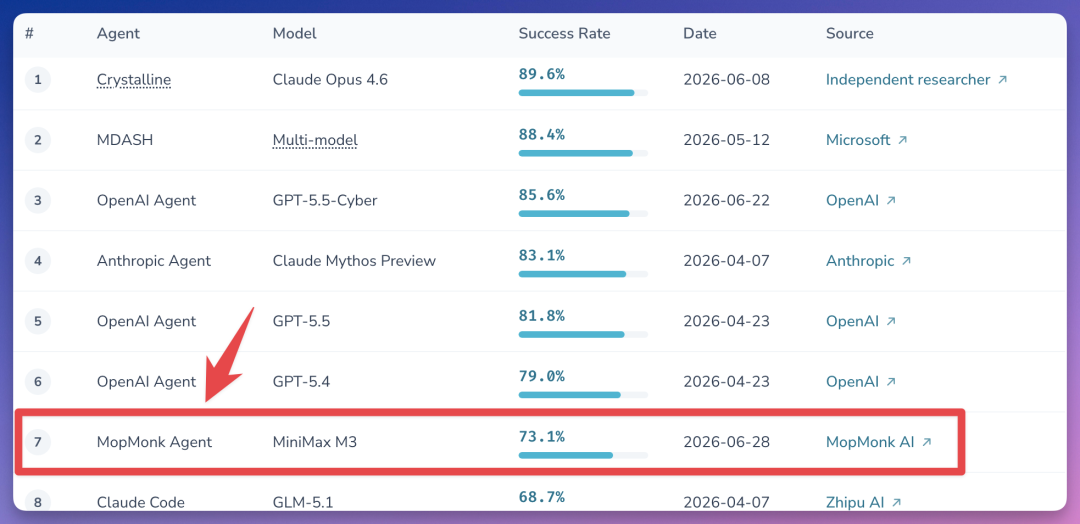
一张全球 AI 安全战力榜最近悄然刷新。来自中国团队打造的 MopMonk(扫地僧) 以 73.1% 的成功率,冲进 CyberGym TOP7,与 OpenAI、Anthropic、微软这些全球顶级 AI 玩家同台竞争。
没有官方公告,没有团队介绍,没有预热。只有一个代号和一份成绩单,却扯下了巨大的行业信息差。
CyberGym:用网络安全能力衡量 AGI 程度
如果说语言能力是 AI 的"智商测试",那网络安全能力就是 AI 的"综合格斗"。
CyberGym 由 UC Berkeley 顶尖安全研究团队打造,题库有三个硬核特点:
- 真实:1507 个真实漏洞实例,直接从 CVE 中抽样,而非实验室仿真
- 全面:横跨 188 个大型开源项目,从 Web 框架到系统内核
- 严格:只看最终结果,漏洞是否被成功触发,没有步骤分

一个 AI 能不能独立完成一项复杂、开放的真实任务,这是区分"大语言模型"和"AGI"的分水岭。网络安全恰好是数字世界最难的考题之一,要求感知、推理、规划、试错、执行全部实时在线。
目前公开成绩对比: - 微软(Microsoft):88.4% - OpenAI:85.6% - Anthropic:83.1% - MopMonk:73.1%(强势切入前十的唯一匿名玩家)
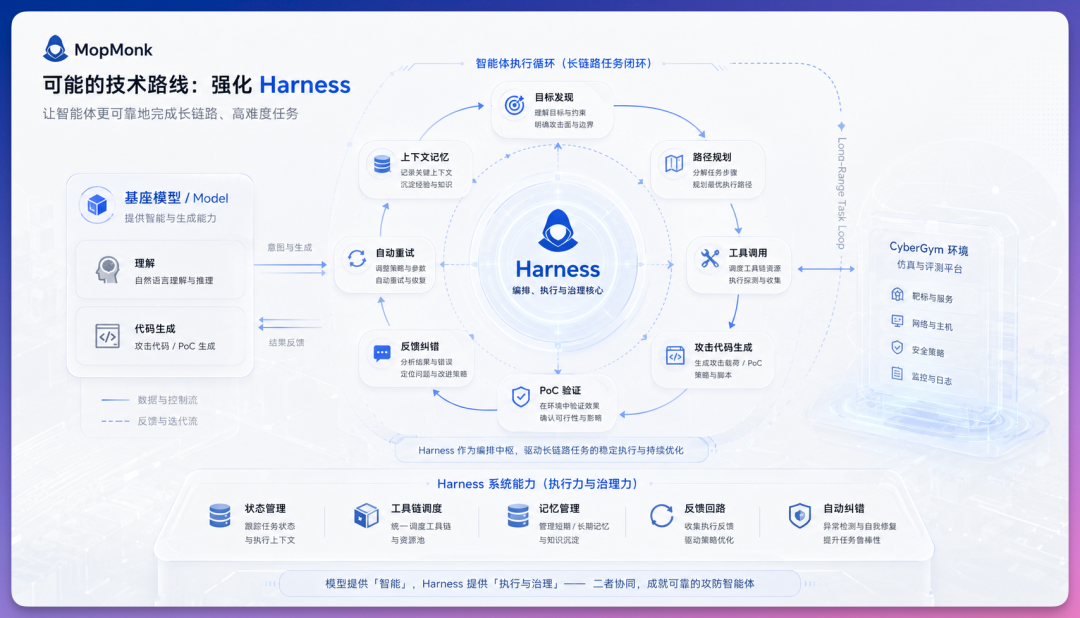
Harness 才是灵魂
CyberGym 这种严苛任务环境下,靠参数"力大砖飞"的暴力破解已经失效。再聪明的脑子,如果没有一套适配实战场景的"身体"和"神经反射弧",也会在长程反复试错中迅速崩溃。

MopMonk 能做到这一点,答案可能不在模型本身,而在 Harness(Agent 的治理与执行框架)。
CyberGym 要求 Agent 完成一条完整的长程攻击链:发现目标、规划路径、多轮试错、生成代码、自我纠错。在这个闭环中:
- 基座模型提供"智力"(代码理解与生成)
- Harness 提供"系统级执行力"(状态管理、工具调度、长文本记忆、自动化纠错与重试)
模型决定 Agent 能想到多深,Harness 决定它能咬得多死。MopMonk 在攻击链还原和漏洞 PoC 迭代验证这两个环节表现突出,这绝不是单纯靠模型基座能力就能刷出来的分数。
规则在变,垂直极致者胜
AI 竞争的底层规则正在发生质变。以前拼参数和跑分,现在拼谁能把模型、工具、策略拧成真正能打的落地执行力。
尤其在网络安全攻防这种吃深度、吃长程、吃高强对抗的场景里,未来能站稳的,大概率不是通用 Agent,而是在垂直方向上将工程化做到极致的团队。
基座是变量,Harness 才是资产。
"扫地僧"这个名字本身也传递了信号——在通往 AGI 的真实战场上,极致的垂直领域工程化能力,同样能撕开巨头的防线。
GitHub:MopMonkAI/MopMonkAgent