大语言模型的推理能力正在经历一场深刻变革——测试时计算扩展(Test-Time Scaling)范式已成为新的性能增长引擎。然而,标准注意力机制的复杂度随上下文长度呈平方级增长,这是制约超长上下文处理的根本瓶颈。
现实任务越来越"长":复杂智能体工作流、跨文档知识分析、多轮深度推理……这一切都对百万级上下文提出了迫切需求。
DeepSeek 正式发布 DeepSeek-V4 系列,包含两个预览版本:
- DeepSeek-V4-Pro:1.6T 总参数,每次激活 49B,支持 100 万 Token 上下文
- DeepSeek-V4-Flash:284B 总参数,每次激活 13B,轻量高效版本
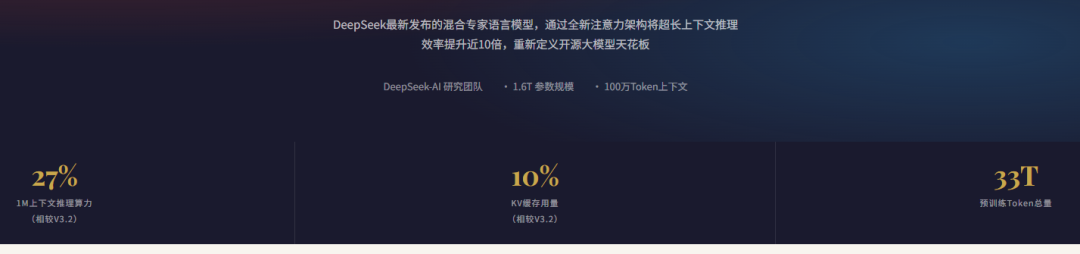
在 1M Token 场景下,KV 缓存仅为标准 BF16 GQA8 配置的约 2%,算力需求仅为前代 V3.2 的 27%。
四大架构创新
DeepSeek-V4 在 V3 架构基础上保留了 DeepSeekMoE 框架和多 Token 预测(MTP)策略,并引入三项关键创新:

CSA(压缩稀疏注意力)
将每 m 个 Token 的 KV 条目通过加权压缩融合为一个"压缩 KV 条目",然后用轻量级"闪电索引器"(Lightning Indexer)为每个查询 Token 挑选 top-k 个最相关的压缩 KV 条目,仅对这些选中条目执行多查询注意力计算。同时保留滑动窗口分支,确保对最近 Token 的精细依赖建模。
HCA(重度压缩注意力)
以更大的压缩率 m'(远大于 m)对 KV 缓存进行更激进的压缩,不再稀疏选择,而是对所有压缩后的条目执行密集注意力。CSA 和 HCA 交替使用,形成互补的混合注意力架构。
关键技术细节
- RoPE 旋转位置编码仅应用于查询和 KV 条目向量的最后 64 个维度,并在注意力输出上做反向补偿
- KV 缓存混合精度存储:RoPE 维度使用 BF16,其余维度使用 FP8,存储量接近纯 BF16 的一半
- 闪电索引器内部注意力计算采用 FP4 精度,超长上下文场景下进一步提速
- 路由专家权重采用 FP4 精度存储,未来硬件上理论可实现 1/3 额外加速
算力与内存效率
新架构带来的效率提升在超长上下文场景下尤为显著。100 万 Token 上下文下的对比:

- 算力:1M Token 场景下仅需 V3.2 的 27% 算力
- KV 缓存:1M Token 场景下仅需 V3.2 的 10% KV 缓存
- 存储:KV 缓存仅为标准 BF16 GQA8 配置的约 2%
苏米注:FP4×FP8 在当前硬件上与 FP8×FP8 峰值算力相同,但未来硬件支持后理论可实现 1/3 额外加速。这意味着 V4 的效率优势还有进一步释放的空间。
预训练:32T Token 炼就基座
DeepSeek-V4-Flash 和 V4-Pro 分别在 32T 和 33T 高质量多样化 Token 上完成预训练,涵盖数学、代码、网页、长文档等核心类别。长文档数据中特别加大了学术论文、技术报告的比重。
训练序列长度从 4K 逐步扩展至 16K → 64K → 1M,稀疏注意力在 64K 阶段引入,经过"闪电索引器热身"后投入全量训练。

评测结果显示:DeepSeek-V4-Flash-Base 在大多数基准上超越了参数量多得多的 DeepSeek-V3.2-Base,在世界知识和长上下文场景中优势尤为显著——证明了架构创新和数据质量的价值远超参数堆砌。
后训练:专家培育 + 策略蒸馏
后训练采用创新的两阶段范式:先独立培育领域专家,再通过在线策略蒸馏(OPD)将所有专家能力融合进统一模型。
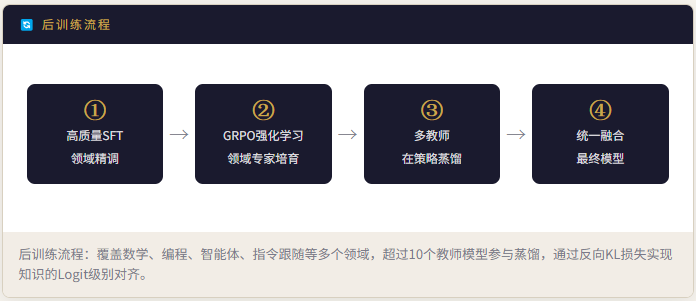
强化学习阶段放弃了传统的标量奖励模型,引入生成式奖励模型(GRM)——策略网络本身即充当评分者,将推理能力与评估能力联合优化,以极少的人工标注实现对复杂任务的高质量评分。
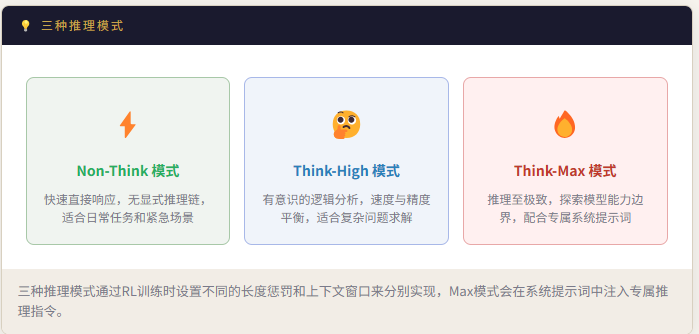
模型支持三种推理努力模式(Reasoning Effort),通过特殊标签控制不同强度的思维链推理。
评测结果:开源新标杆
DeepSeek-V4-Pro-Max(V4-Pro 的 Max 推理模式)在多项核心评测中刷新开源模型最高水准:
| 评测基准 | Claude Opus 4.6 | Gemini 3.1 Pro | DS-V4-Pro-Max |
|---|---|---|---|
| MMLU-Pro (EM) | 89.1 | 91.0 | 87.5 |
| SimpleQA-Verified | 46.2 | 75.6 | 57.9 |
| Codeforces (Rating) | — | 3052 | 3206 |
| Apex Shortlist | 85.9 | 89.1 | 90.2 |
| SWE Verified | 80.8 | 80.6 | 80.6 |
| BrowseComp | 83.7 | 85.9 | 83.4 |
| LongMRCR 1M | 92.9 | 76.3 | 83.5 |
| CorpusQA 1M | 71.7 | 53.8 | 62.0 |
关键突破:
- 代码竞赛:Codeforces 评级 3206,超越 GPT-5.4,在人类参赛者排行榜位列第 23 名
- 形式数学推理:Putnam 2025 竞赛题目达到完美 120/120 分,与 Axiom 系统并列
- 数学推理:Apex Shortlist 90.2 分,超越 Claude Opus 4.6
百万Token 长上下文真实表现
在 MRCR 长上下文检索任务中,DeepSeek-V4-Pro-Max 在 128K 以内保持了极高稳定性(Average MMR ≥ 0.82),超越 Gemini-3.1-Pro。超过 128K 后性能有所下降,1M Token 下仍落后于 Claude Opus 4.6。
在更贴近真实场景的 CorpusQA 任务中,DeepSeek-V4-Pro 同样优于 Gemini-3.1-Pro(62.0 vs 53.8)。
背后是一套异构 KV 缓存管理系统:两级缓存结构——针对 SWA 层和未压缩尾部 Token 的"状态缓存",以及针对 CSA/HCA 层压缩 KV 条目的"经典 KV 缓存",支持将压缩 KV 条目存储到磁盘以实现共享前缀的高效复用。
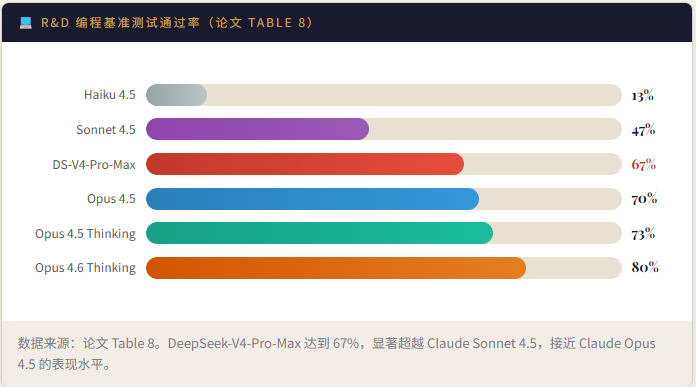
真实场景评测
论文构建了来自内部真实 R&D 工作流的编程评测集——涵盖 PyTorch、CUDA、Rust、C++ 等技术栈的功能开发、Bug 修复、重构与诊断任务,共 30 道题。
在中文写作能力上,DeepSeek-V4-Pro 与 Gemini-3.1-Pro 对比:功能性写作胜率 62.7% vs 34.1%;创意写作质量胜率达 77.5%。但在最高难度任务中,Claude Opus 4.5 仍以 52.0% vs 45.9% 保持微弱优势。
总结
DeepSeek-V4 系列的发布,标志着开源大模型在超长上下文高效处理能力上迈出了决定性一步:
- ✅ 效率飞跃:1M Token 场景下仅需 V3.2 的 27% 算力 / 10% KV 缓存
- ✅ 代码能力:Codeforces 评级 3206,首次以开源模型比肩顶级闭源系统
- ✅ 形式数学:Putnam 2025 完美 120/120 分
- ✅ 长上下文:1M Token 原生支持,超越 Gemini-3.1-Pro
- ✅ 模型开源:权重已在 HuggingFace 公开发布
论文坦承,当前架构在追求极致长上下文效率的同时略显复杂。未来团队将致力于精简架构、深入研究训练稳定性原理,并探索多模态能力融合。
HuggingFace:huggingface.co/deepseek-ai