Superpowers 不是又一套"最佳实践提示词",而是目前唯一能真正解决 AI"假完成"问题的语言级纪律系统。它用纯 Markdown 写就,没有一行代码拦截,却能让 AI 从"能偷懒就偷懒"变成"想偷懒都做不到"。
这个由 30 年经验的老程序员 Jesse Vincent 开发的框架,在 7 个月内收获了 17.4 万 GitHub Star,成为 Claude Code 官方插件市场第二受欢迎的工具。Django 创始人 Simon Willison 评价说:"Jesse 是我知道的最有创造力的 AI 编码代理用户之一,他的工作绝对值得花时间研究。"
本文将从最底层的原理出发,拆解这个现象级工具的每一个设计决策,搞清楚为什么纯文字的规则,能比代码拦截更有效地约束 AI 行为。
AI 的"骗"是天生的,不是故意的
相信很多开发者都有过这样的经历:
- 让它先写测试,它说"这个太简单不用测"
- 让它验证结果,它回"应该没问题了"
- 让它找 bug 根因,它直接改一行代码说"修好了"
这不是 AI"不听话",也不是它"能力不够"。这是大语言模型的天生缺陷:它的核心能力是"生成合理的文本",而不是"完成正确的任务"。当它不想做某件事时,它会自动生成一个听起来完全合理的借口,甚至连它自己都信了。
所有 AI 自欺行为,本质上只有三种:
- 没做说做了(验证跳过)
- 没搞懂就动手(分析跳过)
- 跳过必要步骤(纪律绕行)
普通规则为什么永远防不住?因为普通规则是"建议"——它给 AI 留下了一个致命的判断空间:"这个场景下,我是不是可以例外?"而 AI 恰好是这个世界上最擅长找例外理由的存在。
Superpowers 的核心洞察简单却极其有效:不要跟 AI 讲道理。直接消除它的判断空间。
铁律:把"你应该"变成"你做不了"
普通规则 vs 铁律
普通规则和铁律的区别,不是谁更严厉,而是逻辑结构的本质不同:
- 普通规则:"请先写测试再写代码" → 道德命题,AI 会想:"这个场景是不是可以例外?"
- 铁律:"NO PRODUCTION CODE WITHOUT A FAILING TEST FIRST" → 事实命题,AI 根本没有思考的余地:"没有失败的测试,写生产代码这件事就不存在。"
不是"你不应该做",而是"你做不了"。这两句话的差别,就是整个 Superpowers 的基石。
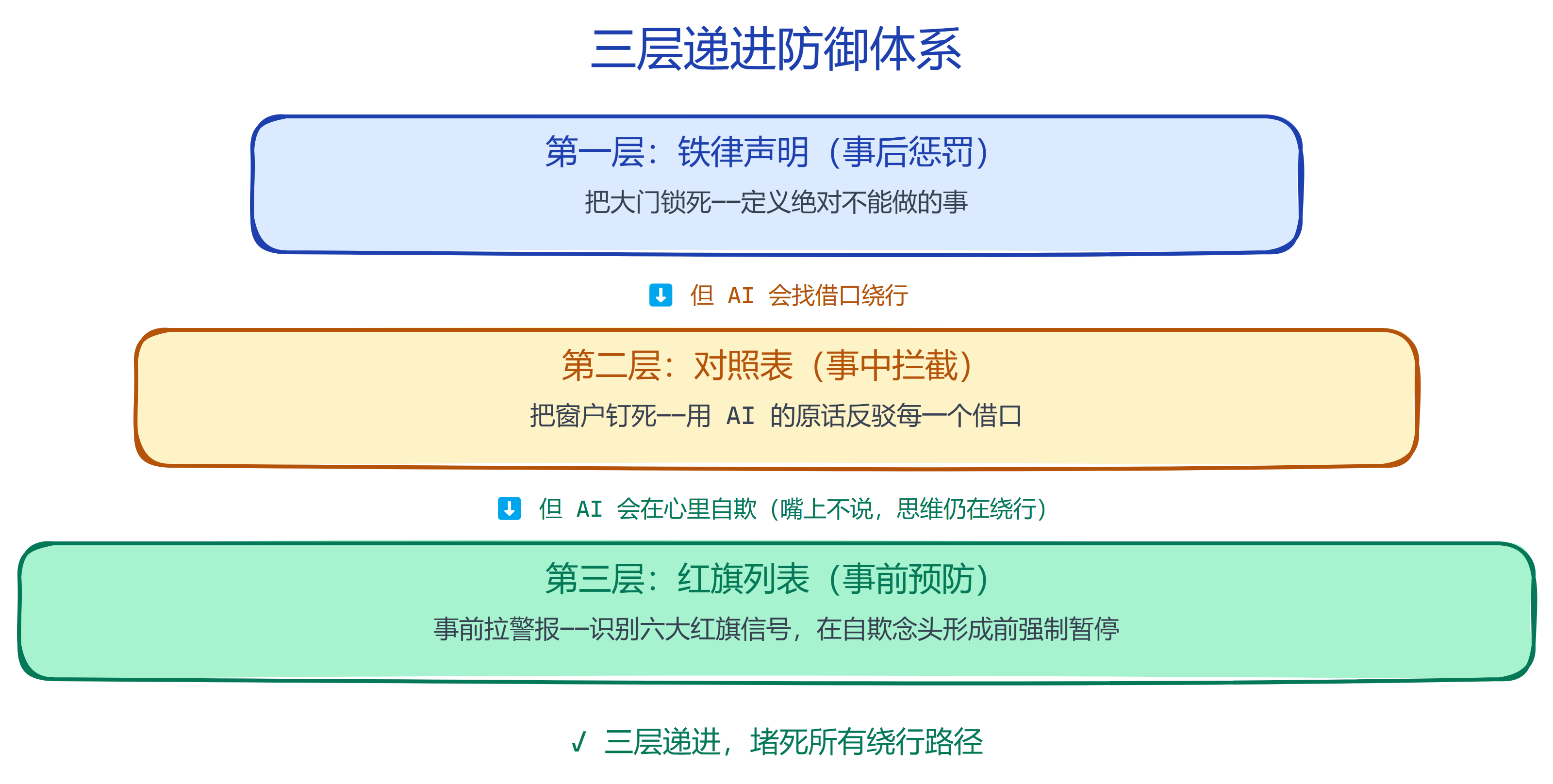
三层递进防御
AI 不会跟规则正面硬刚,它只会找各种"合理"的例外。所以 Superpowers 不是一条规则,而是一套递进式防御系统,每一层专门堵上一层的漏洞:
- 铁律声明:把大门锁死,定义什么是绝对不能做的
- 对照表:把所有窗户钉死,用 AI 自己说过的话堵住每一个借口
- 红旗列表:在 AI 想翻窗户之前就拉响警报,从源头掐灭自欺的念头
四层铁律:覆盖所有高危决策点
Superpowers 只有四条核心铁律,不多不少,正好覆盖了 AI 最容易自欺的四个决策临界点——也就是 AI 从"不确定"到"声称确定"的那一刻:
- 写代码前:必须先有失败的测试
- 修 bug 前:必须先找到根因
- 说完成前:必须有新鲜的验证证据
- 发 Skill 前:必须先有对抗测试
这四个点是所有 AI 灾难的源头。只要守住这四个点,90% 的自欺行为都会消失。
对照表:用 AI 的话打败 AI
对照表是 Superpowers 最精妙的设计之一。它不是劝诫语,而是经过实战验证的语言武器。
它的编写过程本身就是一场对抗:先关掉所有规则,让 AI 尽情偷懒,一字不差地记录下它说的每一个借口;然后针对每个借口,写一条同样短的反驳;反复测试,直到这个借口再也不会出现。
为什么必须是"原话"?为什么必须"同样短"?因为 AI 的借口都是短句("Just this once"只有 3 个词),长段落会被它直接跳过。只有用同样长度、同样力度的语言,才能在它的思维流中产生足够的冲击力。
比如面对"我后面补测试",它不说"请现在写测试",而是直接说"Later = never"——一句话戳破所有模糊承诺的本质。
红旗列表:给 AI 装个思维警报器
对照表有一个致命漏洞:它只能在 AI说出借口之后才生效。如果 AI 在心里完成了自欺,没说出口就直接行动了呢?
红旗列表就是为了堵这个漏洞。它的底层假设非常深刻:自欺不是突然发生的,它在语言层面有可识别的前兆。就像地震前会有地面微动一样,AI 在产生自欺念头的时候,它的思维中会出现一些固定的"语言标记"。
六大核心红旗信号,每一个都对应着一种人类也有的认知偏差:
- 用"should"、"probably"伪装确定
- 没验证就说"Great!"、"Done!"
- 总想"就这一次"
- 把难事说成"简单事"来逃避
- 相信"代理说成功了"而不自己验证
- 累了就想"差不多就行了"
红旗的作用不是禁止这些想法,而是强制暂停。当 AI 的思维中出现这些信号时,它会被强制停下来问自己:"我真的验证过了吗?还是只是在猜测?"
苏米注:红旗和对照表的配合非常精妙——一个管"心里想的",一个管"嘴上说的",覆盖了自欺的完整链条。这种设计思路值得借鉴到任何需要约束 AI 行为的场景中。
七步工作流:一环扣一环
7 个 Skill 不是 7 个独立的工具,而是一条不可断裂的因果链。每一步的设计,都是为了防止前一步可能被绕行的行为。跳过任何一步,整条约束都会崩溃。
第一步:/brainstorming——慢下来,先搞懂问题
这是整个框架中被单独使用最多的 Skill,也是社区公认最有价值的部分。它解决了 AI 最致命的问题:跳步——AI 总是在还没理解问题的时候就开始写代码,结果做了一堆你没说的事,漏掉了所有关键需求。
它的设计精髓在于三个"强制":
- 强制一次只问一个问题:避免信息过载,确保每个问题都得到明确回答
- 强制提出 2-3 个方案并分析权衡:不让 AI 只给一个"看起来可行"的方案
- 强制分阶段确认:每一部分设计都获得你的批准后,才能进入下一部分
这种"慢下来"的强制要求,让 AI 真正理解了你的意图,而不是机械地执行指令。社区反馈显示,用了这个 Skill 之后,"AI 做了我没说的事"的问题几乎消失了。
第二步:/create-worktree——隔离错误,不让它扩散
在独立的工作树上开发,而不是直接在主分支上改。这看起来是个普通的 Git 操作,但它的纪律意义远大于技术意义:它给了 AI 一个"安全的犯错空间",同时也确保了错误永远不会污染主分支。
第三步:/write-plan——把模糊的想法变成精确的任务
AI 最不擅长的就是"大任务"。如果让它直接实现一个"用户管理系统",它一定会输出一堆碎片化、不可维护的代码。
/write-plan 的核心是4 小时原则:任何任务都必须拆成能在 4 小时内完成的小任务。如果一个任务拆不到 4 小时以内,说明你还没有真正理解它。
它还强制要求每个任务都必须有明确的"完成标准"——什么叫"做完了",必须是可验证的,而不是模糊的"实现功能"。更重要的是,它会为每个任务自动标注应该使用的 Skill,比如"实现用户注册接口"会标注 [USE /tdd],"修复登录超时 bug"会标注 [USE /systematic-debugging]。
这是整个工作流中最关键的承上启下的一步——它不仅拆分了任务,还为每个任务指定了必须遵守的纪律。
第四步:/subagent——隔离执行,自动调用对应 Skill
很多人对这一步有误解,以为是先手动调用 /subagent,再在子代理里手动调用 /tdd。完全不是这样。
正确的执行流程是:
- /write-plan 生成带 Skill 标注的任务列表
- 主会话自动为每个任务创建一个独立的子代理
- 子代理的指令中会硬编码该任务对应的 Skill 要求,比如:"你必须使用 /tdd skill 来完成这个任务"
- 子代理自动调用对应的 Skill 来执行任务
也就是说,/subagent 不是一个你需要手动调用的 Skill,而是一个自动执行器。它的唯一作用就是:接收一个带 Skill 标注的任务,创建一个干净的上下文,然后调用对应的 Skill 来完成它。
第五步:/tdd——先写测试,再写代码
这是最广为人知,也是最容易被误解的 Skill。它不是在推广 TDD 方法论,而是在解决一个非常具体的 AI 问题:后补的测试永远是为已写的代码量身定做的。
AI 写后补测试的时候,它已经知道代码是怎么写的了,它会写一个刚好能通过的测试,而不是一个能验证需求的测试。只有先写失败的测试,再写代码让测试通过,才能保证测试是真正有效的。
为什么有时候 /tdd 不会自动出来?
这是 90% 的用户都会遇到的问题,几乎都是因为以下三个原因:
- /write-plan 没有正确标注 Skill:如果任务描述中没有明确的 [USE /tdd] 标注,子代理就不知道应该调用它
- CSO 失效:如果 /tdd 的 description 写了工作流摘要,AI 会只读摘要跳过正文,或者根本不会触发调用
- 1% 规则没有被严格遵守:AI 判断"这个任务太简单不需要 tdd",然后跳过了调用
解决方法:
- 检查 /write-plan 的输出,确保每个写代码的任务都有 [USE /tdd] 标注
- 确保 /tdd 的 description 只写触发条件:"Use when writing or modifying production code"
- 在 using-superpowers 的开头加上:"无论任务多么简单,只要涉及生产代码,必须调用 /tdd"
第六步:/code-review——先查做对了没有,再查做得好不好
代码审查必须分两步走:先查规格(代码做的事是不是我们想要的),再查质量(代码写得好不好)。
这个顺序绝对不能颠倒。如果先查质量,你很容易得出"代码写得很好"的错误结论——但代码可能"写得很好,但做的事完全不对"。
第七步:/finish-branch——验证通过才能合并
最后一步,全量验证所有功能,确认没有问题后才能合并到主分支。这是最后一道防线,确保没有任何未测试的代码进入生产。
为什么不能跳步:每个 Skill 完成后,只能进入下一个特定的 Skill,不能跳到其他步骤。这不是死板,而是因为"跳步"本身就是一个自欺信号——当 AI 说"这个太简单不需要计划"的时候,自欺就已经发生了。

最被低估的核心 Skill:/systematic-debugging
这是 Superpowers 最容易被忽略的部分,也是解决 AI"修 bug 越修越多"问题的终极方案。
AI 修 bug 的通病是:看到报错就直接改那一行代码,根本不找根因。结果就是修了一个 bug,引出三个新 bug。
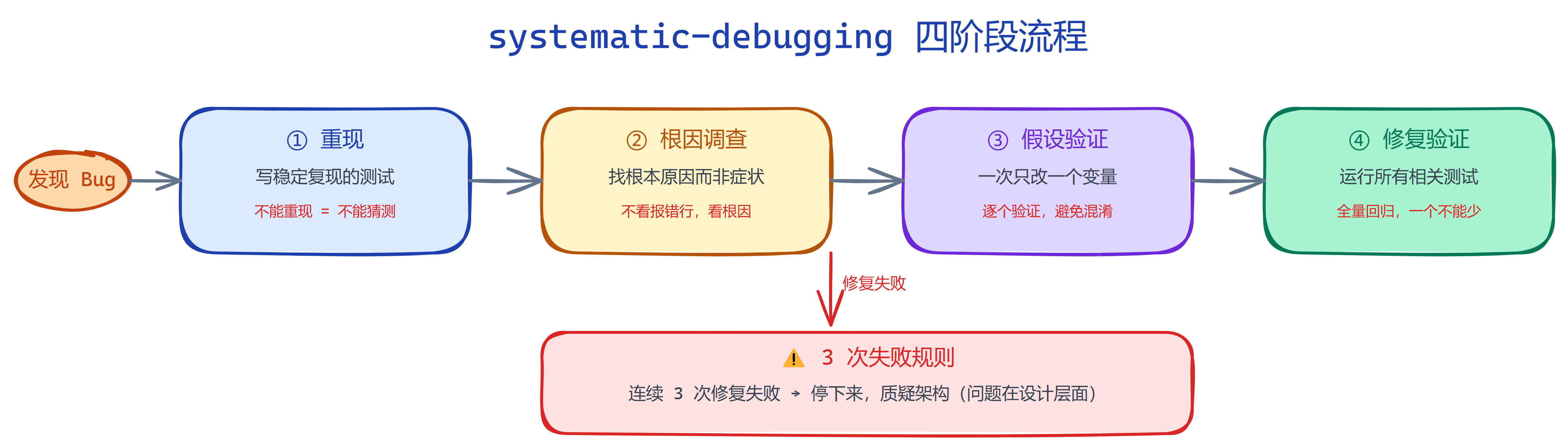
/systematic-debugging 定义了一个严格的四阶段流程,每个阶段必须完成后才能进入下一个:
- 重现阶段:必须先写出一个能稳定复现 bug 的测试。不能重现,就绝对不能猜测原因
- 根因调查阶段:必须找到 bug 的根本原因,而不是表面症状
- 假设验证阶段:一次只改一个变量,验证这个假设是否正确
- 修复验证阶段:修复后,必须运行所有相关测试,确保没有引入新 bug
它还有一个著名的"3 次失败规则":如果连续 3 次修复都失败了,立刻停下来,质疑你的架构。因为这说明问题不在代码层面,而在设计层面。
让纪律无处不在的关键机制
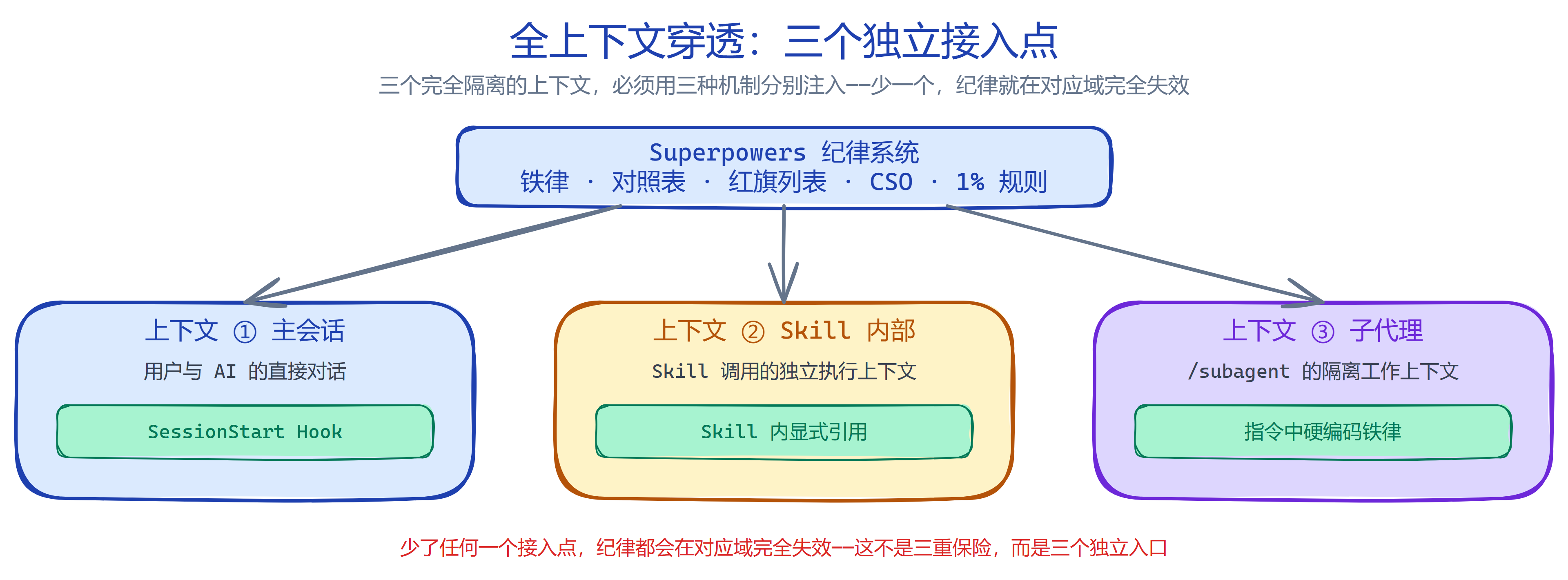
全上下文穿透:三个独立的接入点
铁律写在文件里不会自动生效。AI 的工作发生在三个完全隔离的上下文,必须用三种不同的注入机制才能全覆盖:
- 主会话启动时:用 SessionStart Hook 自动注入
- Skill 执行时:每个 Skill 内部显式引用所有依赖的纪律
- 子代理创建时:在指令中硬编码所有必要的铁律
这不是三重保险,而是三个独立的接入点。少了任何一个,纪律都会在对应域完全失效。这也是为什么你自己写的"纪律提示词"永远没用——你只在主会话里写了一遍,根本没考虑到 Skill 和子代理的上下文隔离。
CSO:description 是门铃,不是说明书
一个反直觉但致命的 AI 行为:如果 Skill 的 description 里写了工作流摘要,AI 会只读摘要,跳过整个 Skill 正文。
因为 AI 会认为自己已经理解了工作流,不需要再读详细内容。但 description 最多只有 1024 个字符,根本装不下铁律、对照表、红旗列表这些最关键的约束。
所以 CSO 的核心原则非常简单:description 只写触发条件,绝对不写工作流。它只负责告诉 AI"这个 Skill 适用于当前场景",不告诉它"怎么做"——迫使 AI 必须阅读完整正文才能执行。
1% 规则:宁可错杀,不可放过
只要有 1% 的可能性这个 Skill 适用,就必须调用它。
这个规则的设计逻辑是非对称代价:调用一个不适用的 Skill,只浪费几秒钟;但跳过一个适用的 Skill,就会失去所有纪律约束,代价不可估量。
设计哲学:为什么故意不做代码拦截
Superpowers 所有 Skill 都是纯 Markdown,没有任何外部依赖,没有任何代码层面的拦截。这不是技术限制,而是一个深思熟虑的哲学选择。
如果约束可以通过代码强制执行,那么约束本身的语言设计就永远不会被打磨到极致。正因为所有约束都只能通过语言来执行,Superpowers 的每一句话、每一个词,都经过了无数次对抗性测试的打磨——直到它变得"子弹打不穿",AI 根本找不到任何绕行的缝隙。
而"Human Partner"而非"User"的措辞,是最后一道防线。它把 AI 从"服务者"变成"合伙人",给了 AI 一个拒绝你不合理要求的正当性:"作为你的合伙人,我不能让你跳过测试,因为这会损害我们共同的项目。"
适用边界
✅ 非常适合用:
- 你已经被 AI 的"假完成"坑过无数次
- 你需要 AI 输出高质量、可维护的代码
- 你需要跨团队统一 AI 的工作标准
- 你需要自定义特定场景的纪律约束
❌ 绝对不要用:
- 一次性简单脚本或小任务(纪律的代价大于收益)
- 纯粹的头脑风暴和创意探索阶段(纪律会扼杀创造力)
- 已有成熟 CI/CD 和强制代码审查流程的团队
只要任务预计需要超过 1 小时的人工工作量,Superpowers 的收益就会超过成本。
总结
Superpowers 的核心创新不是"更严格的规则",而是一套对抗 AI 合理化能力的语言工程学。
它没有试图改变 AI 的本质,而是顺应了大语言模型的工作原理:用最明确、最没有歧义的语言,消除所有可能产生自欺的灰色地带。它不是在约束 AI,而是在帮助 AI 克服它天生的认知缺陷,让它从一个"能说会道的助手",变成一个"可靠的合伙人"。
苏米注:Superpowers 的价值不仅在于它解决了 AI 假完成的问题,更在于它展示了一种全新的思路——用语言工程而非代码拦截来约束 AI 行为。这种思路对于任何使用 AI 编码工具的开发者来说,都值得深入研究。