一句话总结,这东西可能会让传统的 OCR(光学字符识别)彻底失业。
因为它能在视觉信息上做到——压缩 10 倍,精度仍高达 97%!
这意味着,AI 在“看图、读文档”时,既能更快、更省钱,效果还几乎无损。作为一个经常体验各种 AI 工具、测评 OCR 类产品的产品经理,我得说,这波真的有点震撼。
为什么这项技术这么重要?
我们都知道,大模型现在最大的“痛点”之一,就是读长文、看图太慢。
就像你把一份 200 页的 PDF 扔给 LLM,它要么卡到超时,要么看完就忘。
根本原因是:AI 在处理视觉信息时,需要把图片拆成无数个像素 token,这过程既费时又烧显卡。
而 DeepSeek 的这项新技术,就像教会了 AI “速读”——它不再死盯每个像素,而是只看关键的信息结构(文字、表格、布局),再编码成极少量的视觉 token。
举个例子:
以前一张文档要 1024 个 token 才能被理解;
现在只要不到 100 个。
而且神奇的是,这种“超压缩”之后,解码精度还能保持在 97%!
这基本颠覆了传统“压缩越狠、损失越大”的认知。
它是怎么做的?
DeepSeek-OCR 的底层逻辑其实很优雅:它用一种“多角色协作”的架构去理解图像。
你可以把它想象成一个分工明确的视觉团队:
SAM(感知专家):先快速扫描文档,抓取关键区域。
Token Compressor(压缩器):把冗余信息一口气压缩掉,只留下最有价值的视觉 token。
CLIP(知识理解家):对这些 token 进行全局理解,提炼核心语义。
DeepSeek-3B 解码器(语言生成器):把理解结果变成我们熟悉的文字输出,比如 Markdown 或 JSON。
这种流水线式设计,让它在速度、精度和算力成本之间找到了一个完美的平衡点。
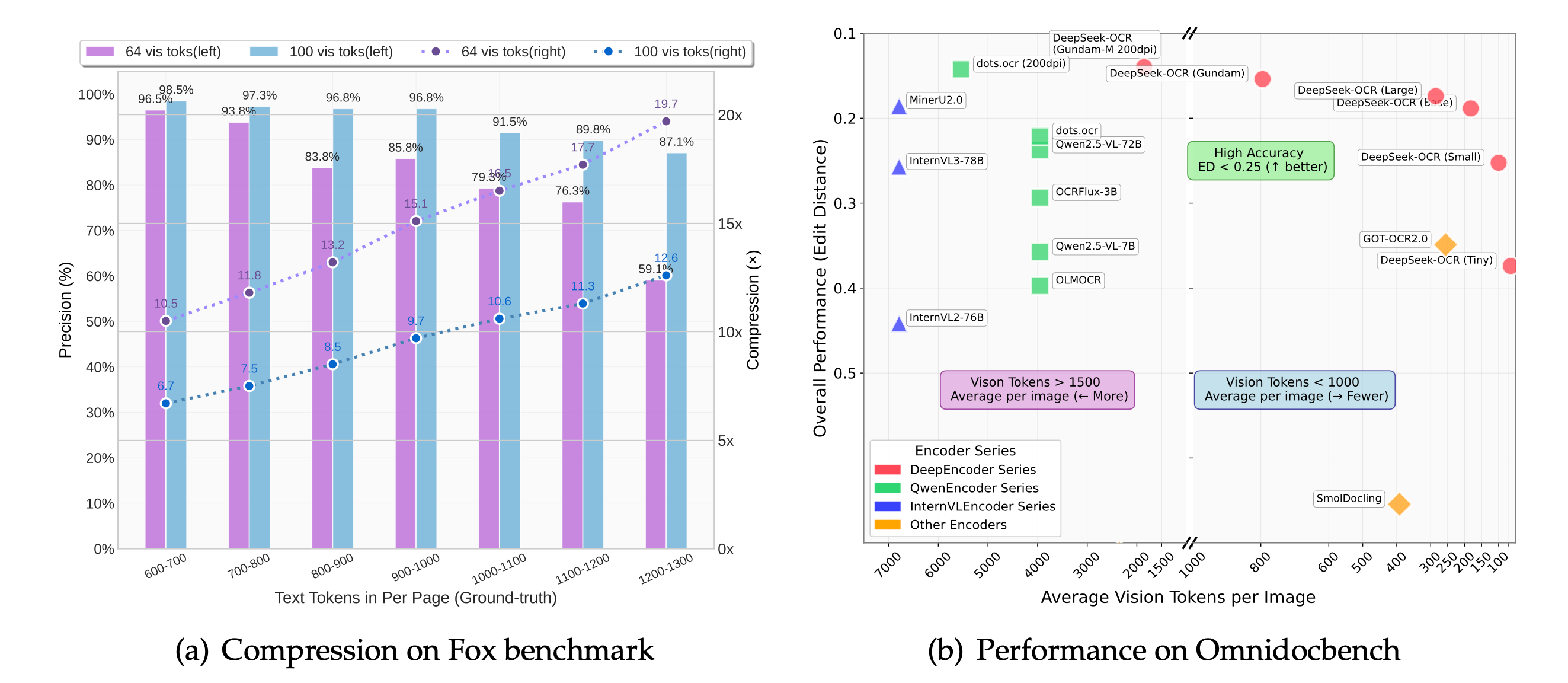
实测在文档基准测试(OmniDocBench)上,它只用 1/10 的 token 数量 就能超过市面上最强的 OCR 模型。
作为开发者或产品人,我们能从中获得什么?
最让我喜欢的一点是它完全开源!
你可以在 GitHub 或 Hugging Face 上直接用(官方脚本甚至给了完整的 PDF 解析 demo)。
GitHub: https://github.com/deepseek-ai/DeepSeek-OCR
Hugging Face: https://huggingface.co/deepseek-ai/DeepSeek-OCR
从应用角度看,DeepSeek-OCR 几乎可以立刻落地在三个方向:
文档 & PDF 处理场景
像合同审查、票据识别、档案数字化等高频业务,这项技术能让模型在保持精度的前提下,处理速度提升数倍、显存占用骤减。
他们公开的测试数据中,一块 A100-40G GPU 每秒可处理 2500 tokens/s ——非常夸张。
多模态 LLM 前端
多模态大模型的视觉部分,一直是性能瓶颈。 DeepSeek-OCR 可以直接当作视觉前端嵌入任意大语言模型,让模型快速具备图像理解能力。 不必再从零训练庞大的视觉模块,这点对中小团队非常友好。
多功能、灵活部署
支持多种分辨率、支持动态分辨率输入、支持 Transformers 与 vLLM 推理框架。 最有意思的是它的 Prompt 设计,比如:
-
“Convert the document to Markdown.” → 自动提取文档结构。
-
“Parse the figure.” → 专门识别图表。
-
“Locate <|ref|>xxxx<|/ref|> in the image.” → 精确定位特定文本。
这让它从一个 OCR 工具,进化成了一个“视觉智能助手”。
视觉领域的ChatGPT
过去,OCR 一直是“识别文字”的技术。
但 DeepSeek-OCR 展示的是一种新的范式:它不只是识别,而是理解。
它不仅能识别文档中的文字,还能把表格解析成 HTML、把化学公式转换成 SMILES 结构,甚至能理解几何图形。
换句话说,它已经不止是在“读”,而是在“看懂”。

这背后,是 DeepSeek 自研的 DeepEncoder + MoE 解码器架构的功劳。它在推理时只激活 15% 的参数,却能输出媲美大模型的结果。
这让“高性能、低成本”的多模态 AI 真正成为可能。
从个人体验到行业趋势
我自己试着跑了下 Demo,最大感受就是——流畅得离谱。
以前跑 OCR 任务,一页文档 GPU 占用蹭蹭往上跳;现在几乎轻松搞定。
从产品经理的角度看,这种“轻量高效”的视觉编码方式,可能会带来几方面影响:
-
AI 产品的使用成本进一步下降(特别是中小团队能玩得起多模态)。
-
LLM 的“视觉能力”升级,让文档理解、图文生成、图表解析等场景更自然。
-
视觉压缩成为新的研究方向——未来我们可能不再追求分辨率堆叠,而是追求信息密度。
总结
DeepSeek-OCR 的意义已经不只是“做了个更强的 OCR”。
它更像是在重新定义 AI 如何看世界——让模型从“像素级阅读”进入到“结构化理解”时代。
对于开发者,这是新的基础能力;对于我们这些产品经理,则是新的可能性。