
与相似项目的对比参考
在社群数据分析领域,也存在其他方向的工具:
- 通用BI工具(如Metabase):功能更全面,但学习成本高,需要自己定义数据模型
- 即时通讯平台官方分析(如企业微信、钉钉):数据权限受限,功能由平台决定
- 第三方爬虫工具:涉及数据合规性问题,且不提供分析能力
ChatLab的差异化在于:专注于分析层而非数据获取,本地部署避免隐私泄露,降低了使用门槛。
配置灵活性
项目支持:
- 系统提示词的灵活配置(影响AI Agent的分析风格)
- 模型配置自定义(可切换不同的LLM提供商)
- 本地数据库的直接查询和扩展分析
这些特性使得它既适合快速上手的非技术用户,也能满足需要深度定制的数据分析团队。
总结
在大模型时代,我们不缺乏计算能力,缺的是与真实场景结合的想象力。ChatLab没有打着"革命性""必备"这类标签,但它解决的是一个长期被忽略、却极其真实的需求——如何让隐藏在聊天记录里的数据资产被激活。
聊天记录本质上是最真实的人类行为数据。当这些碎片化的对话能被结构化、被分析、被理解时,价值远超表面的"聊天"。无论你是社群运营者、产品经理、数据分析师,还是对本地AI和Agent感兴趣的开发者,这个项目都值得花时间了解。