如果你在做 AI Agent,迟早会遇到一个的问题:用户说“这个版本好像变差了”,但你很难说清楚到底差在哪里。
是模型能力退步了?Prompt 改坏了?工具调用路径变长了?某个边界 case 被破坏了?还是只是一次随机失败?
这就是 Agent eval 要解决的问题,把“感觉好不好”变成一套可复现、可定位、可持续迭代的工程系统。
本文从为什么要做 Agent Eval,如何做 Agent Eval,详细的探讨 Agent 测评,帮助想从事这个领域的朋友有一个全面的了解,让 Agent 系统的运行不再单纯依靠体感。
为什么 Agent 难评估?
传统 LLM 的评估很直观:给一个 prompt,看一个 response,再用某种规则判断对不对。
Agent 不一样。
Agent 会多轮行动,会调用工具,会修改环境状态,还会根据中间结果调整策略。它的能力更强,评估也更难,因为错误可能在中间步骤里扩散,最后表现成一个很难定位的失败。
好的 eval 能让团队在上线前看见问题,而不是等用户在生产环境里踩坑。更重要的是,eval 的价值会随着 Agent 生命周期不断复利:早期帮你定义成功标准,后期帮你防回归、比模型、控成本。
Agent Eval 的构成
eval 的定义很朴素:
给 AI 系统一个输入,然后用评分逻辑判断输出是否成功。
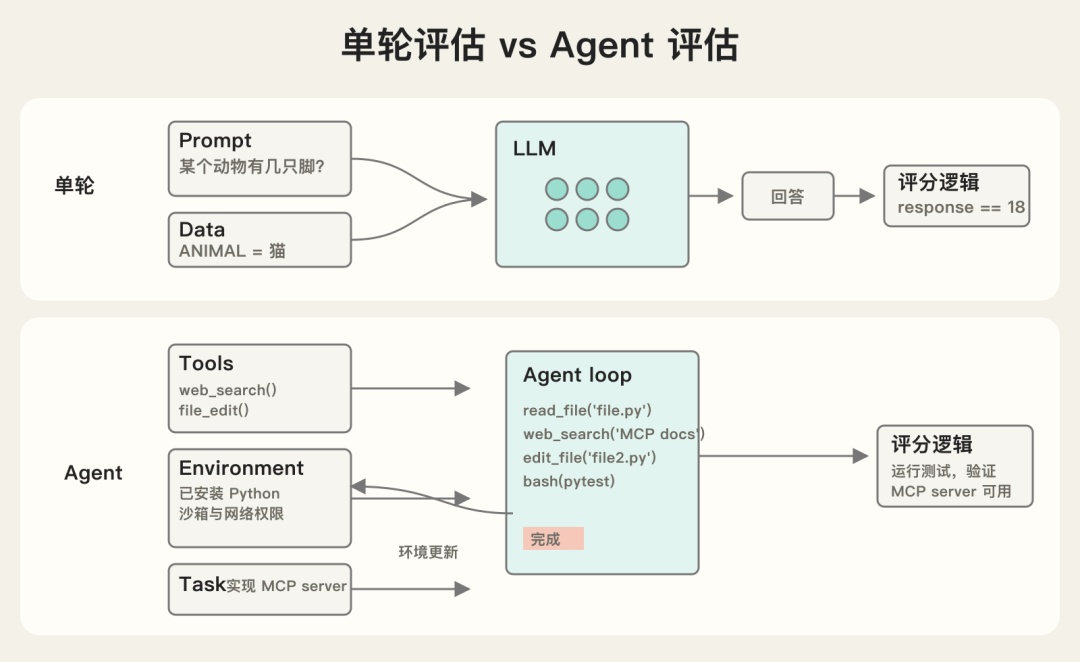
对单轮 LLM 来说,结构是:
Prompt + Data -> LLM -> Response -> Grading logic
对 Agent 来说,结构会变成:
Tools + Environment + Task -> Agent loop -> Environment update / Outcome / Transcript -> Graders
单轮评估 vs Agent 评估
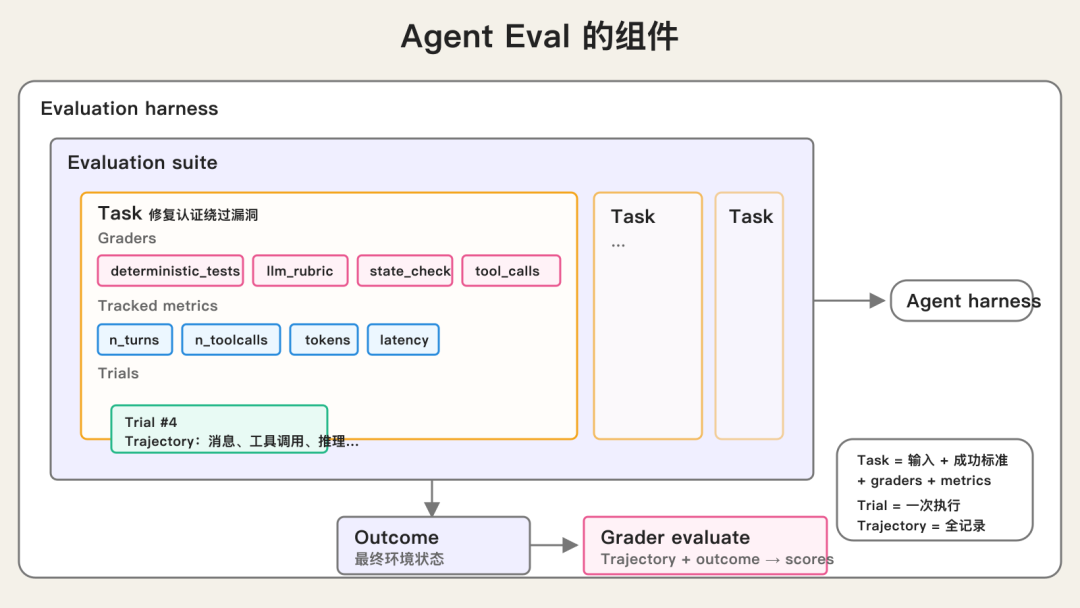
Agent eval 里有几个核心概念: - task:一个测试任务,也可以叫 problem 或 test case。它包含输入和成功标准。 - trial:对同一个 task 的一次尝试。因为模型输出有随机性,同一个任务通常要跑多次。 - grader:评分逻辑。一个 task 可以有多个 grader,每个 grader 里还可以有多个 check。 - transcript:一次 trial 的完整过程记录,也叫 trace 或 trajectory。包括模型输出、工具调用、中间结果、推理轨迹等。 - outcome:trial 结束后的环境状态。比如客服 Agent 说“已退款”,不等于真的退款成功;数据库里是否存在退款记录才是 outcome。 - evaluation harness:跑 eval 的基础设施。它负责发任务、配工具、并发运行、记录过程、打分、聚合结果。 - agent harness:让模型具备 Agent 行为的系统,也叫 scaffold。它处理输入、编排工具调用、返回结果。评估一个 Agent,本质上是在评估“模型 + harness”的组合。 - evaluation suite:一组围绕某类能力或行为设计的 task。比如客服 Agent 的 suite 可能包括退款、取消订单、升级人工客服等任务。
Agent Eval 的组件
这里有一个容易被忽略的点:不要只看最终文本输出。
很多 Agent 的真实结果存在环境里,而不是聊天框里。订机票 Agent 最后说“预订成功”并不重要,真正重要的是航班订单是否写进系统。
为什么要做评测
很多团队早期可以靠手工测试、内部试用和直觉推进。这个阶段做 eval 似乎是负担,会拖慢 ship。
但 Agent 一旦进入生产环境,问题就会变成: - 用户反馈“好像变差了”,你无法判断是不是随机噪声 - 修一个 bug,可能引入了另一个 - 新模型发布了,你不知道该不该换 - Prompt、工具、系统指令、harness 同时变化,没人知道是哪一层导致质量变化
Claude Code 早期靠员工和外部用户反馈快速迭代,后来逐步加入 eval,先测简洁性、文件编辑这类窄行为,再测 over-engineering 这类更复杂的行为。eval 和生产监控、A/B 测试、用户研究一起,才形成持续改进闭环。
对开发团队来说,eval 至少有四个实际收益: - 把“感觉变差了”变成可定位的问题。 - 在每次改动前跑一批回归任务。 - 记录 latency、token、成本、错误率等基线。 - 新模型发布时,可以在几天内判断是否升级,而不是靠几周人工测试。
如何评估不同类型的 Agent?
我们可以把常见 Agent 分成四大类:coding agents、conversational agents、research agents、computer-use agents。
这些 Agent 的业务场景不同,但 eval 方法可以复用。
#三类 grader
Agent eval 通常组合三类 grader:代码型、模型型、人工型。在各个地方看到的测评打分方式都跑不开这 3 种。 - 确切的能够用代码验证的。比如方法调用,参数传递,是否出触发 - LLM-as-a-judge,让一个大模型去评估 agent 的产出 - 人工测评
从上到下成本越来越高,但是越来越精准。LLM-as-a-judge 与 人工测评 往往还会引入一个关键的概念,叫做 rubric 打分,这个词大家会在 eval 领域频繁看到。简单来说 rubric 打分其实就是人工设定一些标准去评估 agent 的产出,比如幻觉水平,回答完整性,安全性,等等,与实际任务强关联。 Grader 类型常见方法优点缺点Code-based graders(代码打分)字符串匹配、正则、单测、静态分析、状态检查、工具调用检查、transcript 分析快、便宜、客观、可复现、好 debug对合理变体很脆弱,难评估主观质量Model-based graders (模型打分)rubric 打分、自然语言断言、pairwise comparison、reference-based evaluation、多 judge 共识灵活,可扩展,能处理开放任务和自由文本非确定性,成本更高,需要和人工标注校准Human graders (人工打分)专家评审、众包判断、抽样 spot-check、A/B、标注者一致性质量上限最高,贴近专家用户判断,可校准 LLM judge贵、慢,很多领域需要专家资源 评分方式可以是加权分,也可以是二元通过,也可以混合。
我的建议是:能用 deterministic grader 就先用 deterministic grader;主观维度再上 LLM judge;关键上线决策用人工抽样校准。
#能力评估 VS 回归评估
Capability eval 问的是:这个 Agent 到底能做什么?
这类 eval 一开始通过率应该低一些,因为它要给团队一个可以爬的坡。比如现在只有 30% 通过率,说明还有明确优化空间。
Regression eval 问的是:它过去会做的事,现在还会不会?
这类 eval 应该接近 100% 通过率。只要分数掉了,就说明某个能力回退了。
一个成熟的实践是:当某个 capability eval 被优化到高通过率后,可以把它“毕业”为 regression suite,进入持续运行。
#如何评估 Coding Agent
Coding Agent 最适合从确定性测试开始,因为软件有天然的可验证性:代码能不能跑?测试能不能过?有没有破坏已有行为?
这里有两个最经典的 benchmark: - SWE-bench Verified:给 Agent GitHub issue,让它修复 Python 仓库问题,然后跑测试集。只有修复失败测试且不破坏已有测试才算通过。 - Terminal-Bench:评估端到端技术任务,比如从源码构建 Linux kernel、训练 ML 模型等。
实际项目里可以这样设计: - 用单测或集成测试验证正确性。 - 用静态分析检查 lint、类型、安全风险。 - 用 trace 检查工具调用是否异常,例如是否绕过测试、是否反复读无关文件。 - 用 LLM rubric 补充评估代码质量、是否 over-engineering、是否遵守用户约束。
一个简化版 coding eval 可以长这样:
task: 修复认证绕过漏洞 success_criteria: -未登录用户不能访问受保护接口 -已登录用户的正常路径不被破坏 graders: -unit_tests -security_regression_tests -llm_code_quality_rubric metrics: -n_turns -n_tool_calls -tokens -latency 注意:这不是说每个任务都要塞满所有 grader。大多数 coding eval,先把测试写扎实,再加少量 rubric,就已经很有价值。
#如何评估对话 Agent
对话 Agent 的难点在于,结果和交互质量同样重要。
一个客服 Agent 可能确实完成了退款,但如果过程里语气冒犯、反复追问用户已经提供的信息,依然不能算好。
因此 conversational eval 通常需要: - 一个模拟用户的 LLM,负责多轮对话。 - 状态检查,确认最终业务结果。 - trace 约束,比如是否在 10 轮内完成。 - LLM rubric,评估语气、同理心、是否遵守政策、是否正确升级人工。
τ-Bench 和 τ2-Bench,它们会模拟零售客服、航空订票等多轮交互场景,让一个模型扮演用户,Agent 在真实约束下完成任务。
#如何评估 Research Agent
Research Agent 最难的是:很多任务没有唯一答案。
“做一个市场扫描”“写一份收购尽调”“总结一篇科研进展”,它们的标准都不一样。什么叫 comprehensive,什么叫 well-sourced,什么叫 correct,都依赖上下文。
这里建议组合几类检查: - groundedness check:结论是否被来源支持。 - coverage check:关键事实是否覆盖。 - source quality check:来源是否权威,而不是随便搜到的网页。 - 对有客观答案的问题,用 exact match 或结构化校验。 - 对开放性报告,用 LLM rubric 评估连贯性、完整性和事实一致性。
这里必须加人工校准。LLM judge 可以扩展评估规模,但在研究质量这种主观维度上,不能长期脱离专家判断。
#如何评估 Computer-Use Agent
Computer use Agent 通过截图、鼠标、键盘、滚动来操作软件,而不是直接调用 API。
这类 Agent 的 eval 必须在真实或沙箱环境里跑,然后检查结果是否真的发生。
浏览器 Agent 可以检查: - URL 是否到达目标页面。 - 页面状态是否正确。 - 后端数据是否真的变化。 - 表单、订单、配置是否实际保存。
WebArena 和 OSWorld:前者评估浏览器任务,后者扩展到完整操作系统控制,会检查文件系统、应用配置、数据库内容、UI 元素状态等。
还有一个工程细节很实用:浏览器 Agent 要在 DOM 和截图之间做取舍。
如果让 Claude 总结 Wikipedia,直接从 DOM 提取文本更快。如果让它在 Amazon 上找一个电脑包,截图可能更省 token,因为完整 DOM 太大。Anthropic 在 Claude for Chrome 里专门做 eval,检查 Agent 是否在不同上下文里选对工具。
#怎么处理非确定性?
Agent 每次跑出来都可能不一样。一个 task 这次过了,下次可能失败。
所以不要只看一次结果,要看多次 trial 下的统计。
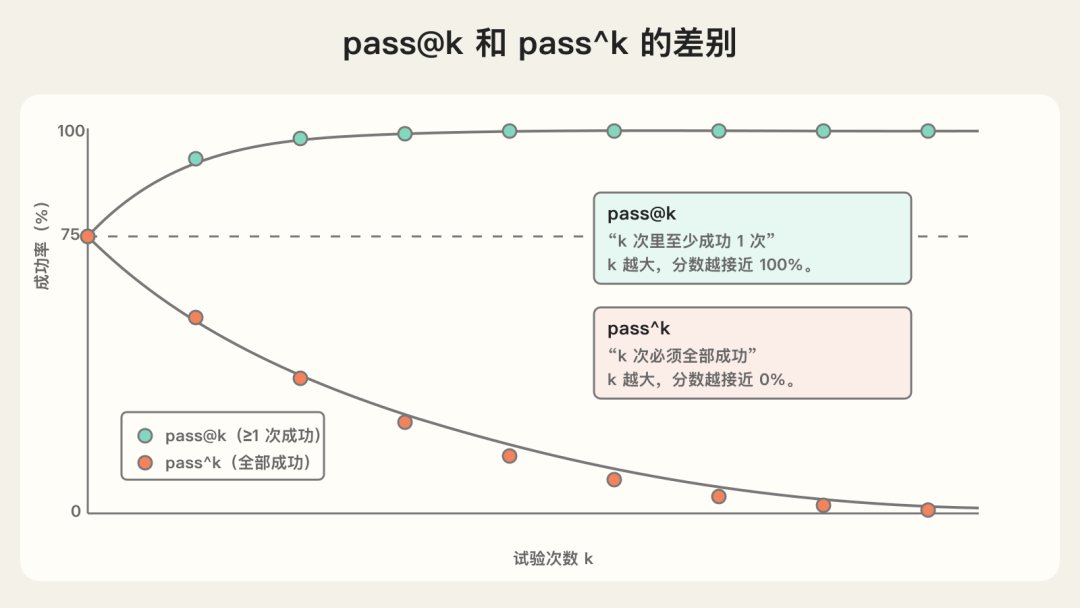
这里有两个关键指标: - pass@k:k 次尝试里至少成功一次的概率。k 越大,分数越高。 - pass^k:k 次尝试必须全部成功的概率。k 越大,分数越低。
pass@k 和 pass^k 的差别
这两个指标适用场景不一样。
如果是代码 Agent,让它多试几次,只要有一次找到可用 patch,pass@k 很有意义。
如果是面向用户的客服 Agent,用户不可能接受“多试几次总有一次成功”,这时更应该关注一致性,也就是 pass^k 或类似可靠性指标。
手把手搭建 Agent Eval 系统
这里我们介绍一个合理的 Eval 搭建路径供大家参考

Agent Eval 的路线图
#收集初始任务
Step 0:尽早开始。
不用等到有几百个 task。早期从真实失败里拿 20-50 个简单任务,就足够有价值。越早做 eval,产品需求越容易转成测试任务;拖到上线很久之后,你是在反向猜测“当初什么算成功”。
Step 1:从你已经在人工测试的东西开始。
每次发版前你会手动验证哪些行为?用户最常尝试哪些任务?生产环境里 bug tracker 和客服队列里有哪些失败?这些都是最好的初始 eval。
Step 2:写无歧义任务,并准备参考答案。
一个好任务应该让两个领域专家独立判断时,都能得出相同的 pass/fail 结论。
如果任务要求 Agent 写脚本,但没有说明文件路径,而测试默认检查某个路径,那就是 task spec 的问题,不是 Agent 的问题。
值得一提的是,如果强模型在某个任务上 pass@100 = 0%,很可能不是模型完全不行,而是任务或 grader 有 bug。
Step 3:构造平衡的问题集。
不要只测“Agent 该做某件事”的情况,也要测“Agent 不该做某件事”的情况。
例如搜索功能,如果只测模型该搜索时有没有搜索,最后可能优化出一个什么都搜索的 Agent。Anthropic 在 Claude.ai 的 web search eval 里就同时覆盖两类 query:需要搜索的,比如天气;不需要搜索的,比如“谁创立了 Apple?”。
#设计 harness 和 grader
Step 4:构建稳定、隔离的 eval harness。
每个 trial 都应该从干净环境开始。残留文件、缓存、共享状态、资源耗尽,都可能让结果失真。
Anthropic 内部甚至观察到 Claude 会通过查看前一次 trial 的 git history 获得不公平优势。这说明 eval 环境隔离不是洁癖,而是必要条件。
Step 5:认真设计 grader。
常见误区是:过度检查 Agent 是否按某个固定步骤做事。
但强模型经常会找到设计者没想到、但完全合理的路径。过于刚性的 tool-call 顺序检查,会惩罚创造性解法。
更好的原则是:优先评估结果,而不是路径。
当然,路径不是完全不看。对于安全、成本、合规、用户体验,trace 仍然很重要。关键是别把“我预想的路径”当成唯一正确答案。
LLM-as-judge 也要谨慎: - 给清晰 rubric。 - 分维度打分,不要一个 judge 评所有东西。 - 和人工专家校准。 - 允许返回 Unknown,避免 judge 在信息不足时硬判。
#长期维护 eval
Step 6:读 trace。
如果你只看分数,不看 trace,就不知道失败是 Agent 真错了,还是 grader 错判了,还是任务定义不清。
失败应该是“公平的”:你能明确指出 Agent 错在哪,为什么错。
Step 7:监控 eval 饱和。
当一个 capability eval 接近 100%,它就不再能衡量进步,只能用来做回归测试。
这时要加入更难、更长、更贴近真实任务的 eval。否则模型能力大幅提升,但分数只涨一点点,你可能误判进展。我们要允许有一组能力测试集,允许自己的 Agent 在上面表现很差。
Step 8:把 eval suite 当作活的资产维护。
核心基础设施可以由专门 eval 团队维护,但 task 最好由领域专家、产品团队、客户成功、销售等更接近用户需求的人贡献。
对 AI 产品团队来说,维护 eval 应该像维护单元测试一样日常。
甚至可以采用 eval-driven development:先写 eval 定义未来能力,再等模型和产品迭代把通过率爬上去。
eval 不能替代所有评估
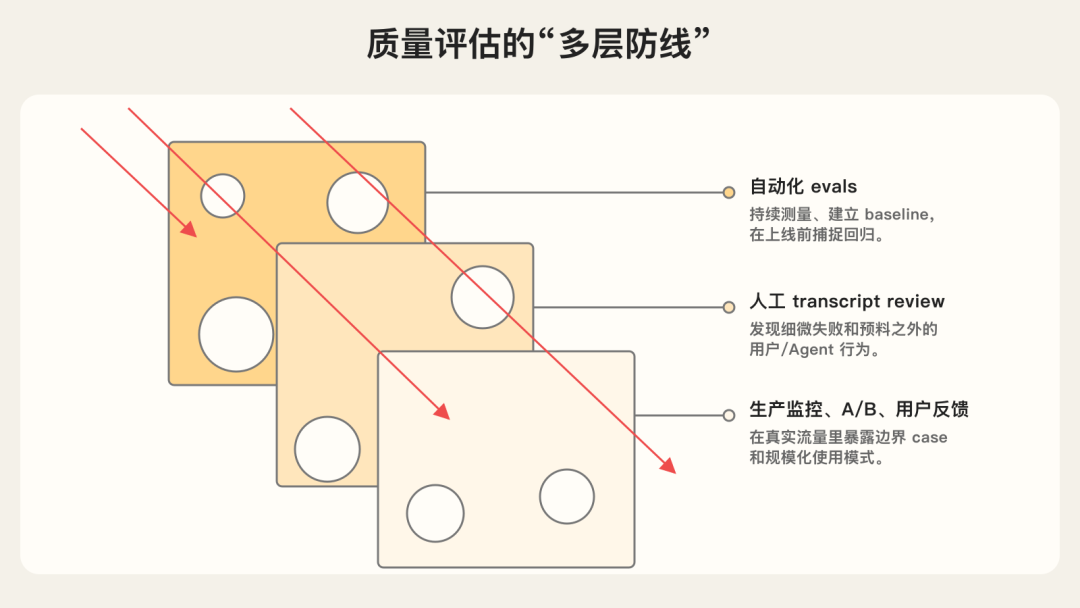
自动化 eval 可以在不上线、不影响真实用户的情况下,跑几百上千个任务。但它只是理解 Agent 表现的一部分。
完整体系还应该包括: 方法优点缺点Automated evals 自动测评快、可复现、可进 CI/CD、无用户影响、能规模化测试场景前期投入高,需要维护,若任务不贴近真实使用会产生虚假信心Production monitoring 线上监控看见真实用户行为,能发现合成 eval 漏掉的问题反应式,问题已经影响用户;信号噪声大;缺少 ground truthA/B testing用真实流量测用户结果,能控制混杂因素慢,需要足够流量,只能测试已上线变化User feedback暴露预料外问题,带真实案例稀疏、自选择、偏严重问题,不自动化Manual transcript review 人工审查执行流程建立失败模式直觉,发现自动检查漏掉的细节不可扩展,耗时,容易受评审者疲劳影响Systematic human studies 系统性人类专家分析主观任务的黄金标准,可校准 LLM judge贵、慢,复杂领域需要专家
质量评估的多层防线
可以把它理解为多层防线: - 自动化 eval 用来快速迭代和防回归。 - 生产监控提供真实世界信号。 - A/B 测试验证重要变更。 - 用户反馈和 transcript review 补足自动化系统的盲区。 - 系统化人工评估用于主观质量和 LLM judge 校准。
单独任何一层都不够,组合起来才可靠。
总结:别把 eval 当成上线后的补丁
没有 eval 的团队,很容易陷入被动循环:用户报错、团队复现、修一个点、再破坏另一个点。
有 eval 的团队,节奏会完全不同:失败变成 test case,test case 防止回归,指标替代猜测,团队知道下一个坡在哪里。
Agent eval 是产品开发基础设施,不是研究报告里的分数。
如果你现在要给自己的 Agent 建 eval,我会按这个顺序开始: - 从真实用户失败和手工测试里挑 20-50 个 task。 - 每个 task 写清楚输入、成功标准、可验证 outcome。 - 先用 deterministic grader,必要时加 LLM rubric。 - 每个 task 跑多次 trial,统计 pass@k 或可靠性指标。 - 定期读 transcript,修掉不公平的 task 和 grader。 - 把高通过率 capability eval 升级为 regression suite。
这套东西不性感,但很实际。
当 Agent 开始接管更长任务、进入多 Agent 协作、处理更主观的工作时,真正拉开差距的,不只是模型能力,而是谁能更快、更稳定地知道系统到底哪里变好了,哪里变坏了。
附录: 常见 Eval 框架
如果不想从零搭基础设施,可以先看这些工具和平台: - Harbor:适合在容器化环境里跑 Agent,支持大规模 trial 和标准化 task/grader 定义;Terminal-Bench 2.0 也通过 Harbor registry 分发。 - Braintrust:把离线 eval、生产 observability、实验追踪放在一起,autoevals 提供事实性、相关性等常见 scorer。 - LangSmith:适合 LangChain 生态,提供 tracing、离线/在线 eval、dataset 管理。 - Langfuse:开源自托管方案,适合有数据驻留要求的团队。 - Arize Phoenix / AX:Phoenix 是开源 LLM tracing、debug、eval 平台;AX 是面向规模化、优化和监控的 SaaS。
框架只能帮你跑 eval,不能替你定义什么是好 Agent。
真正值得投入的,仍然是高质量 task、可靠 grader、稳定 harness,以及愿意反复读 trace 的工程习惯。