Claude Code 在 2026 年 5 月底发布的 Dynamic Workflow
它在 SubAgent 体系之上加了一层确定性的 JS 编排,提高了可控性
为什么需要 Workflow
纯 LLM 驱动的多 agent 系统有三个反复出现的失败模式。
第一个是偷懒(Agentic laziness)。让 LLM 依次处理 N 个文件,它可能前几个认真做,后面开始敷衍或直接跳过。任务越多,越容易出现。
第二个是自评偏好(Self-preferential bias)。让同一个 agent 生成结果然后自己打分,它总会给自己高分。这是模型固有的偏差,仅用 prompt 无法避免。
第三个是目标漂移(Goal drift)。长任务里,上下文在 agent 之间传递时,每一次转述都在引入噪音,执行时间越长,原始目标偏离越远。
Dynamic Workflow 的核心思路是用代码而不是 LLM 来控制编排逻辑——怎么遍历、什么时候并发、目标传递,这些都写在 JS 代码里而不是交给模型决定。下面从它的调用链路开始拆解。
一次 Workflow 的完整调用链路
从用户输入到最终回复,一次 Workflow 经历五个阶段:触发 → 脚本生成/加载 → JS 编排执行 → 子代理请求 → 结果回灌主会话。
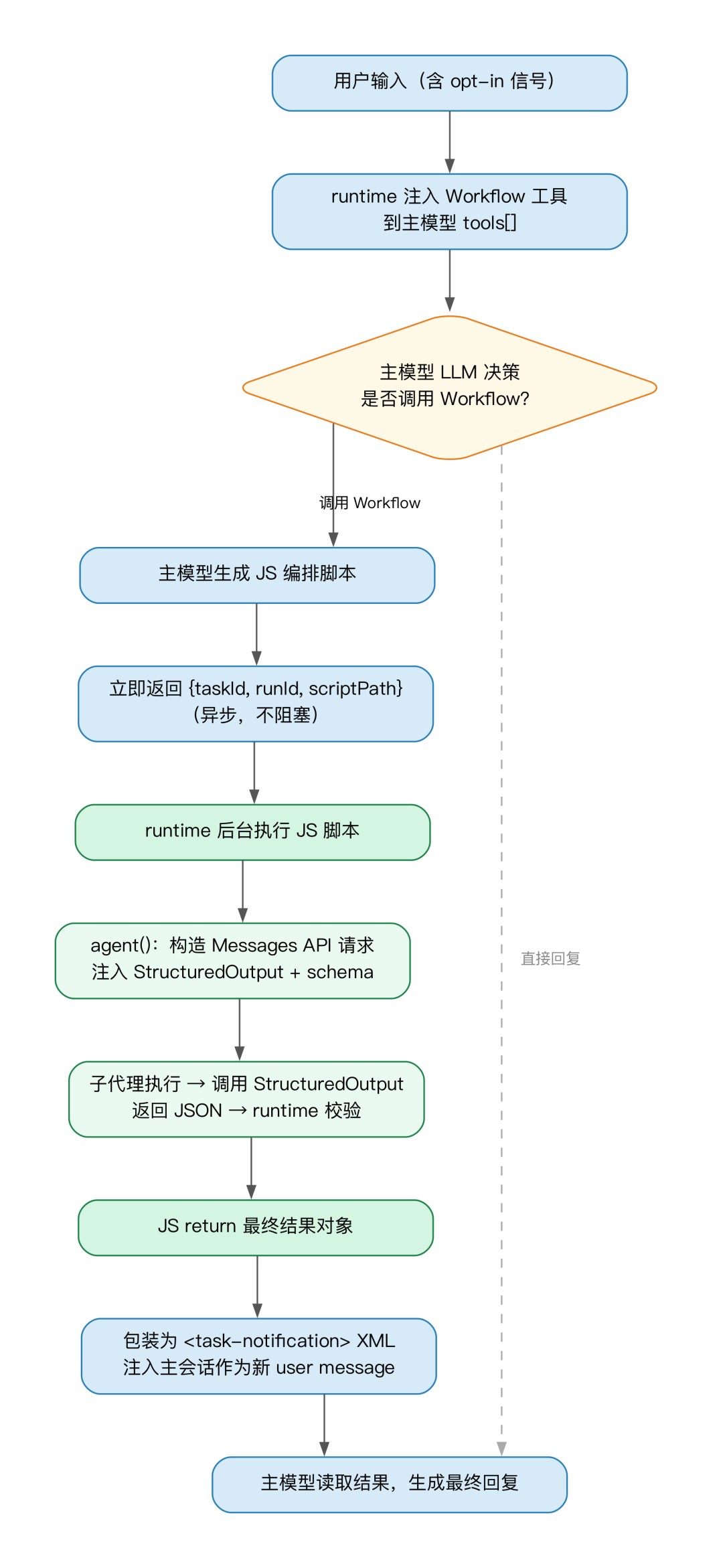
触发机制
Workflow 默认不会自动触发。Claude Code 启动时会把 Workflow 工具加入主模型的可用工具列表,但光有工具还不够——用户必须先明确表示"我要用 Workflow",主模型才会考虑调用它。即使任务明显适合并行,没有这个信号,主模型也不会自主启动。
触发方式很直接:消息里带 workflow 或 ultracode 关键词,或者直接说"用多个 agent 并行处理"这类表述,Claude Code 就会激活这个能力。之后由主模型自己判断:这个任务值不值得启动 Workflow?还是普通单 agent 就够了。
如果开启 ultracode 模式(一个全局配置项,让 Claude Code 对所有实质性任务默认使用 Workflow),就不需要每次都显式说明。
JS 编排脚本
主模型决定使用 Workflow 后,它不会直接启动子代理,而是先写出一段 JavaScript 编排脚本——定义哪些任务并行、哪些串行、每个子代理做什么、返回什么格式。如果用户之前保存过 workflow,也可以直接指定复用,不必重新生成。
以下是抓包得到脚本的简化版——研究者用「桌游设计锦标赛」作为测试任务验证 Workflow 机制:5 个设计方向并行发明概念,每个概念由 3 个评委打分,最后综合出冠军设计稿,完整运行产生了 21 个子代理、耗时 257 秒。
// meta 描述 workflow 的名称和阶段,必须是固定值,不能有运行时计算
export const meta = {
name: 'boardgame-tournament',
description: '桌游设计锦标赛:并行发明概念 → 评委团打分 → 综合出冠军设计稿',
phases: [
{ title: 'Invent', detail: '5 个设计方向并行发明概念' },
{ title: 'Judge', detail: '每个概念由 3 个评委独立打分' },
{ title: 'Synthesize', detail: '综合冠军概念,产出完整设计稿' },
],
}
export default async function workflow() {
// pipeline:某个概念一生成,立刻进入评审,不等其他概念
const results = await pipeline(
LENSES,
(lens) => agent(`发明一个围绕「${lens.desc}」的桌游概念`, {
label: `invent:${lens.key}`, phase: 'Invent', schema: CONCEPT_SCHEMA
}),
(concept, lens) => parallel(
JUDGES.map((j) => () => agent(`从「${j.desc}」角度给这个概念打分`, {
label: `judge:${lens.key}:${j.key}`, phase: 'Judge', schema: JUDGE_SCHEMA
}))
)
)
// 串行综合:等所有评分完成后,综合冠军概念
const winner = results.sort((a, b) => b.avg - a.avg)[0]
const finalDesign = await agent(`把冠军概念打磨成完整设计稿`, {
label: 'synthesize', phase: 'Synthesize', schema: SYNTH_SCHEMA
})
return { winner: winner.concept.name, finalDesign }
}要启动一个子任务,调用 agent(prompt, opts),它会启动一个独立的子代理并等待结果返回。上面的桌游例子里,发明和评审两个阶段用的是 pipeline:5 个设计方向 (LENSES) 依次经过发明→评审两个阶段,lens[0] 的发明 agent 跑完,它的概念立刻交给 3 个评委开始打分,不需要等其他 4 个方向也发明完。而评审阶段内部用的是 parallel:同一个概念的 3 个评委并发跑,等 3 个都打完分才计算平均分继续下一步。两者的选择原则很简单:下一步的输入依赖所有任务的输出 (比如要算平均分),用 parallel;下一步只依赖当前 item 自己的输出,用 pipeline。
以上是脚本的整体结构和核心控制流。下面是写脚本时需要知道的配置和约束:
agent() 的第二个参数 opts 还有几个影响执行行为的配置:上面抓包里的 model: claude-opus-4-8 就是 opts.model 在起作用——发明阶段用 Opus 做创意、评审阶段可以换 Sonnet 省钱。opts.label (如 invent:spatial) 是 Resume 恢复的关键——第八章会讲到,缓存命中靠的就是 label 匹配,label 错了等于缓存全失效。opts.isolation: 'worktree' 解决并发写文件的问题:5 个 agent 同时改代码,不加隔离会互相覆盖,worktree 让每个 agent 在独立的 git 分支里工作,跑完再 merge。
再看桌游脚本里的数据流向:invent agent 返回一个 JSON 概念对象 ({ name, coreMechanic, ... }),JS runtime 拿到后直接把它塞进 judge agent 的 prompt 里。两个 agent 之间没有任何会话历史共享——judge 不知道 invent 存在过,它只看到一段文本和一个 JSON。invent 跑完就销毁了,不占资源、不留状态。这就是 Workflow 的通信模型:所有子代理间的数据传递靠 JS 变量完成,不靠 agent 之间直接对话。
想在运行时看到进度,可以用 phase() 标记当前所处的阶段,用 log() 输出实时日志。两者都只影响 UI 显示,不影响执行结果。
如果任务规模大、需要控制成本,budget 提供当前 token 预算信息,超出后 agent() 直接报错停止;args 接收调用时从外部传入的参数,让脚本可以被参数化复用。遇到更复杂的场景,workflow() 允许在当前脚本里嵌套调用另一个 workflow,但只允许一层嵌套。脚本运行环境的其他限制:Node.js API 和网络请求不可用,所有外部调用必须经过 agent() 走子代理;并发上限是 min(16, cpu cores - 2),单次 Workflow 最多启动 1000 个 agent。
脚本写好后不必每次重新生成。Claude Code 提供了保存功能,可以把脚本存到 ~/.claude/workflows/ 目录,之后通过名称直接调用。如果要在团队内分发,把 JS 文件放进 Skill 目录并在 SKILL.md 里引用即可。结构固定、反复执行的任务 (如代码安全审计、大范围迁移、Inbox 分类处理) 最适合固化成命名 workflow。
编排 Pattern
第四章的桌游例子用了 pipeline + parallel 的组合。实际上 agent() + JS 控制流可以组合出多种编排模式,每种适合不同类型的任务:
Classify-and-act(分类后路由)
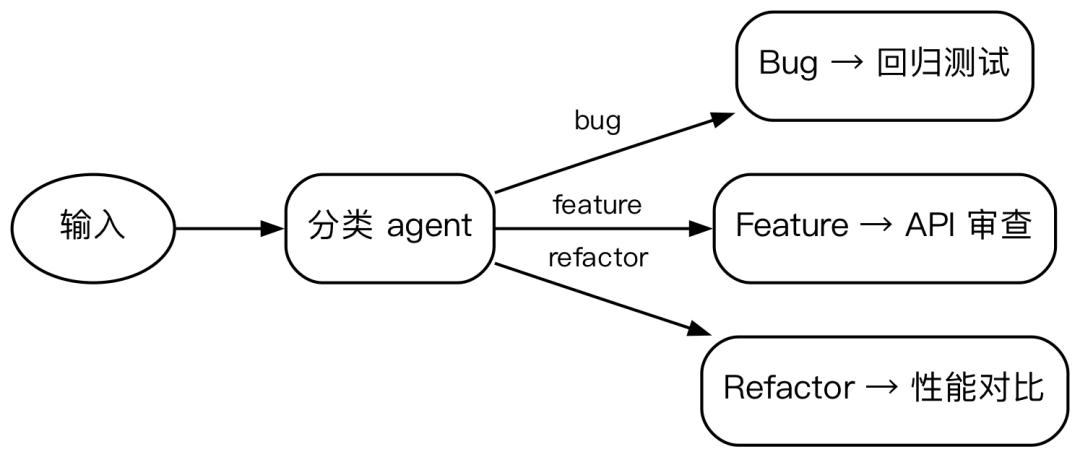
// 先分类,再路由到专门 agent
const { type } = await agent("对输入分类", { schema: { type: "string" } });
const result = type === "A" ? await agent("处理A类", opts) : await agent("处理B类", opts);适合不同类型的输入需要走完全不同的处理流程的场景。比如一个 PR review 系统:先判断这个 PR 是 bug 修复、新功能还是重构,然后走不同的 agent——bug 走回归测试检查,功能走 API 设计审查,重构走性能对比。分类本身也是一个 agent,但它只做判断不做执行。
Fan-out-and-synthesize(并行做 + 合并)
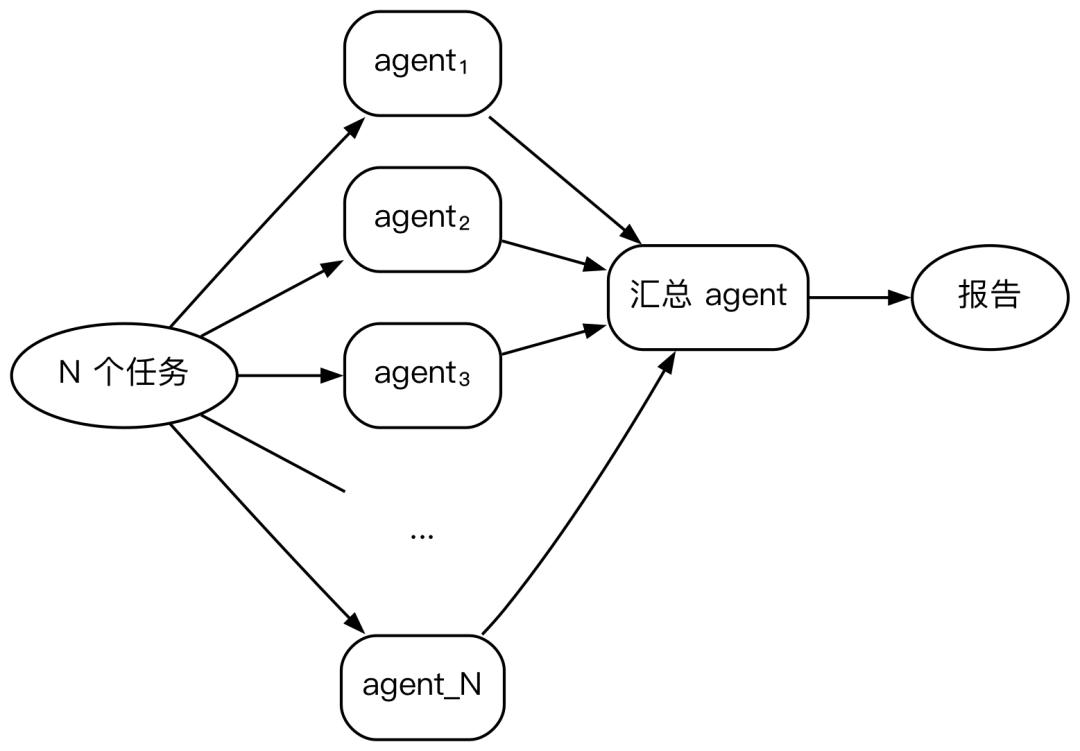
// 并行处理,一个 agent 汇总
const results = await parallel(items.map(i => agent(`处理 ${i}`, { schema })));
const summary = await agent(`综合:${JSON.stringify(results)}`, { schema: summarySchema });最常用的 pattern。适合"同一类任务并行做 N 个,然后汇总"的场景:比如并行审查 20 个文件的安全漏洞,然后一个 agent 汇总成一份报告;或者并行调研 10 个竞品,然后综合为对比分析。极端案例:一个技术博客 (ProductCompass) 用这个 pattern 并行让 113 个 agent 各自分析一个产品功能点,然后汇总成一篇完整的产品分析报告,耗时 12.5 分钟,消耗 1.95M tokens。
Adversarial verification(生成 + 独立反驳)
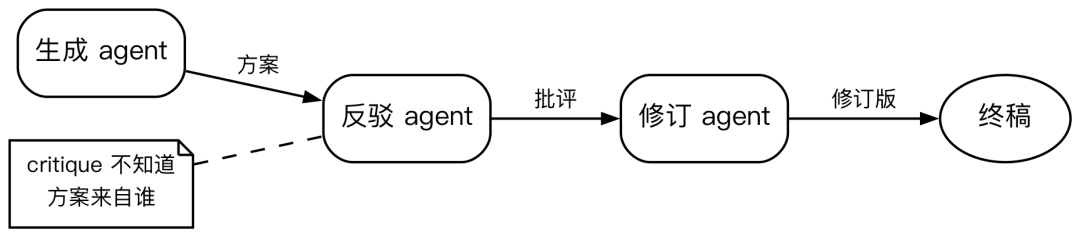
// judge agent 只拿到输出,不知道生成者是谁
const result = await agent("生成方案", { schema: solutionSchema });
const critique = await agent(`挑出以下方案的问题:${JSON.stringify(result)}`, { schema: critiqueSchema });
const final = await agent(`根据批评修订:${JSON.stringify({ result, critique })}`, { schema });解决一个常见问题:让同一个 LLM 生成方案再自己评价,它总会给自己高分。拆成三个独立 agent 后,critique agent 只看到一段方案文本,不知道是谁写的,没有"自己"的概念,所以不存在偏袒。适合需要质量保证的场景:代码审查、方案设计、合同起草——生成一版,独立挑毛病,再根据批评修订。
Generate-and-filter(大量生成 + 筛选)
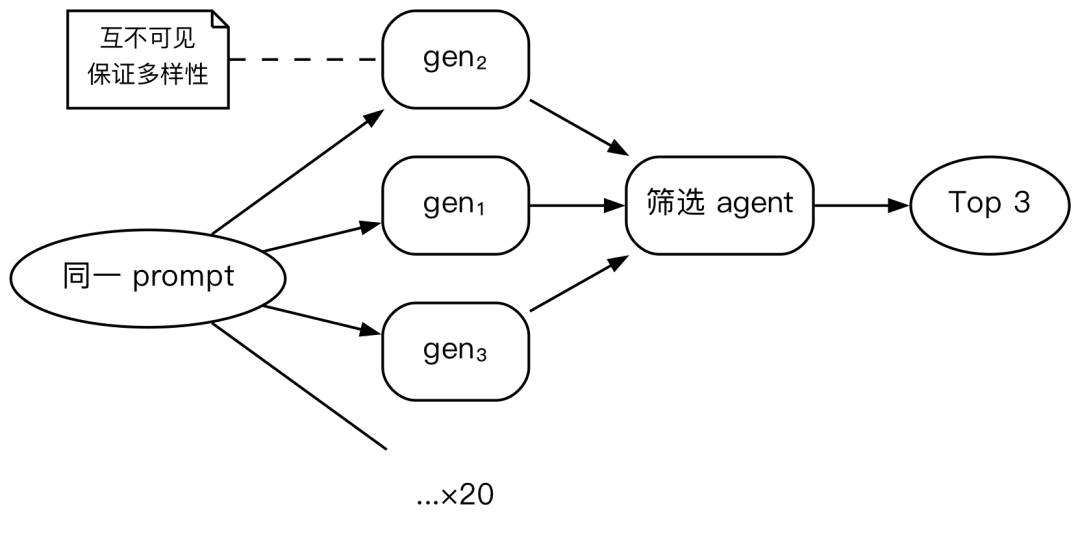
const candidates = await parallel(Array(20).fill(0).map(() => agent("生成候选", { schema })));
const filtered = await agent(`从以下候选中选出最好的3个:${JSON.stringify(candidates)}`, { schema });适合"先广撒网,再精选"的场景:让 20 个 agent 各自独立写一版实现方案,然后一个筛选 agent 综合评估选出最佳 3 个。由于生成阶段完全并行且互不可见,多样性有保证——不会出现 20 个 agent 越写越像的问题。
Tournament(N 方案 + 淘汰赛)
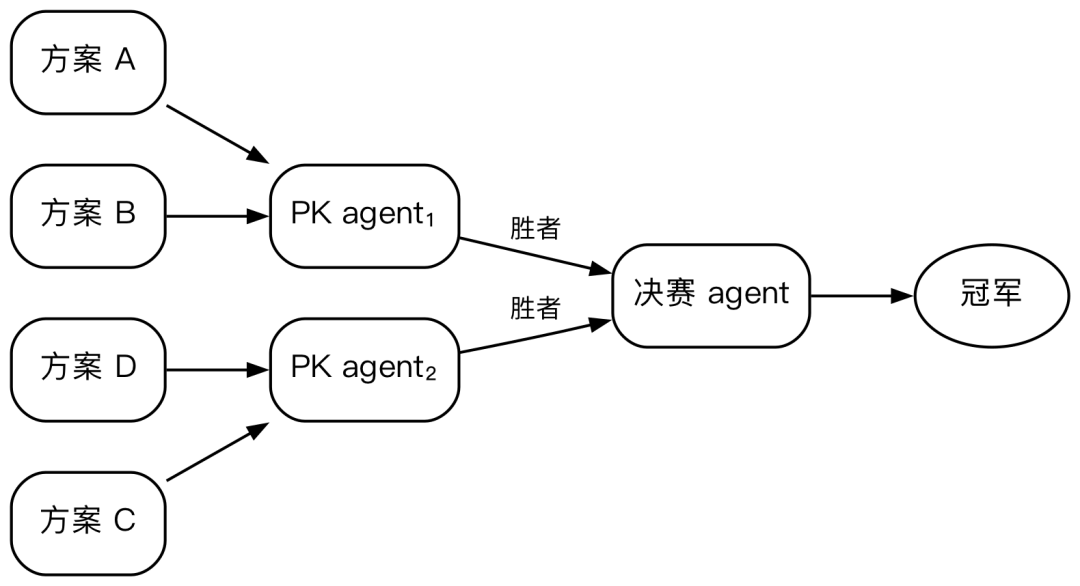
let solutions = await parallel(specs.map(s => agent(`实现方案:${s}`, { schema })));
while (solutions.length > 1) {
solutions = await parallel(
chunk(solutions, 2).map(([a, b]) => agent(`比较并选出更好的:${JSON.stringify([a, b])}`, { schema }))
);
}Adversarial verification 的进阶版。区别在于:Adversarial 只有一轮反驳,Tournament 是多轮淘汰——每轮由独立 agent 两两对比,败者淘汰,直到剩最后一个。适合有多个候选方案且需要严格筛选的场景,比如多个架构方案比选、多种算法实现的性能对比。上面桌游示例用的就是这个 Pattern,实测 21 agents,232900 tokens,257 秒。
Loop-until-done(循环至停止条件)

let state = initialState;
while (!state.done) {
state = await agent(`继续执行,当前状态:${JSON.stringify(state)}`, {
schema: { done: "boolean", result: "string" }
});
}停止条件的判断权从 LLM 的"感觉"移到了代码的显式逻辑。虽然 done 的值仍由 agent 返回,但配合 schema 约束和 state 审计 (每轮的 JSON 都可追溯),比纯对话模式下 LLM 自由宣布"完成"可控得多。如果需要更严格的保证,可以在 JS 里加 minIterations 或用独立 judge agent 来决定是否真的做完了。
agent() 底层:子代理怎么被调用
第四节看到的是脚本层的 agent() 调用——现在往下一层,看 Claude Code 是怎么把这个调用变成一次真实的子代理请求的。每个 agent() 会向 Anthropic Messages API 发起一次独立的请求,以 Async 方式执行 (发出后不阻塞当前脚本,子代理完成后 resolve 为返回值)。
以下是 Reqable 抓包中 invent 阶段请求的简化结构:
POST /v1/messages?beta=true
model: claude-opus-4-8 // opts.model 可覆盖
system: [
{ "text": "x-anthropic-billing-header: ..." },
{ "text": "You are Claude Code, Anthropic's official CLI for Claude." },
{ "text": "You are a subagent spawned by a workflow orchestration script...
CRITICAL: You MUST call the StructuredOutput tool exactly once..." }
]
messages: [{
"role": "user",
"content": [
{ "text": "..." },
{ "text": "请发明一个原创桌游概念,核心围绕「空间拼块铺设与领地建设玩法」..." }
]
}]
tools: [
{ "name": "Bash", ... },
{ "name": "Read", ... },
...其他 Claude Code 工具...
{
"name": "StructuredOutput",
"input_schema": { // 来自 agent(prompt, { schema: CONCEPT_SCHEMA })
"type": "object",
"properties": {
"name": { "type": "string" },
"coreMechanic": { "type": "string" },
...
}
}
}
]注意 tools[] 里的 StructuredOutput——这是 Claude Code 强制注入的。子代理的 system prompt 里有明确指令:任务完成后必须调用这个工具返回 JSON,不允许用文本回复代替。这样 runtime 拿到的是结构化数据,不是自然语言,不需要再解析。schema 由 agent(prompt, { schema }) 传入,定义了返回值的结构,同时也是 JS 里接收到的对象类型。没有传 schema 时,返回裸字符串。
结果回灌
请求发出去了,子代理跑完后,结果通过以下路径回到主会话:
JS return value → JSON.stringify → 包装成 XML → 作为新的 user message 追加到主会话。主模型收到这条消息后,读取 result 里的 JSON,结合原始任务生成最终回复。usage 字段给出整次 Workflow 的消耗统计:子代理数量、token 用量、耗时。
Resume 恢复机制
前两节讲的是一次正常执行的完整路径。但 Workflow 可能跑很久 (桌游示例 257 秒,ProductCompass 12.5 分钟),期间网络断开、进程崩溃都有可能。这时需要一套中断恢复机制——不用从头跑,只重跑失败的部分。
Workflow 调用后立即返回一个 runId,恢复时靠它定位上次执行的进度:
// 首次调用
const { runId, scriptPath } = await callTool("Workflow", { script: myScript });
// 中途失败,Resume
await callTool("Workflow", {
scriptPath: scriptPath,
resumeFromRunId: runId
});但 Resume 不是简单地从头再跑一遍。假设一个 Workflow 按顺序调了 10 个 agent,跑到第 8 个时网断了。恢复时,runtime 从头开始逐个检查:当前要调的 agent 和上次调的是不是"同一个调用" (同样的 prompt、同样的参数)?如果是,直接用上次的返回值,跳过。继续比下一个,直到发现不一致的位置,从那里开始真正执行:

- 前 7 个全部命中 → Resume 从第 8 个继续,省掉 7 次 API 调用
- 脚本没改、args 没变 → 100% cache hit,整个 Workflow 瞬间返回
为什么这套机制要求禁止 Math.random() 和 Date.now()?假设脚本里写了:
const seed = Math.random(); // 第一次跑:0.7234
await agent(`用种子 ${seed} 生成方案`);第一次跑,prompt 是"用种子 0.7234 生成方案"。Resume 时再跑,Math.random() 产生了 0.1568,prompt 变成"用种子 0.1568 生成方案"。runtime 一比——prompt 不一样,不是同一个调用,前缀在第一个就断了,所有缓存全部失效,从头重跑。
这就是为什么 Math.random() 和 Date.now() 被禁止的根本原因:保证同一个脚本 + 同一个输入,每次产生的 agent 调用序列完全相同,前缀匹配才能生效。
与 Coordinator 的关系
Claude Code 的子智能体有六种执行模式,其中 Coordinator 模式也是一种编排机制——由一个"协调者" agent 来决定启动哪些子代理、什么顺序、怎么汇总。那它和 Dynamic Workflow 是什么关系?
两者的核心区别:Coordinator 是 LLM 驱动的动态编排,Workflow 是代码驱动的确定性编排。Coordinator 由一个 LLM 在运行时决定"接下来调谁",这意味着编排逻辑本身也消耗 token、也可能出错;Workflow 把编排逻辑写在 JS 代码里,路由、并发、汇总都是确定性的,不消耗 token。
两者共用相同的底层基础设施——子代理都走 Messages API 异步模式,StructuredOutput 注入机制相同——只是上层编排的决策者不同:一个是 LLM,一个是代码。
Coordinator 由服务端 feature flag COORDINATOR_MODE 控制。在 2026.3.31 泄漏的源码里,Coordinator 代码结构完整,是当时唯一的编排机制。实测发现,无论是 Workflow 发布前的 v2.1.138 还是发布后的 v2.1.158,设置 CLAUDE_CODE_COORDINATOR_MODE=1 均无法触发 Coordinator。
可能的解释:Coordinator 始终由服务端 flag 控制、未对普通用户开放;也可能在 Dynamic Workflow 发布后已被替代。从结果看,当前用户能触及的编排能力就是 Dynamic Workflow。
参考资料
- Claude Code 泄漏源码 (2026.3.31)
- Dynamic Workflow 官方发布 (2026.5.28, Claude Code v2.1.158):https://docs.anthropic.com/en/docs/claude-code/workflows
- 实测抓包数据:https://github.com/TokenRollAI/claude-code-workflow-research/tree/main
- ProductCompass: Claude Dynamic Workflows for PMs:https://www.productcompass.pm/p/claude-dynamic-workflows-for-pms