Google 发布了实时语音翻译模型 Gemini 3.5 Live Translate,能在 70 多种语言之间做到边听边译,同时保留说话人的语调、节奏和音高。该模型基于 Gemini 3.5 架构,兼顾了 Gemini 3.0 Pro 的专业能力和 Gemini 3.0 Flash 的速度。
已同步登陆 Gemini Live API、Google Translate App 和 Google Meet。

核心更新一览
- 支持 70 多种语言自动检测,无需手动选语言
- 边听边译,不等说完才翻,全程只比说话人慢几秒
- 翻译语音保留原始说话人的语调、节奏和音高
- 自动滤除噪音,嘈杂环境也能用
- Google Meet 语言组合从 5 种扩展到 70 多种、2000 多种组合
- Google Translate App 新增「听筒模式」(Android 独占)
- 所有生成音频带 SynthID 水印,可检测 AI 生成内容
- 开发者可通过 Gemini Live API 和 Google AI Studio 直接调用

它到底做了什么
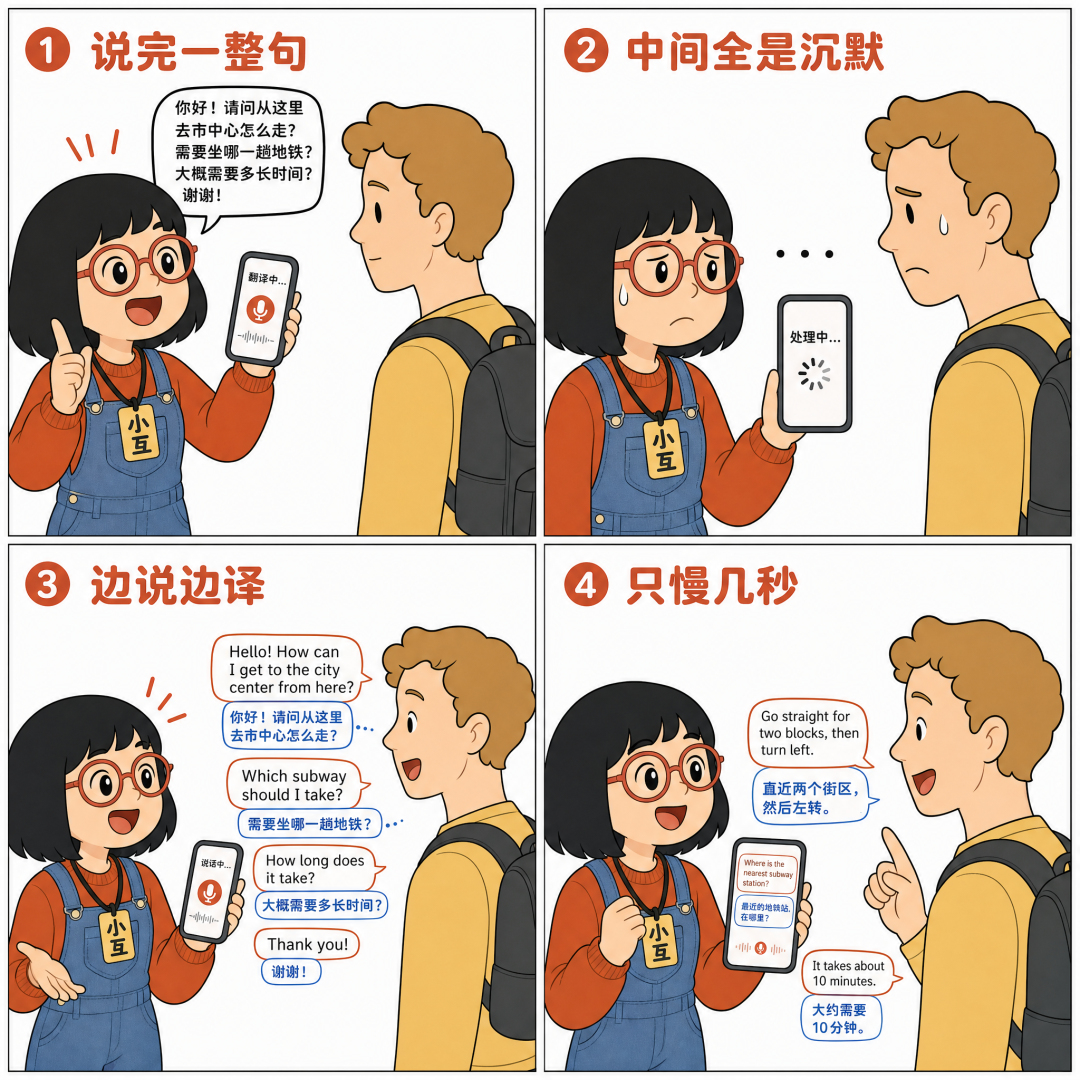
过去的翻译工具基本都是「轮次制」的:你说完一整句,系统停顿,处理,再输出翻译,中间那段沉默就是在等上下文。
3.5 Live Translate 改了这个逻辑——它在你说话的同时持续生成翻译语音,像同声传译一样跟着你走。模型内部在做一个持续的权衡:多等一会儿能拿到更多上下文、翻得更准,但等太久就跟不上说话人了。它在两者之间动态调节,输出流畅的音频,全程只比说话人慢几秒。
一个具体的画面:你在巴塞罗那跟一个只说西班牙语的导游走街串巷,他在讲这栋楼的历史。你把手机贴到耳朵上,听筒里传出来的英文翻译几乎和他的西班牙语同步,语调起伏也跟着他走。他激动的时候翻译声音也快,他停下来想词的时候翻译也自然地缓一拍。

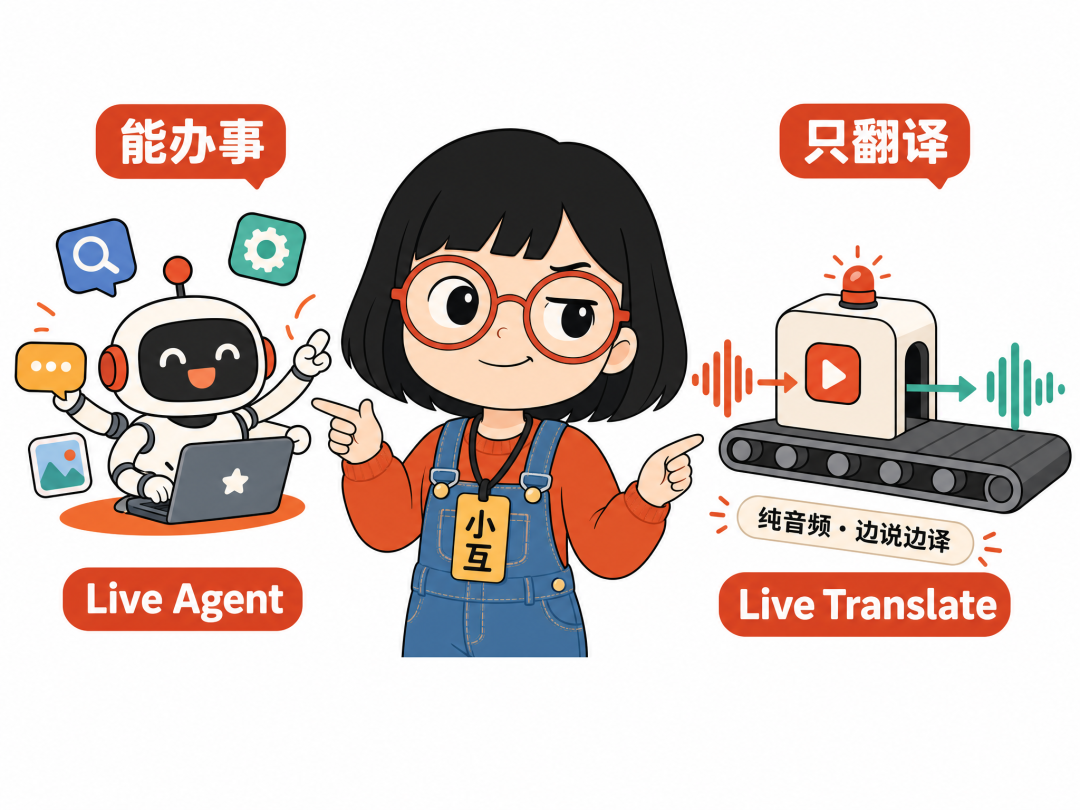
Live Agent vs Live Translate
Google 的 Live API 现在有两种模式:普通的 Live Agent 和 Live Translate。名字像,但用的是完全不同的架构。
| 维度 | Live Agent(普通模式) | Live Translate(翻译模式) |
|---|---|---|
| 模型角色 | 充当助理,能聆听、推理、采取行动 | 充当翻译器,实时翻译流水线 |
| 交互方式 | 基于回合,依赖暂停和意图检测 | 连续流处理,边说边译不等轮次 |
| 工具和 Agent 能力 | 支持函数调用、Google 搜索、指令 | 不支持,纯翻译 |
| 输入模态 | 文本、音频、视频、图片 | 仅音频 |
| 配置复杂度 | 需要配置生成参数、语音、工具、系统指令 | 只需设 target_language_code 和几个开关 |
为什么只接受音频,不接受文本?
因为这个模型从底层就是一个端到端的语音到语音模型。它解决的核心问题是"在对方还没说完的时候就开始翻译并输出声音"。音频是连续的流,每 100 毫秒一个块不断涌进来,没有明确的句子边界,模型要在这个流里实时判断说话人在说什么语言、句子说到哪里了、现在翻还是再等一下能翻得更准。
文本是离散的、完整的,不存在"说到一半要不要先翻"的问题,也不需要保留语调和节奏。需要文本翻译的话,Google Translate 的文本 API 和 Gemini 文本模型已经能做了。
三个关键能力
1. 自动语言检测
不需要提前告诉模型"我说的是中文,帮我翻成英文"。你直接说,它自己判断你在说什么语言,自动翻成目标语言。在多人多语言的场景下,比如一个会议里有人说日语、有人说法语、有人说中文,模型可以分别处理,不用每次手动切换。
2. 语音特征保留
模型会尝试保留原始说话人的语调(intonation)、节奏(pacing)和音高(pitch)。你说得快它翻得也快,你强调某个词它也会在翻译语音中体现重音。
东南亚打车平台 Grab 正在测试这个模型,用于司机和乘客在接驾时的多语言通话。Grab 每月有超过 1000 万通语音电话通过平台拨出。一个泰国司机和一个日本游客之间的电话,双方各说各的语言,模型在中间做实时双向翻译。
3. 自动滤除噪音
在安静的办公室里做翻译不难,难的是在嘈杂的街头、拥挤的餐厅、或者机场候机厅。模型会主动滤除噪声和音乐来生成清晰的语音。
三条使用路径
路径一:Google Translate App(普通用户)
在 Android 或 iOS 上打开 Google Translate,进入 Live Translate 功能。连接任意蓝牙或有线耳机,选好目标语言,对方说话时你通过耳机听到接近实时的翻译。
Android 独占的「听筒模式」:不需要耳机。直接把手机像打电话一样贴到耳朵上,翻译后的音频通过手机听筒播放。适合两个场景:手边没耳机,或者不想让周围的人听到翻译内容。
一个具体的用法:你在东京的居酒屋,店员在用日语推荐今天的菜,你把手机贴到耳朵上,听筒里实时传出中文翻译。店员看到的只是你在"打电话",整个过程自然不尴尬。

路径二:Google Meet(企业用户)
Google Meet 的语音翻译功能将升级为 3.5 Live Translate:
| 维度 | 升级前 | 升级后 |
|---|---|---|
| 支持语言数 | 5 种 | 70 多种 |
| 语言组合 | 仅限和英语互译 | 2000 多种语言组合 |
| 操作方式 | 需要提前配置 | 即时访问 |
目前是私有预览阶段,本月先对部分 Google Workspace 企业客户开放,今年晚些时候更大范围推出。
路径三:Gemini Live API(开发者)
开发者可以通过 Gemini Live API 在自己的应用中集成实时翻译能力。模型名称是 gemini-3.5-live-translate-preview。
最小可用配置:
config = types.LiveConnectConfig(
response_modalities=["AUDIO"],
translation_config=types.TranslationConfig(
target_language_code="zh-Hans", # 目标语言,BCP-47 代码
echo_target_language=True # 输入已是目标语言时是否回放
)
)两个核心参数:
target_language_code:你要翻成什么语言,用 BCP-47 代码指定。"zh-Hans" 是简体中文,"ja" 是日语,"en" 是英语(默认值)echo_target_language:如果说话人说的本来就是目标语言怎么办?设为 true,模型原样回放这段音频;设为 false(默认),模型保持静默不输出
可选配置,转写文本:
如果你不仅需要翻译后的音频,还需要文字版本(比如做字幕),可以在配置中加上转写:
config = types.LiveConnectConfig(
response_modalities=["AUDIO"],
input_audio_transcription=types.AudioTranscriptionConfig(), # 输入语音转文字
output_audio_transcription=types.AudioTranscriptionConfig(), # 翻译语音转文字
translation_config=types.TranslationConfig(
target_language_code="zh-Hans",
echo_target_language=True
)
)音频格式要求:
| 方向 | 格式 | 采样率 | 声道 |
|---|---|---|---|
| 输入 | 16 位 PCM,小端序 | 16kHz | 单声道 |
| 输出 | 16 位 PCM,小端序 | 24kHz | 单声道 |
音频以 100 毫秒的块发送。输出采样率 24kHz 比输入的 16kHz 高,翻译后的语音音质比输入更好。
安全标记:SynthID
所有 3.5 Live Translate 生成的音频都用 SynthID 做了水印标记。这个水印人耳听不出来,但可以被技术手段检测到,目的是标记哪些语音是 AI 生成的,防止有人拿实时翻译后的语音去冒充真人。
Model card:deepmind.google/models/model-cards/gemini-3-5-audio
苏米观察
传统同声传译员培训周期以年计算,全球能做好的人极少,收费极高。3.5 Live Translate 当然还做不到专业同传的水平——语音复制会飘、相似语言会混淆、多人快速对话会卡声音,这些限制 Google 自己也承认了。
但它把"边听边译"从一个稀缺的专业技能变成了手机上随时可用的功能,覆盖 70 多种语言。对于旅行问路、跨国开会、打车点菜这些日常场景,够用的门槛已经跨过去了。
快速上手入口:
- 在线体验:aistudio.google.com/live
- API 文档:ai.google.dev/gemini-api
- 示例代码:github.com/google-gemini/gemini-live-api-examples