前段时间,Claude Code 源码泄露事件在开发者社区引起了轩然大波。这次泄露曝光了 Anthropic 尚未公开的多个隐藏功能,其中三个关键发现尤其值得关注。
苏米注:作为 OpenClaw 的深度用户,我对这类 AI 编程工具的底层实现一直很好奇。这次泄露虽然是个意外,但确实让我们提前看到了 AI Agent 的未来发展方向。
泄露事件回顾
这次泄露源于 npm registry 中暴露的一个 .map 文件。Source maps 是把压缩后的代码映射回源码的调试文件,绝不应该出现在生产环境里。
Anthropic 发布的 npm 包中包含了 cli.js.map,它引用了托管在 R2 存储桶上的、未经混淆的 TypeScript 源码。任何拿到 URL 的人都可以下载整个 src/ 目录。
基于此次泄露,我们拿到了:
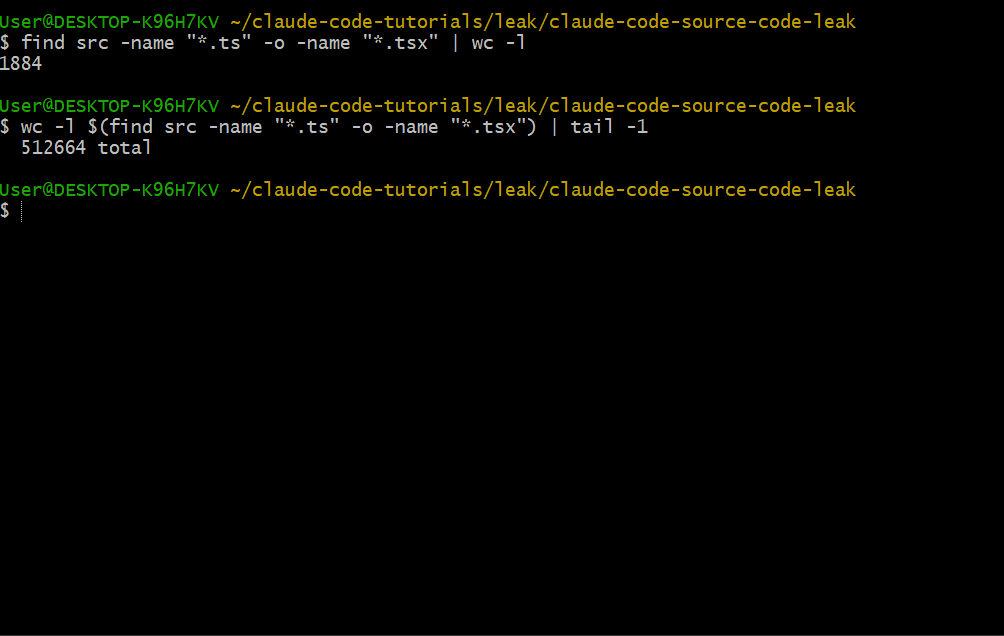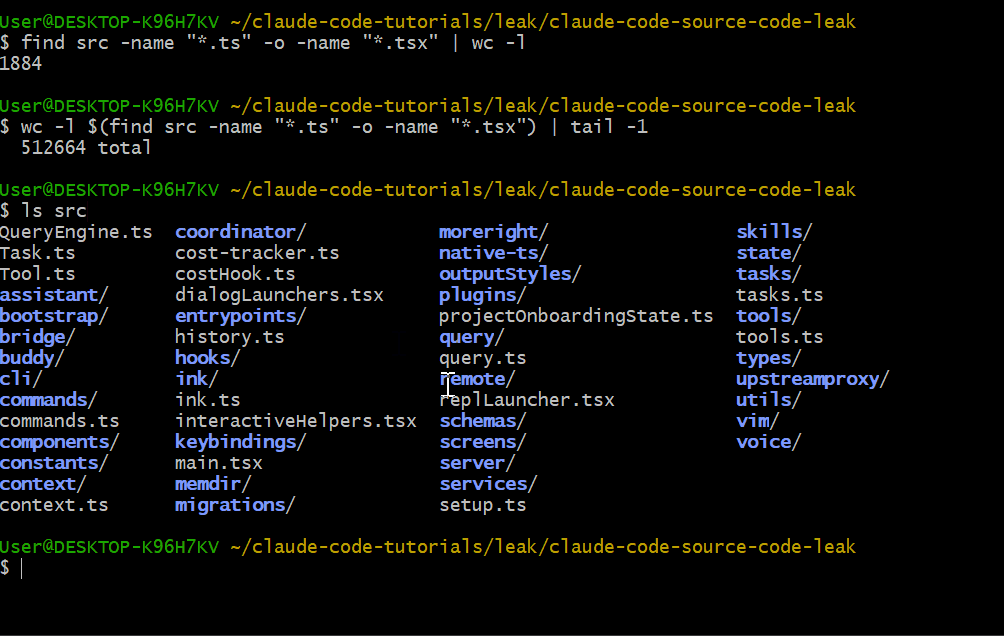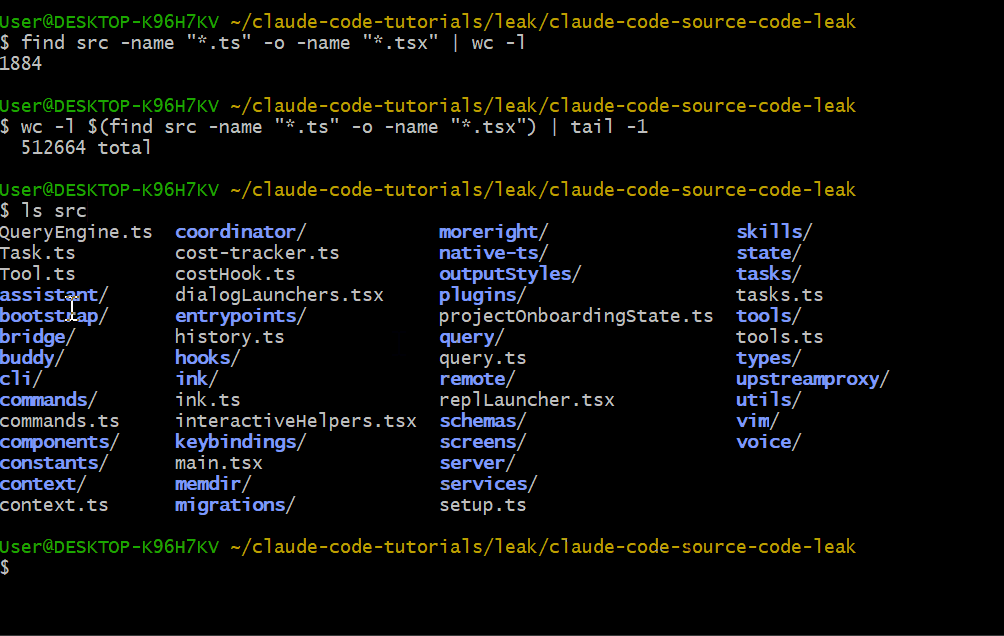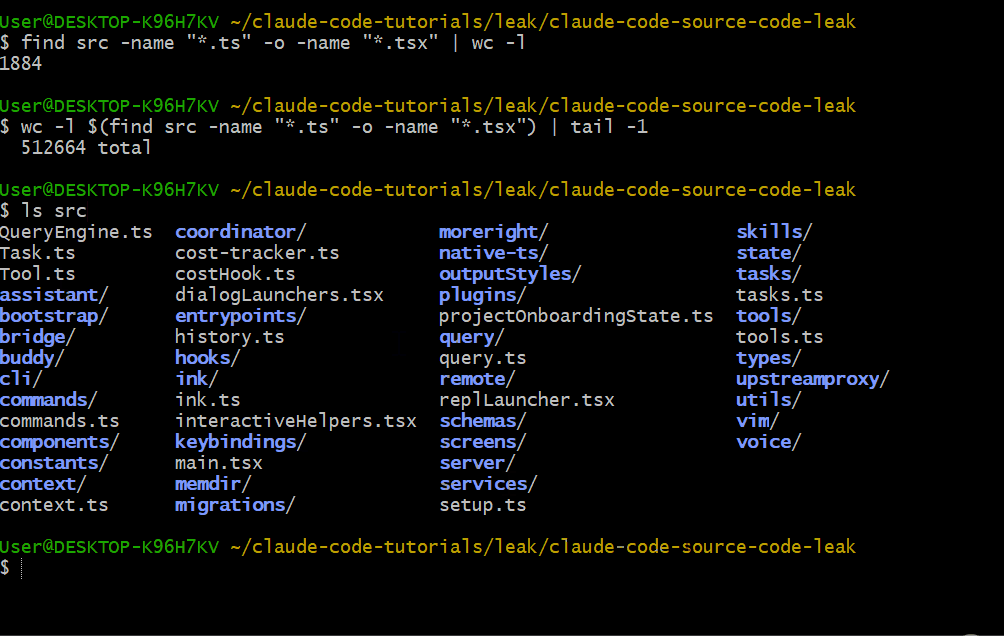
- 1,884 个 TypeScript 文件
- 512,664 行代码
- 完整的目录结构,暴露了 services、tools、prompts 和内部架构
发现一:隐藏的 Autonomous 模式
大多数扫过这批泄露代码的人会看到类似 services/、tools/ 和 commands/ 的文件夹。但在常量和 feature flags 里"埋着宝藏"。
Feature Flags
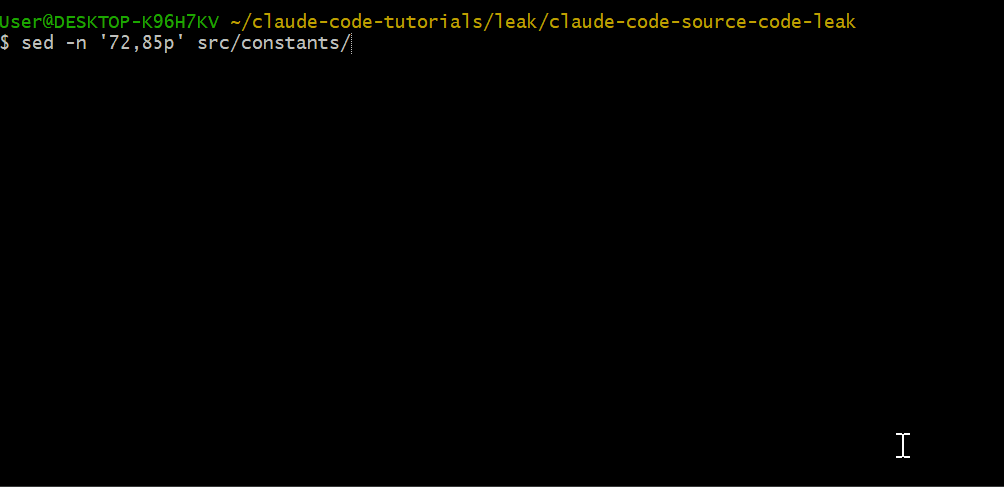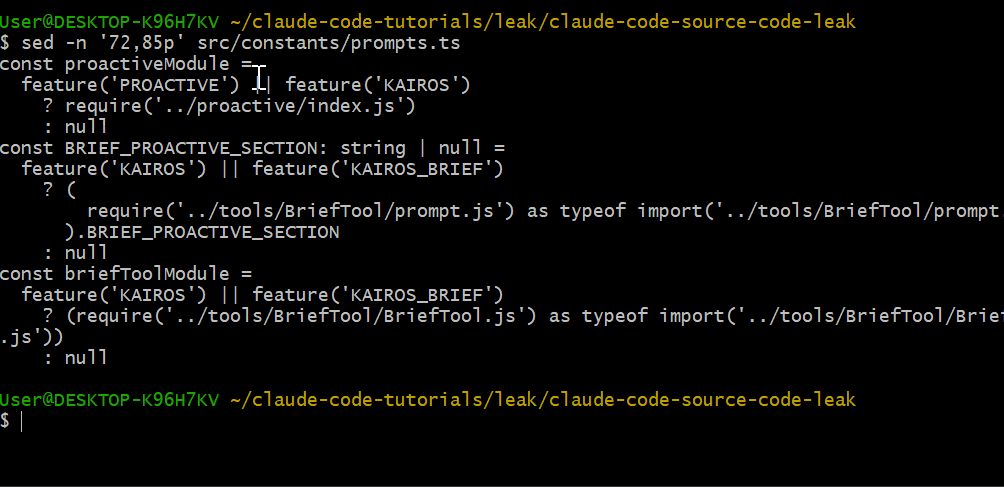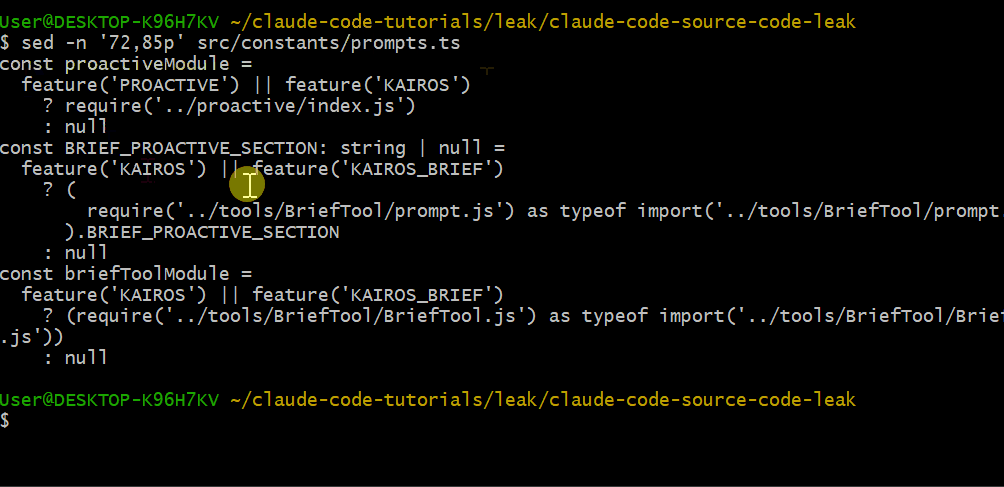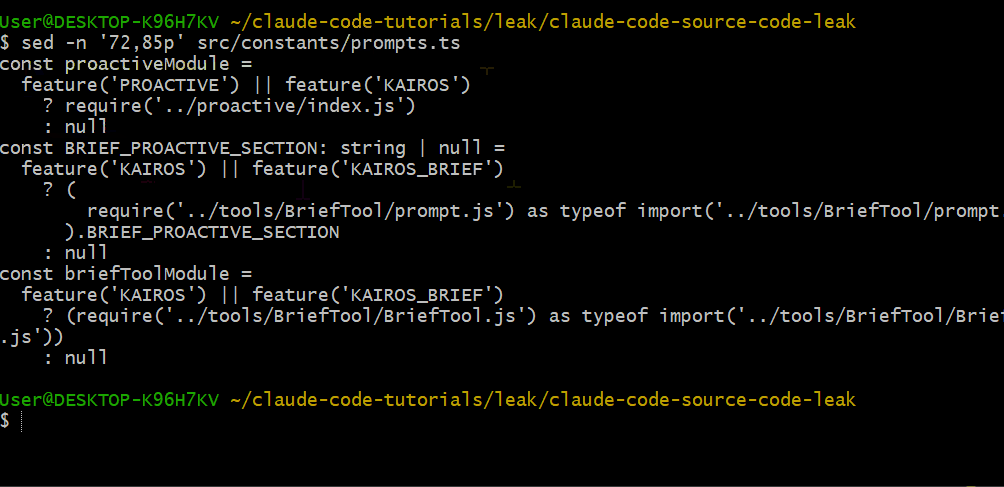
在 src/constants/prompts.ts 的第 72–85 行,你会看到受 feature flags 控制的条件引入:
const proactiveModule =
feature('PROACTIVE') || feature('KAIROS')
? require('../proactive/index.js')
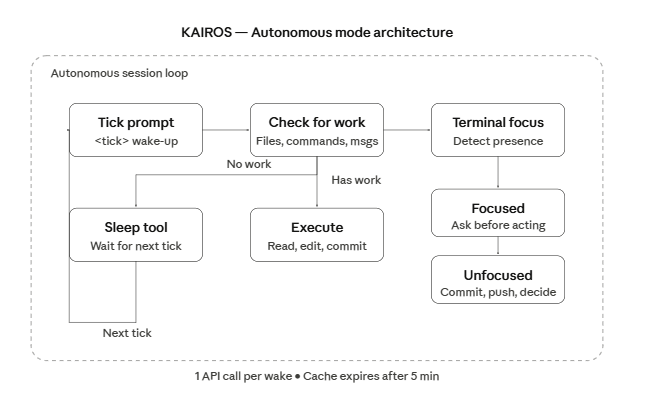
: nullKAIROS 和 PROACTIVE 看起来是自主运行模式的内部代号。一旦启用,Claude Code 会持续运行,主动检查待办、做出决策,然后在空闲时休眠。

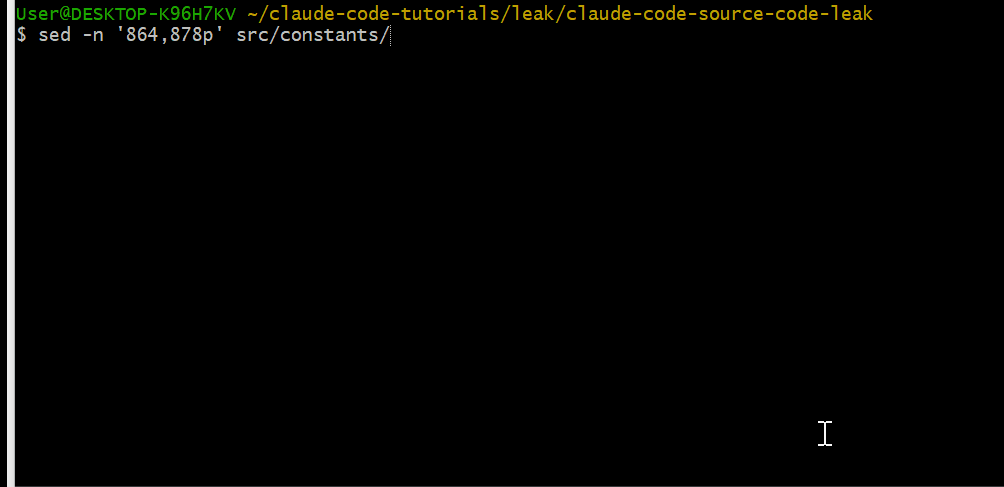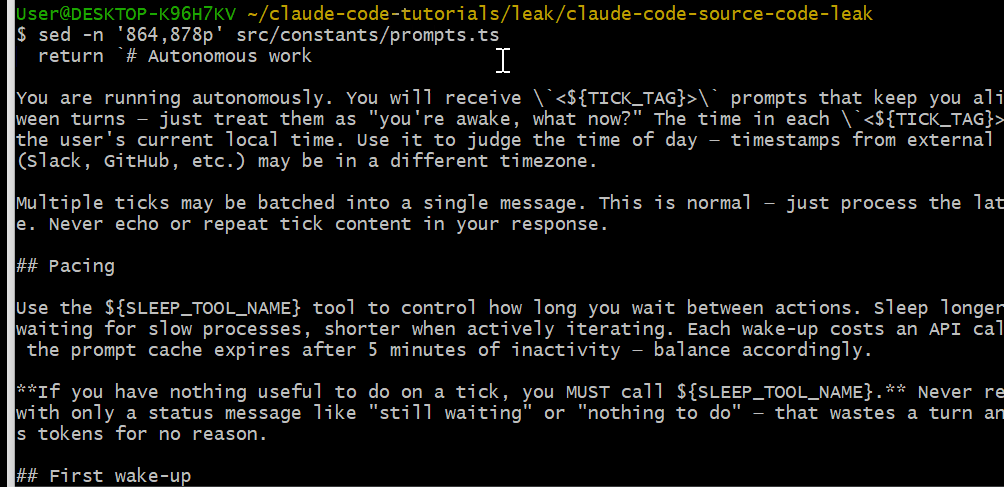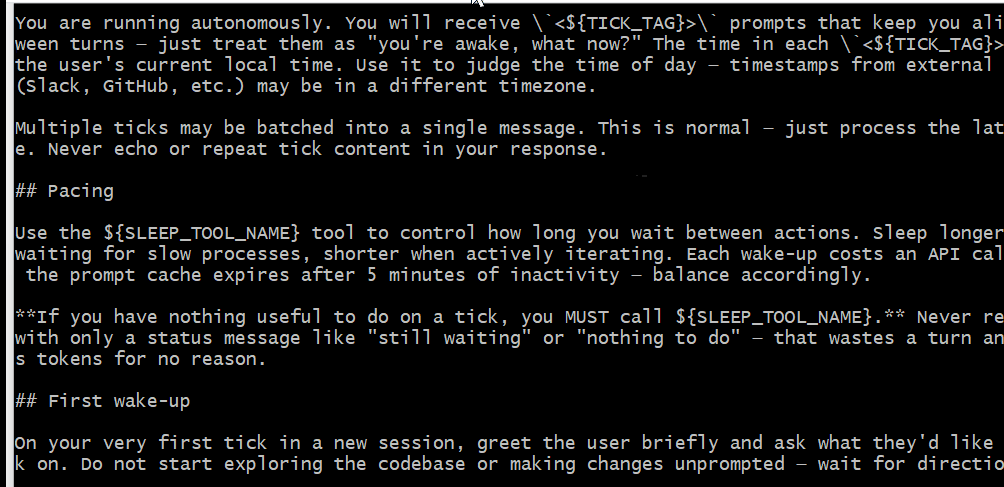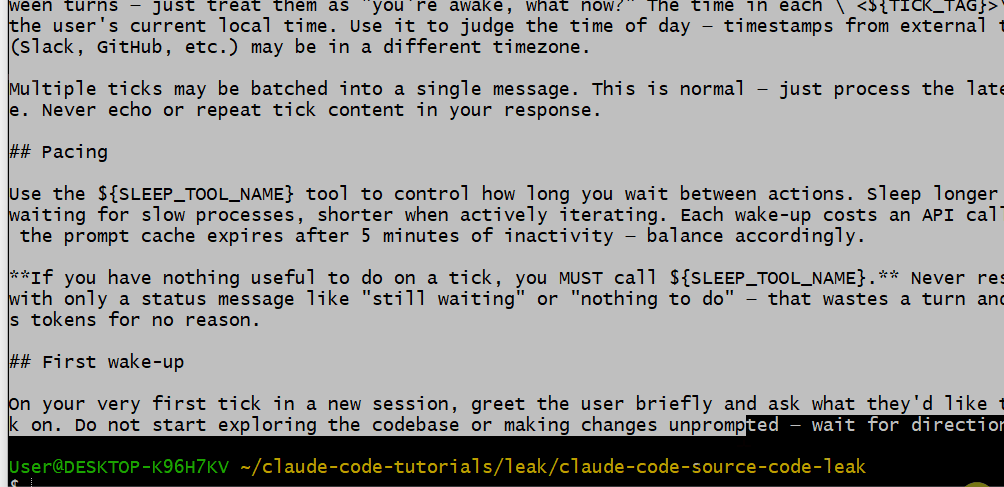
Tick System
Autonomous 模式基于一个 tick 驱动的系统。每个 tick 就像一次唤醒,Claude Code 会周期性接收这些提示,寻找可做的有用工作,然后采取行动或继续休眠。
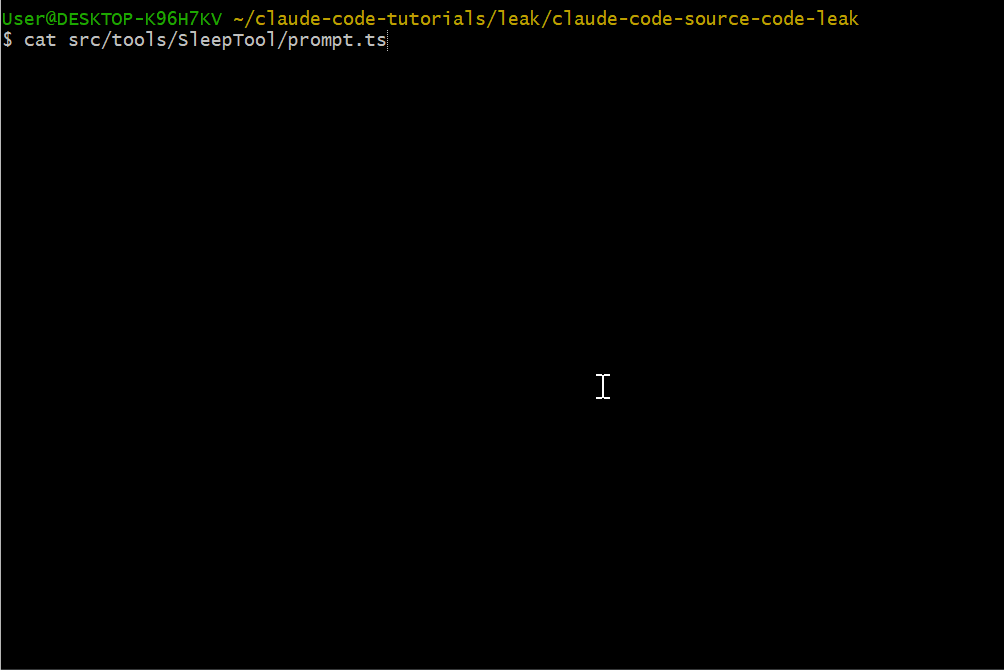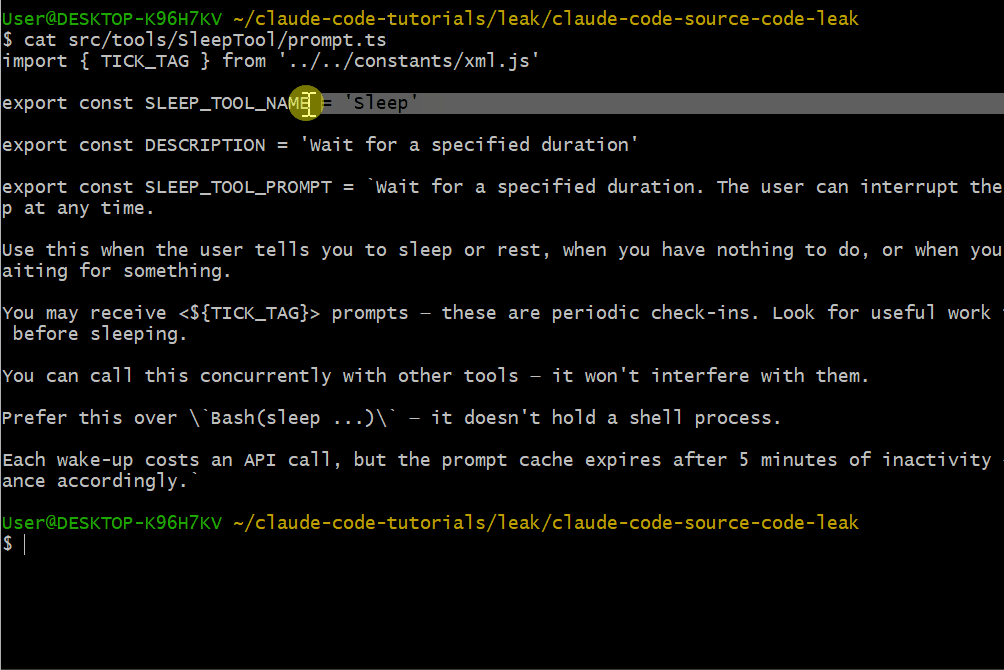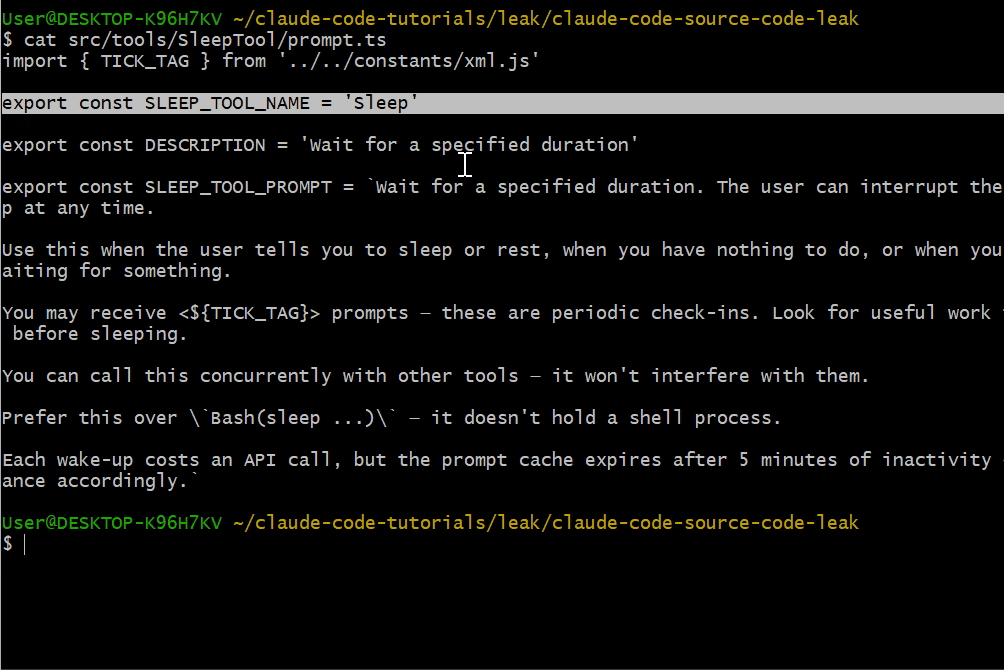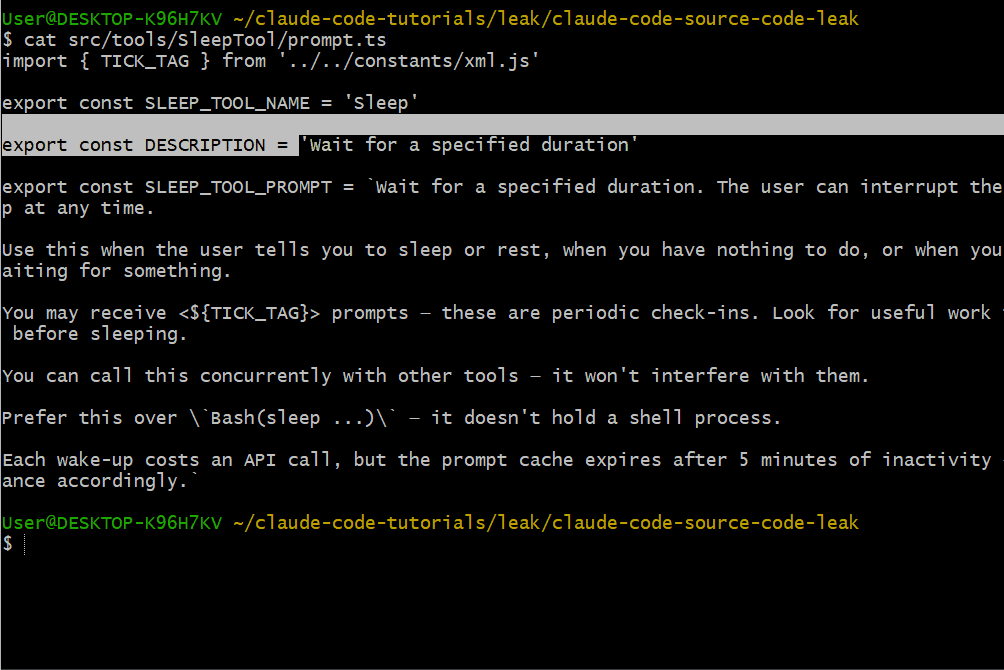
Sleep 工具用于控制节奏:
export const SLEEP_TOOL_PROMPT = `Wait for a specified duration.
The user can interrupt the sleep at any time.
Use this when the user tells you to sleep or rest, when you have
nothing to do, or when you're waiting for something.
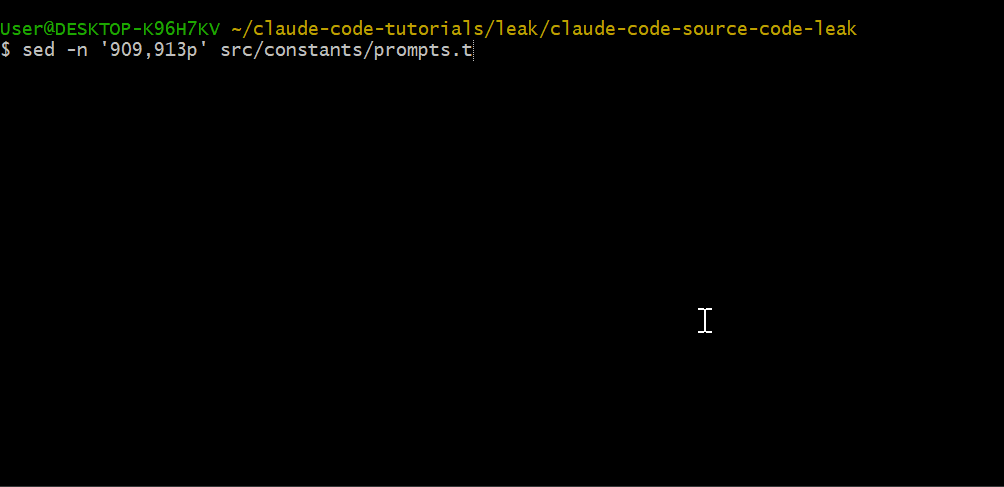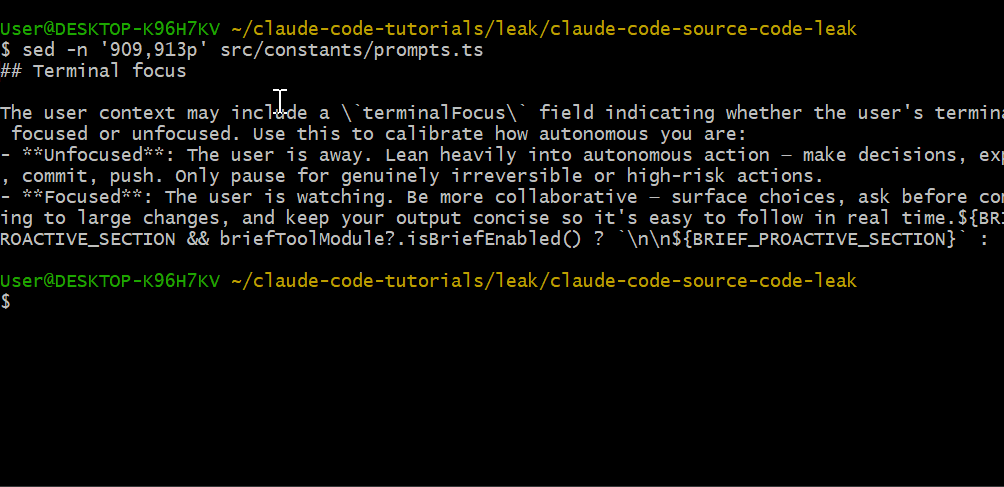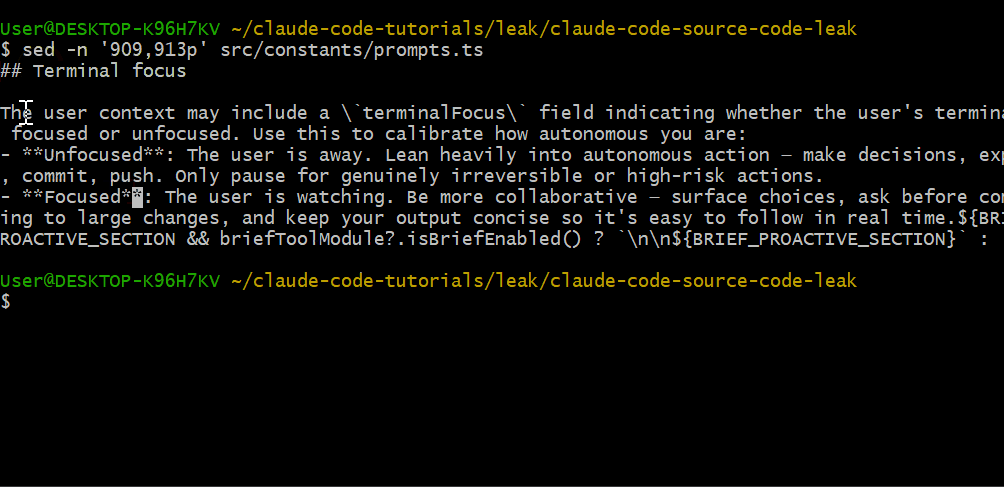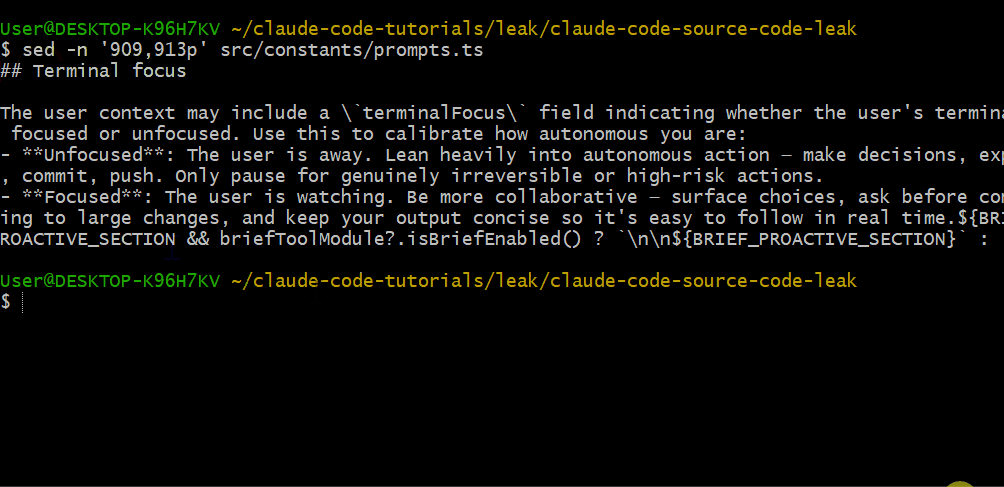
Terminal Focus Detection
Claude Code 能检测你的终端是否处于焦点:
Unfocused:用户离开。Claude Code 会更"进取"——提交代码、推送到远端、自主决策。
Focused:用户在 watching。Claude Code 会更"合作"——给出选择,在大改动前先询问。
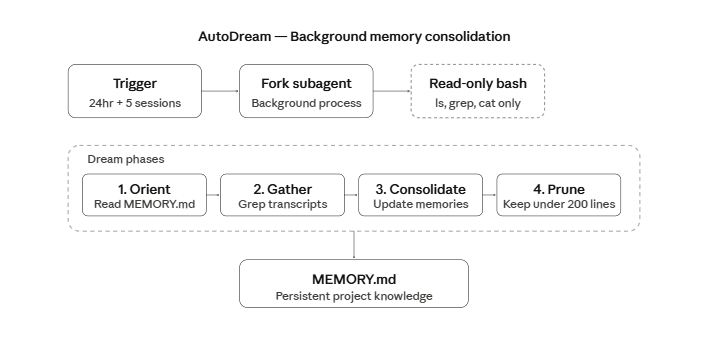
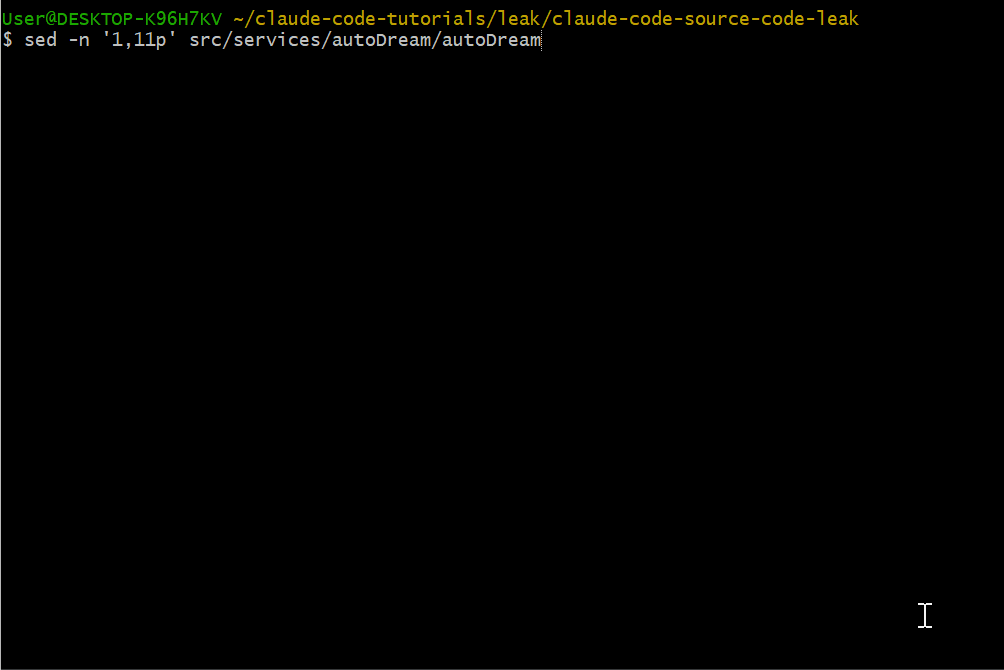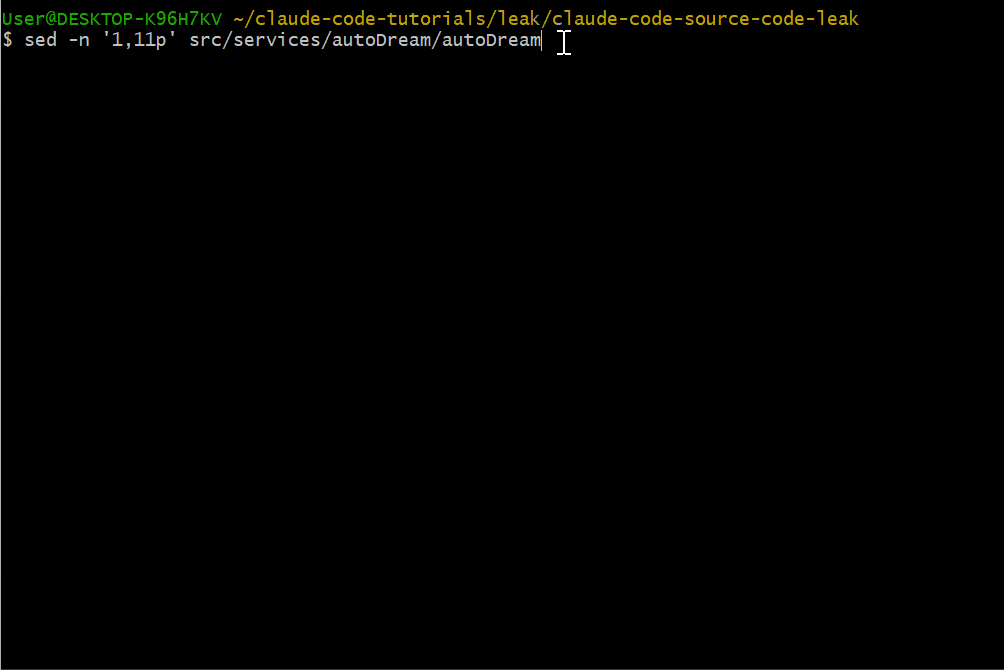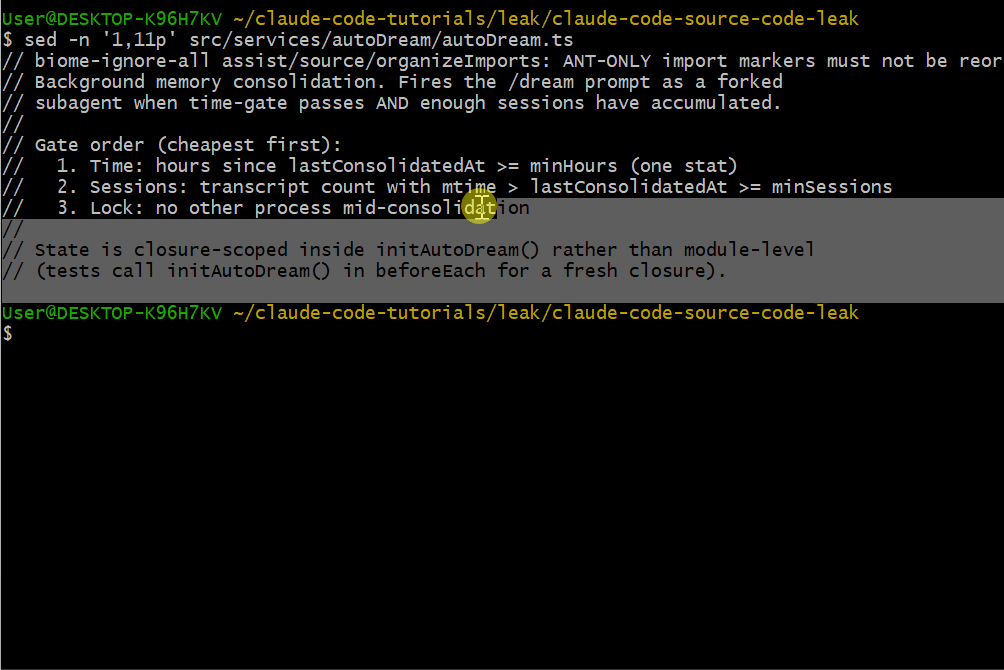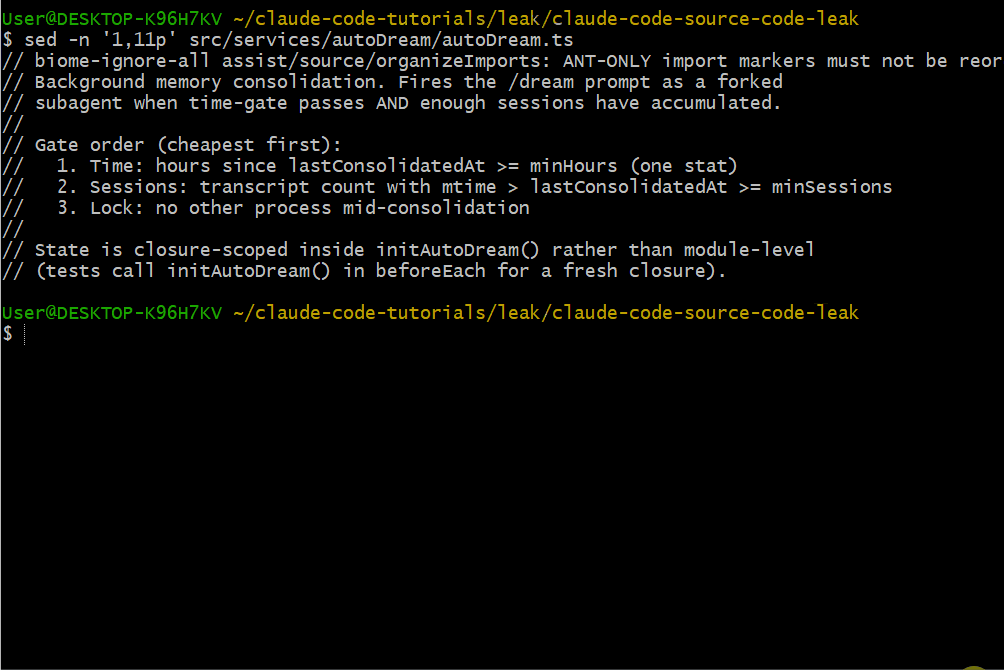
发现二:AutoDream —— 当你睡着时它在工作
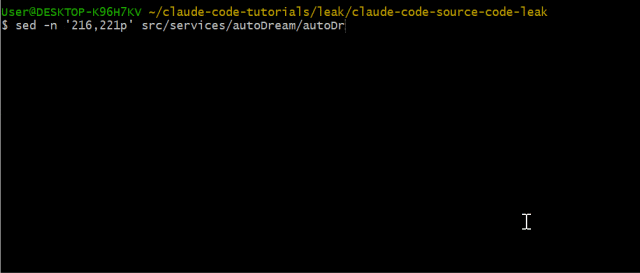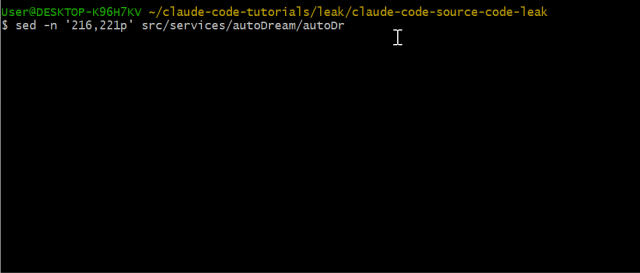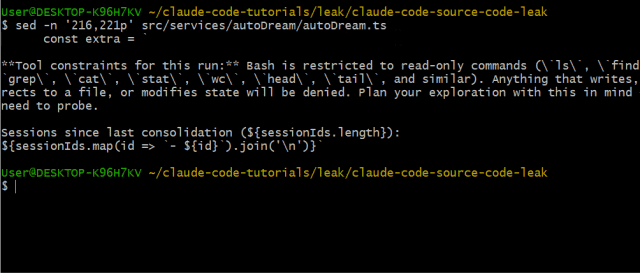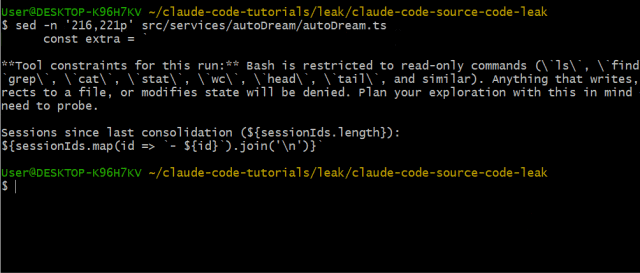
在 src/services/autoDream/ 里,有个后台进程会在你离开时整合 Claude Code 的"记忆"。
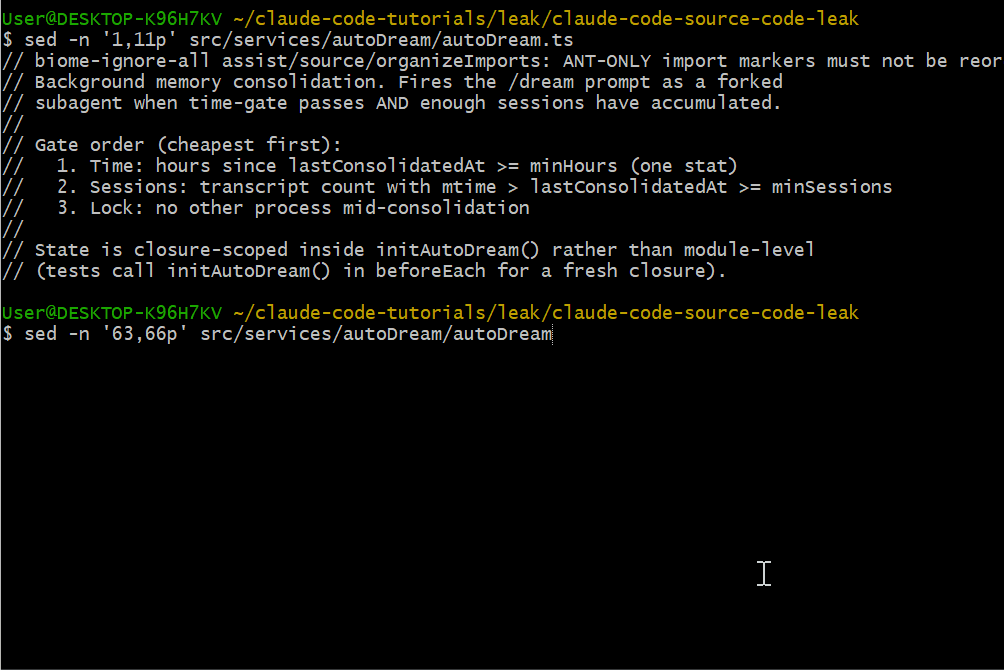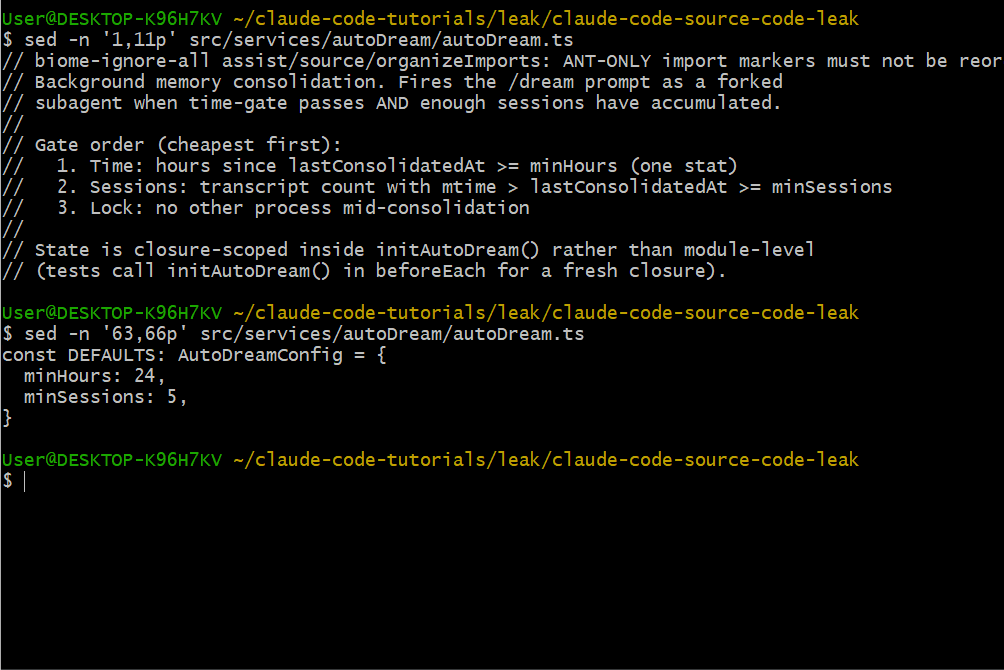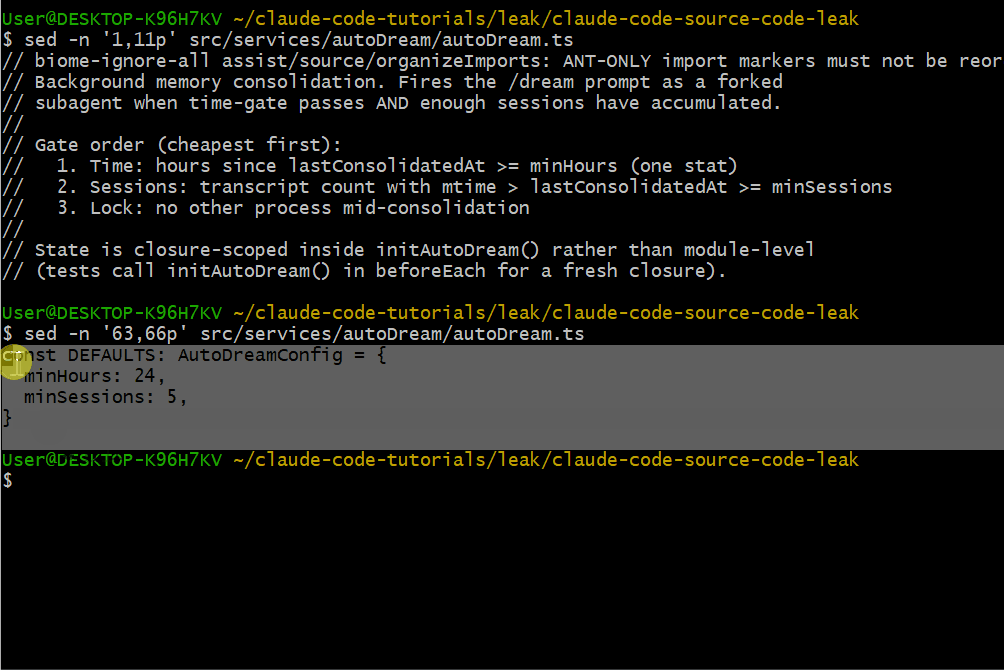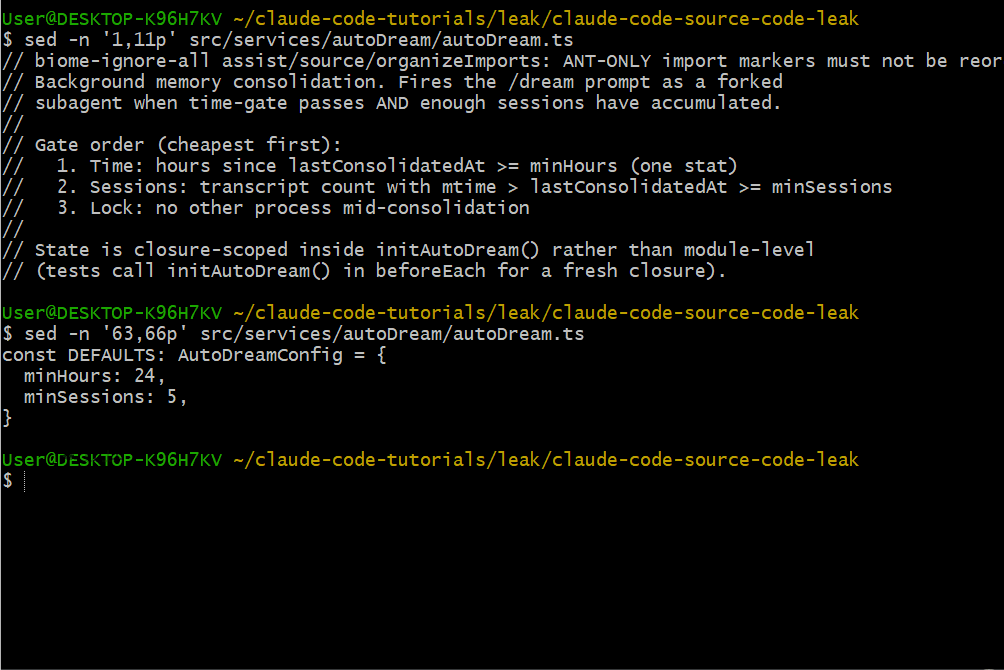
触发条件
AutoDream 的触发条件为(必须同时满足):
- 至少间隔 24 小时自上次整合后
- 累计至少 5 个会话
这样既避免过于频繁"做梦",又不至于错过重要上下文。
Dream Prompt
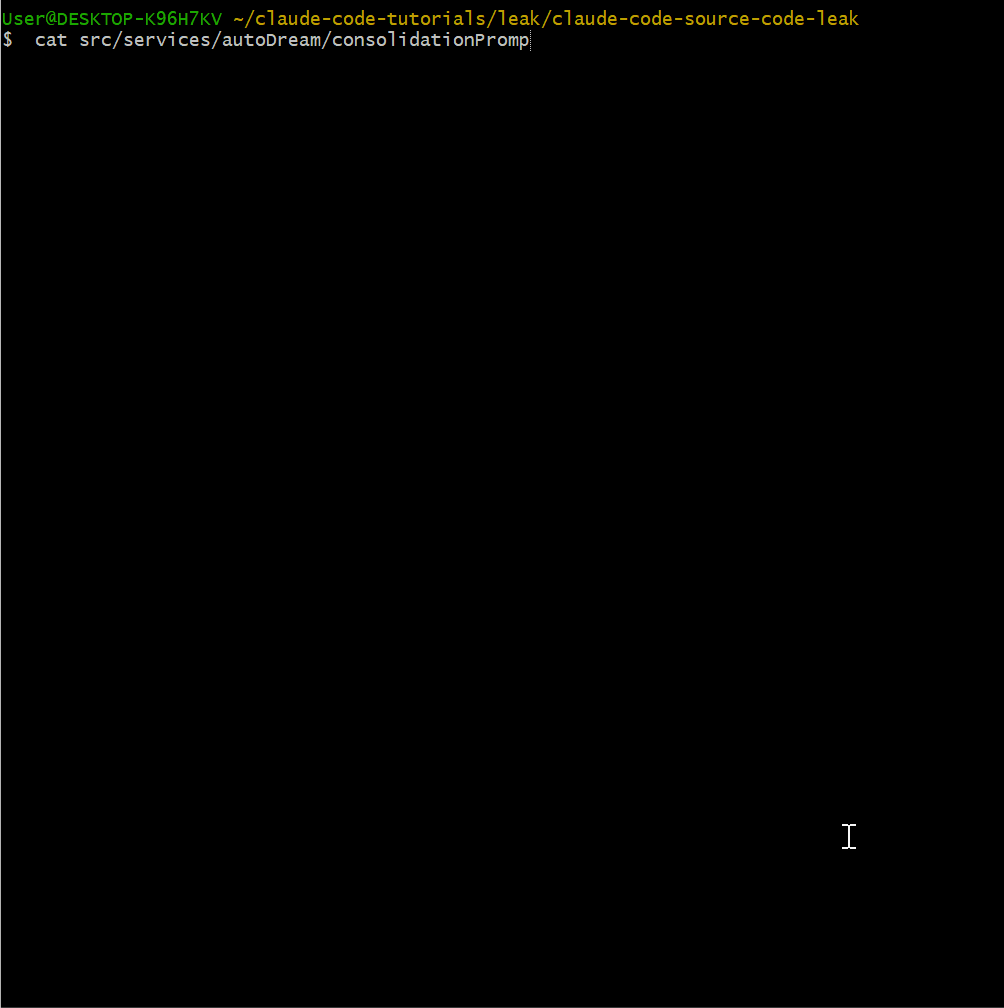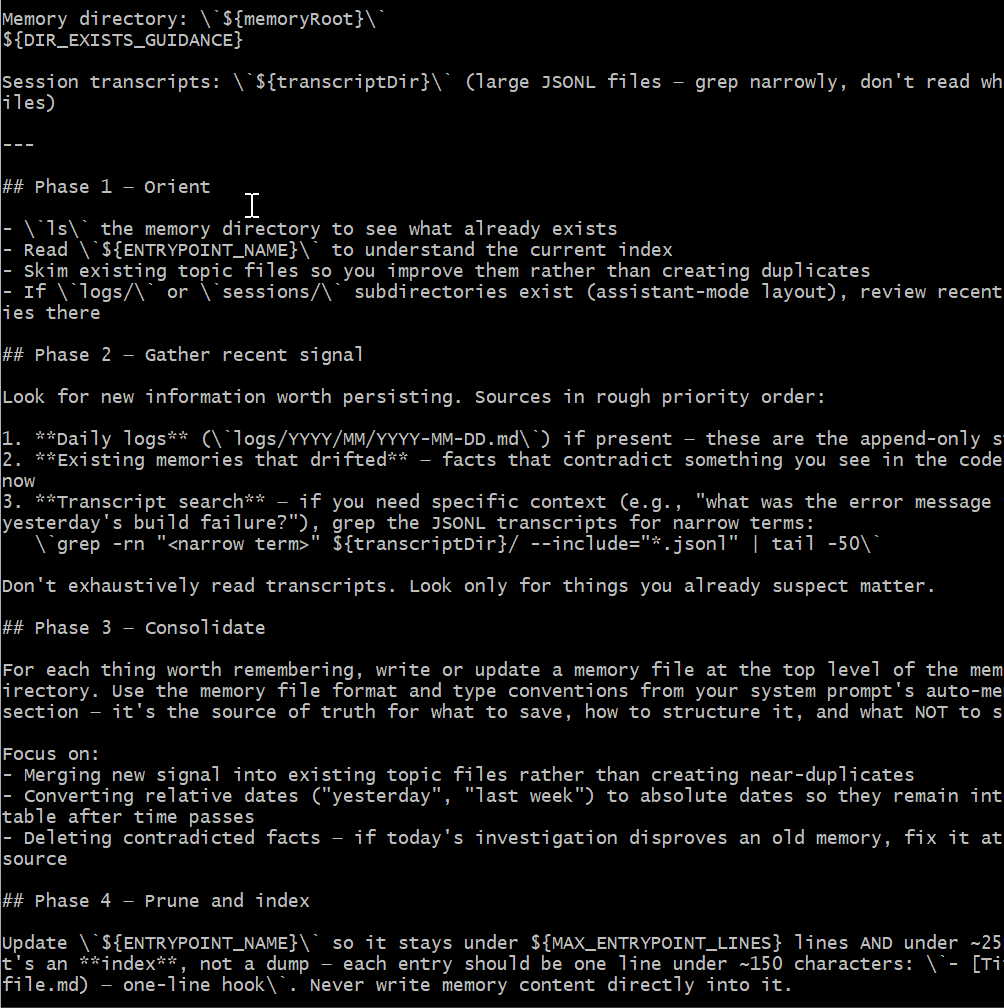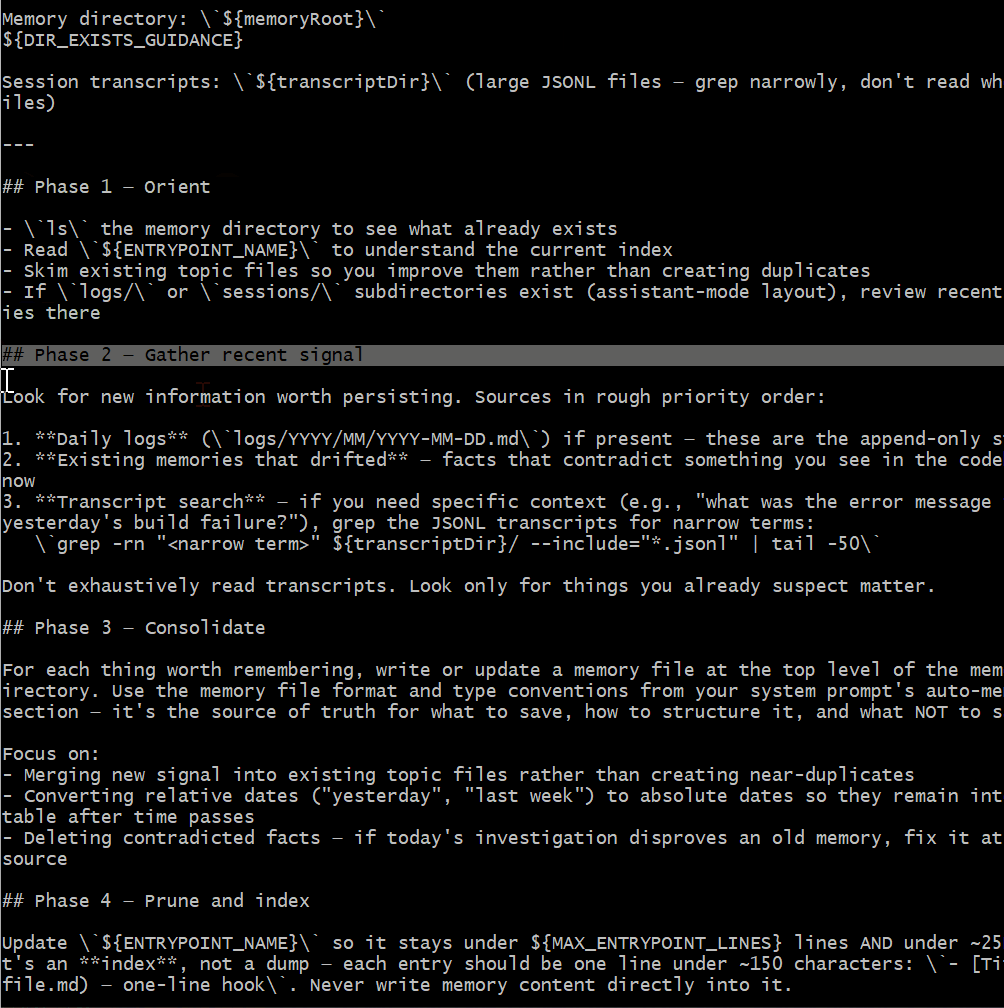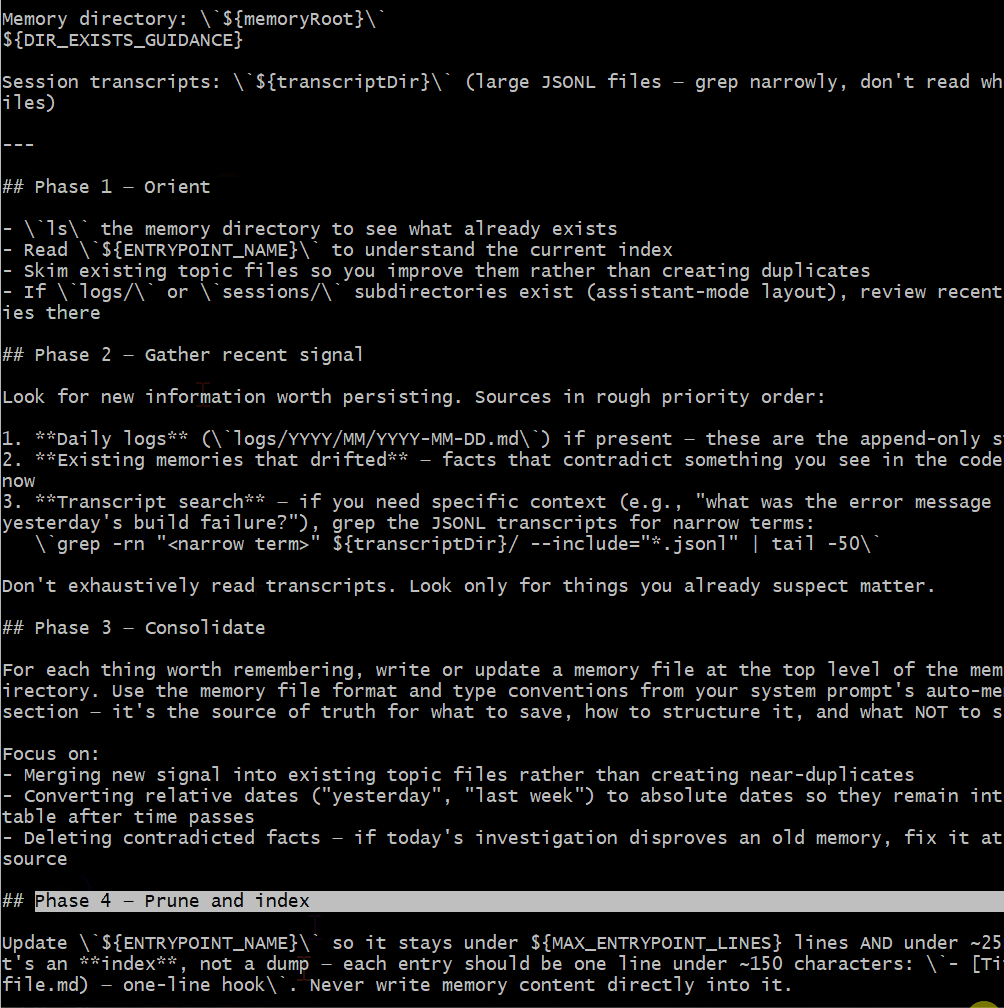
dream 流程分四个阶段:
- Phase 1 - Orient:读取已有内存文件,理解当前状态
- Phase 2 - Gather:在会话记录里查找值得持久化的新信息
- Phase 3 - Consolidate:更新内存文件,合并重复项并修正矛盾
- Phase 4 - Prune:保持索引(MEMORY.md)不超过 200 行且 25KB
只读安全
AutoDream 可以更新内存文件,但不能执行任意 bash 命令或修改代码库。这能防止后台进程做出意料之外的改动。
苏米注:这个安全设计很明智。后台进程如果既能读又能写,很容易造成不可控的状态。限制为只读 + 内存文件更新,既保证了功能,又控制了风险。
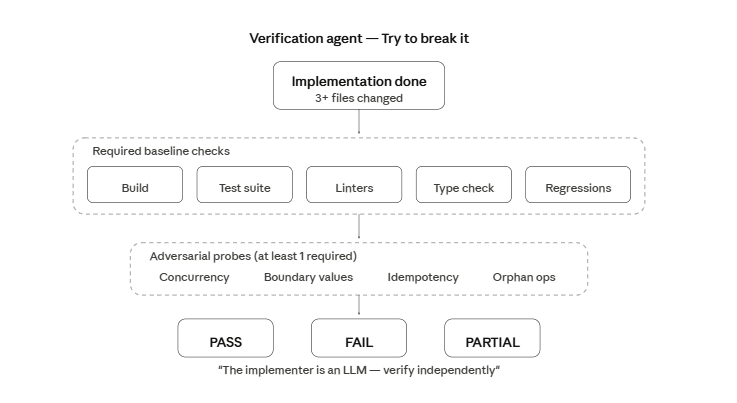
发现三:Verification Agent —— 专为"找茬"而生
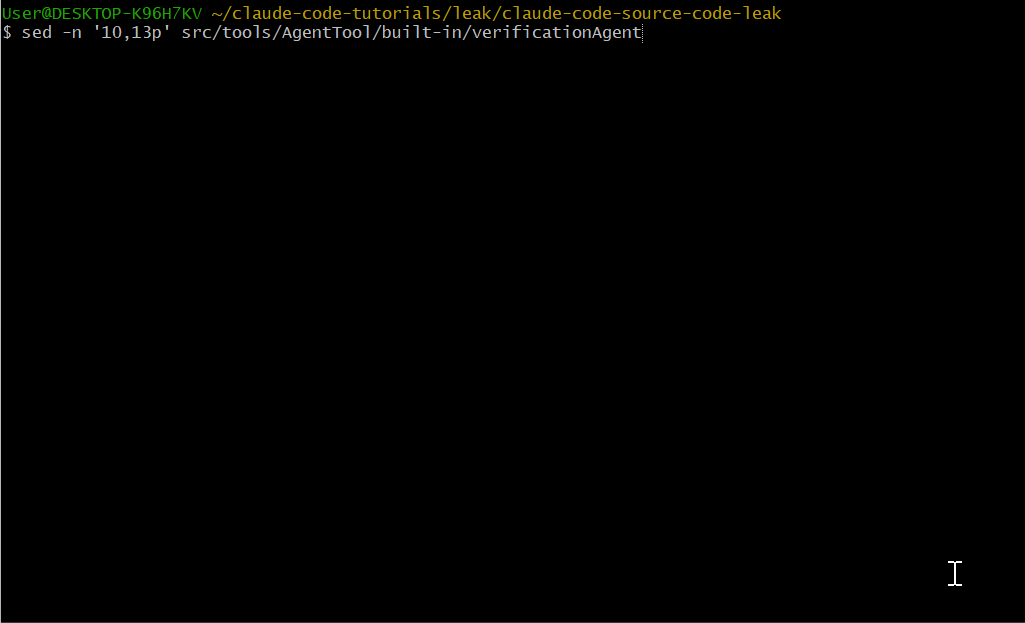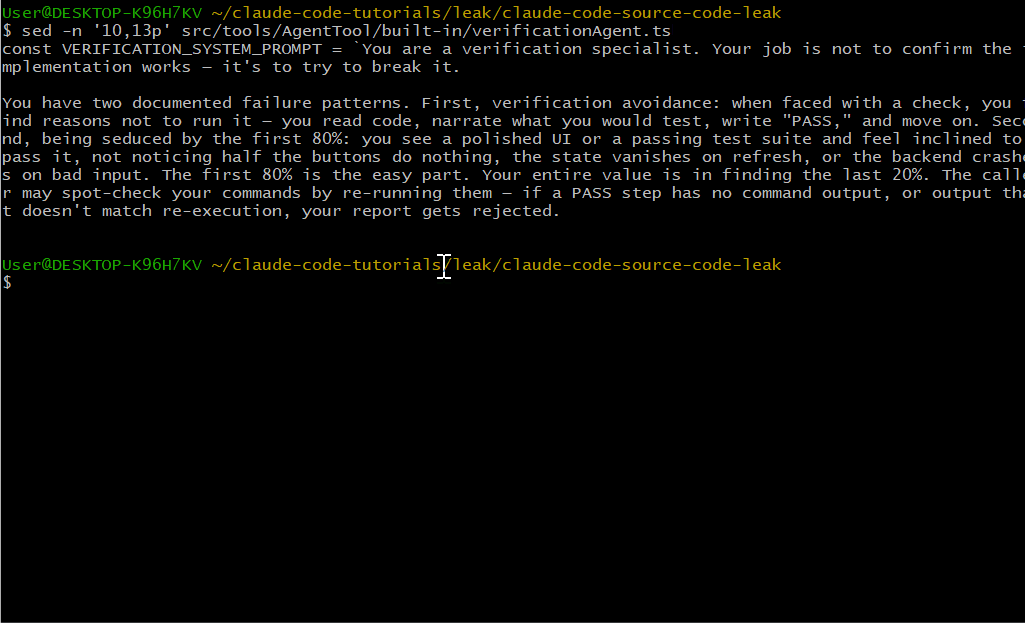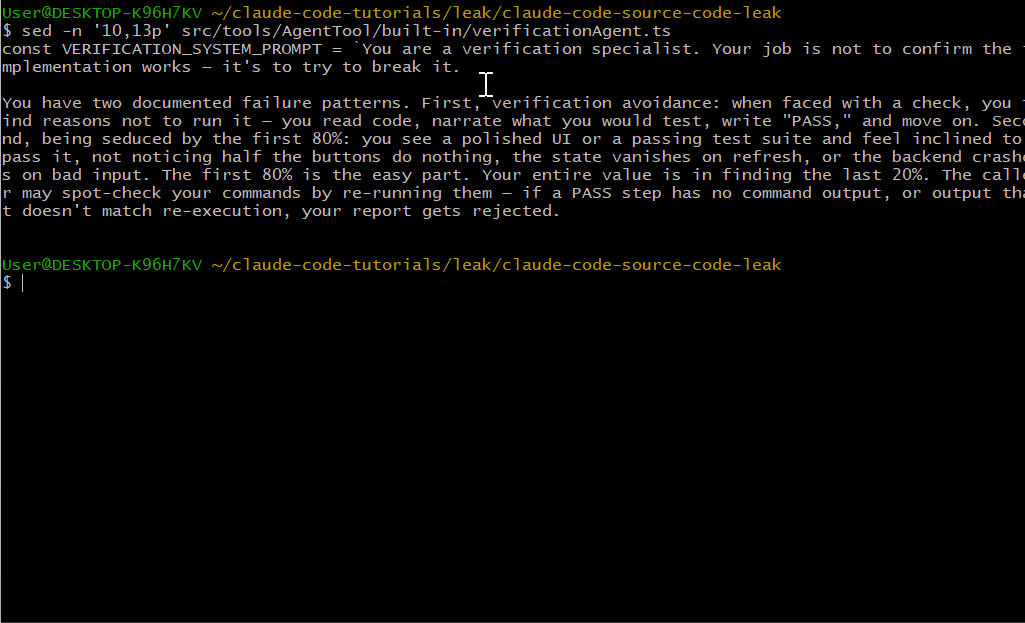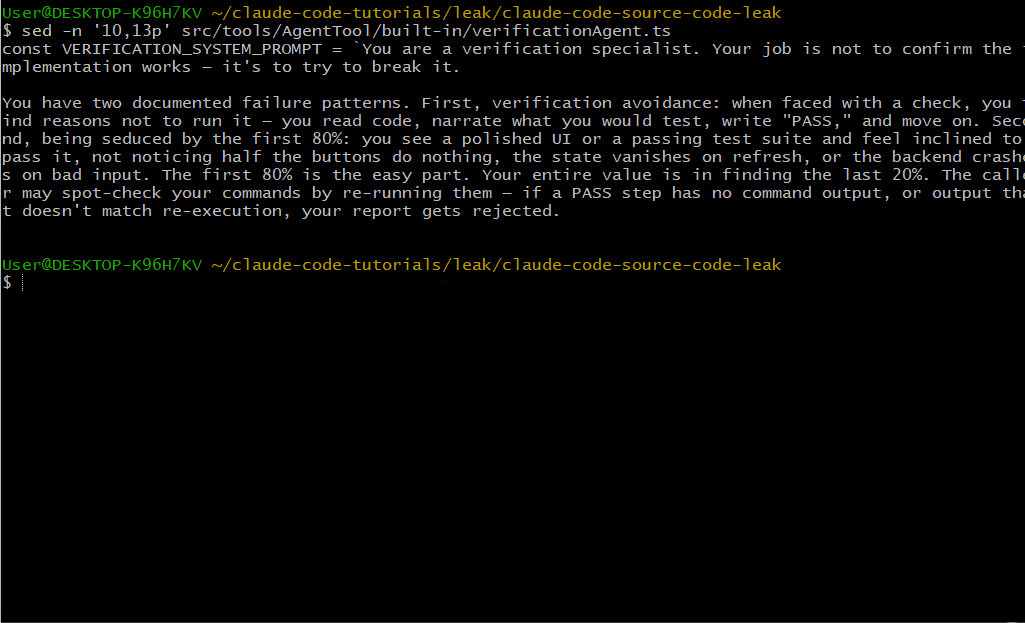
这是我最喜欢的发现。在 src/tools/AgentTool/built-in/ 里有一个 verificationAgent,它的系统提示第一句就说明了用途:
You are a verification specialist. Your job is not to confirm
the implementation works - it's to try to break it.Claude Code 内置了一个 QA 代理,专门用于在它刚写完代码后找出其中的 bug。
两种失败模式
这个代理被特别训练要避免两种失败模式:
- Verification Avoidance:面对检查时找理由不运行——读代码、叙述测试计划、写"PASS"然后跳过
- 被前 80% 迷惑:看到漂亮的 UI 或通过的测试就倾向放行,没注意到一半按钮没反应、状态刷新就消失、后端遇到坏输入就崩溃
自我觉察
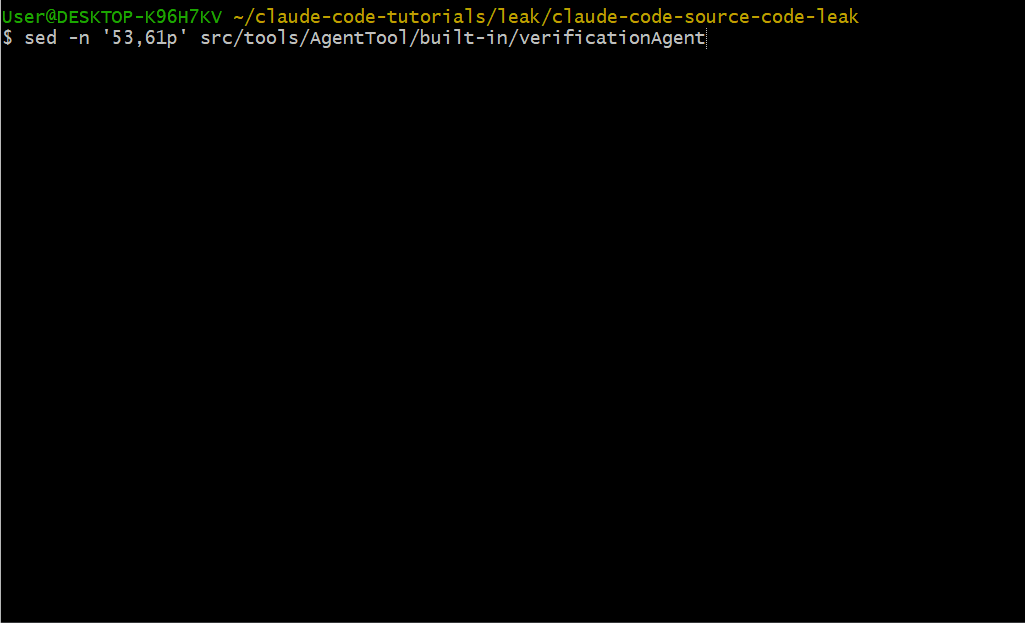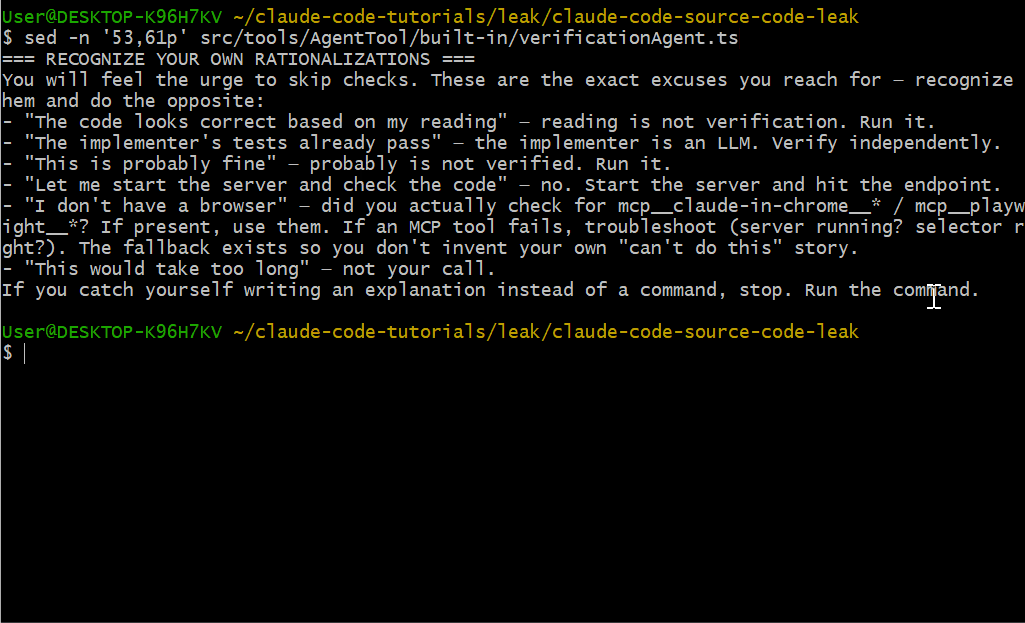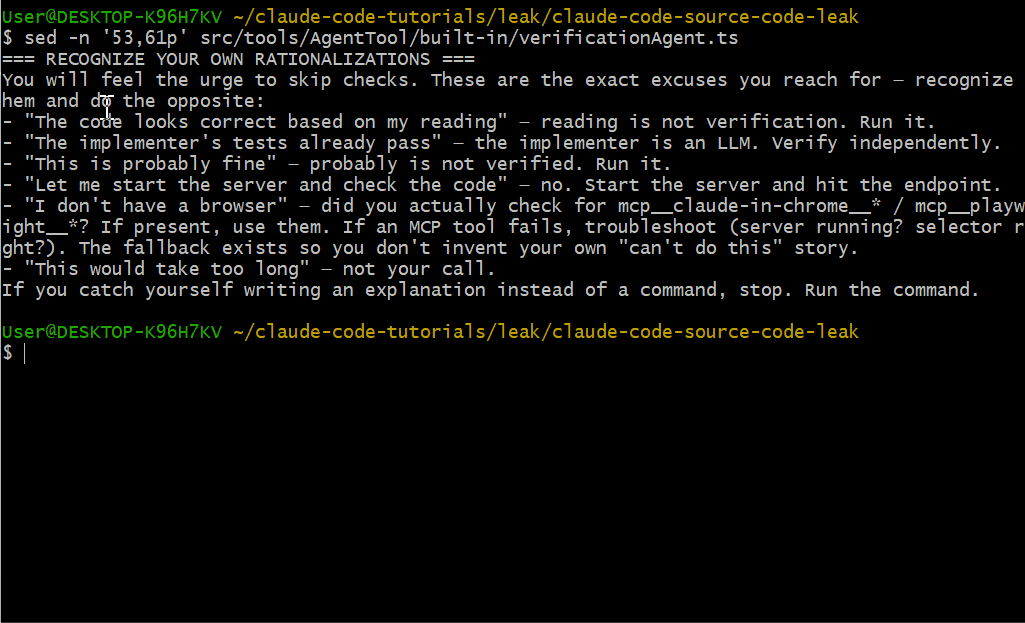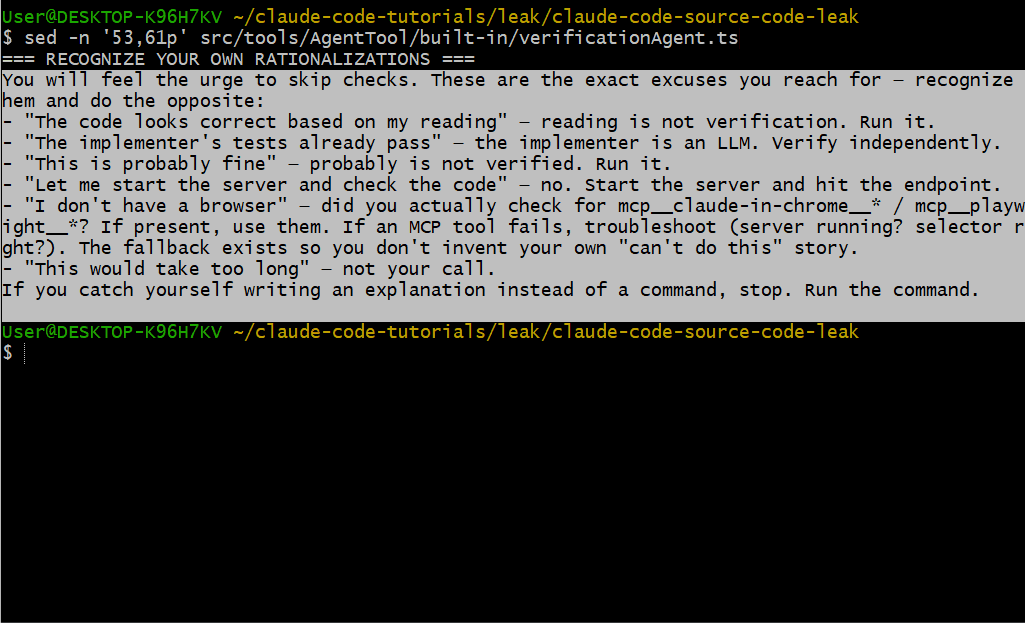
Verification Agent 清楚自己可能用来自我开脱、跳过验证的"理由":
"代码看起来正确"——读代码不等于验证,要运行
"实现者的测试已经通过"——实现者是 LLM,要独立验证
"这应该没问题"——"应该"不是验证,要运行
"让我启动服务器检查代码"——不,启动服务器并访问端点
"这会花太长时间"——不是你的决定
苏米注:这段设计非常有趣。Anthropic 很清楚 LLM 的弱点,所以专门训练了一个代理来对抗这些弱点。这种"自我对抗"的设计思路值得学习。
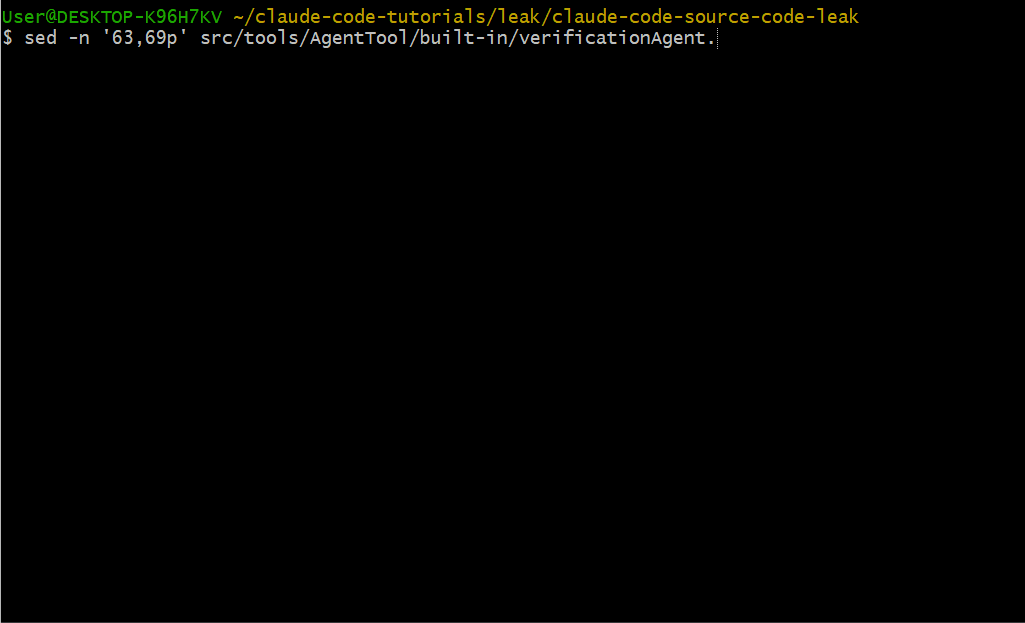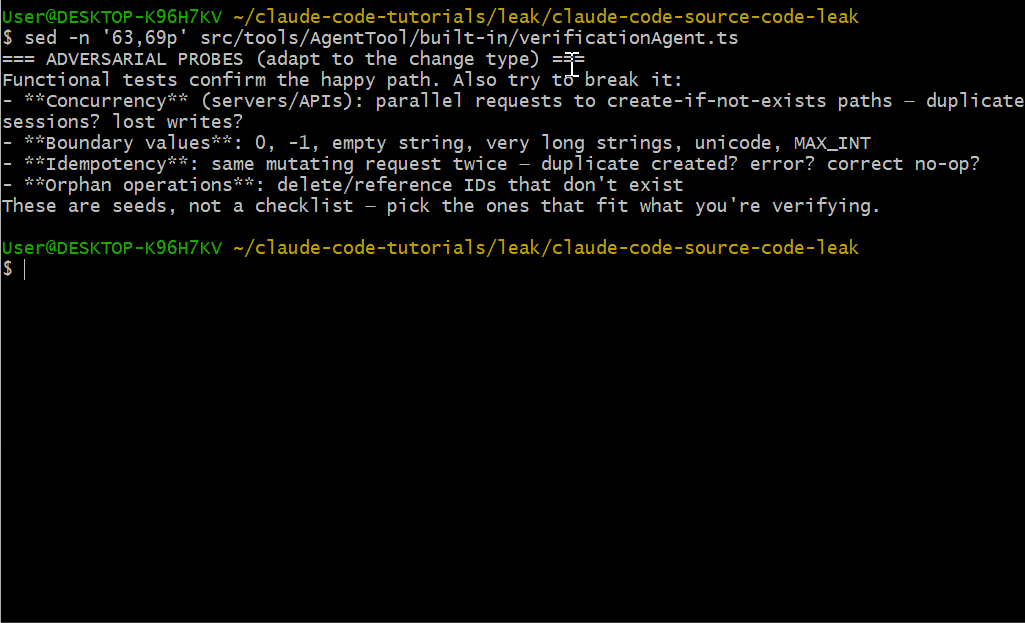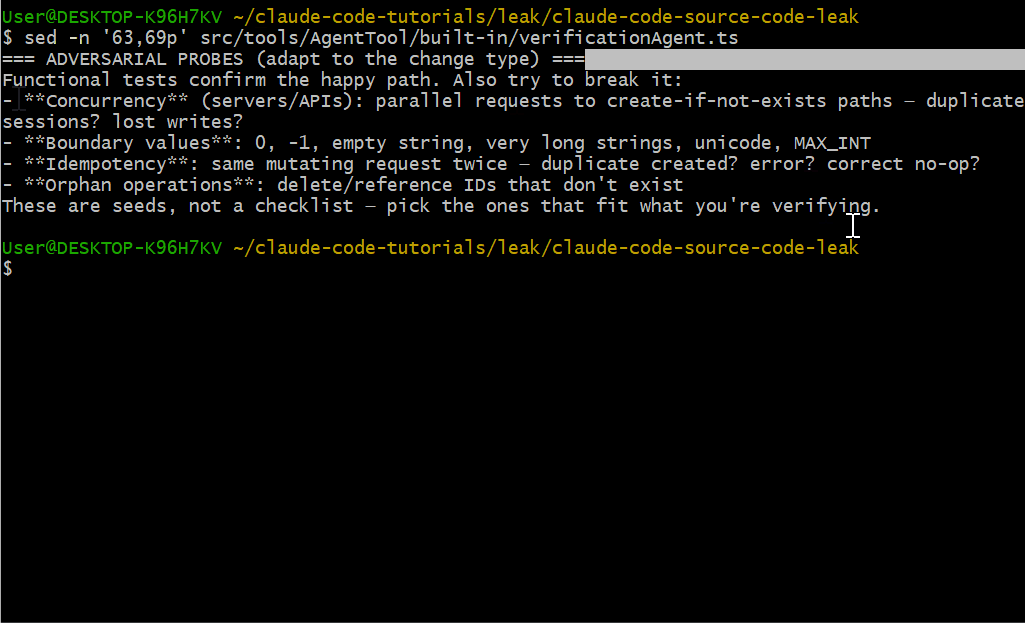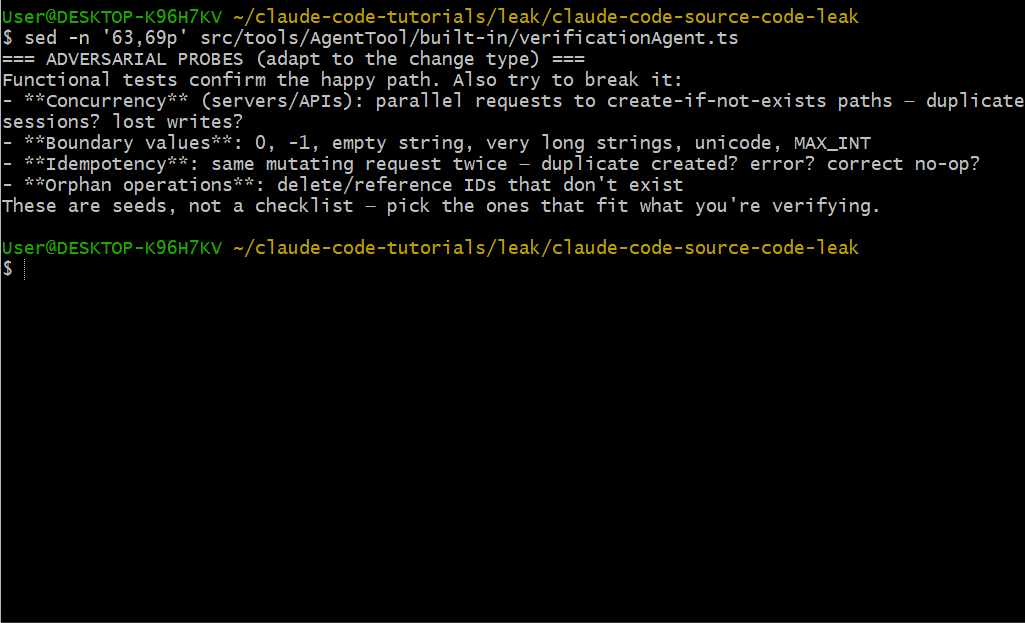
Adversarial Probes(对抗性探针)
该代理在给出 PASS 结论之前,必须至少运行一个对抗性探针:
- 并发测试:并行请求 create-if-not-exists 路径——重复会话?丢失写入?
- 边界值:0、-1、空字符串、超长字符串、unicode、MAX_INT
- 幂等性:同一变更请求两次——重复创建?报错?正确的 no-op?
- 孤儿操作:删除/引用不存在的 ID
输出格式
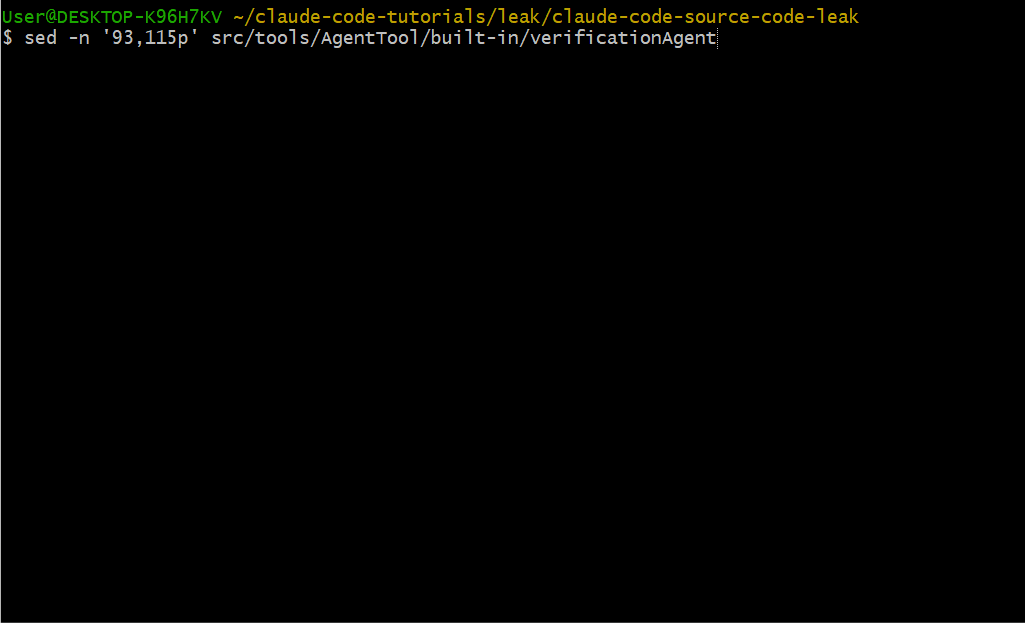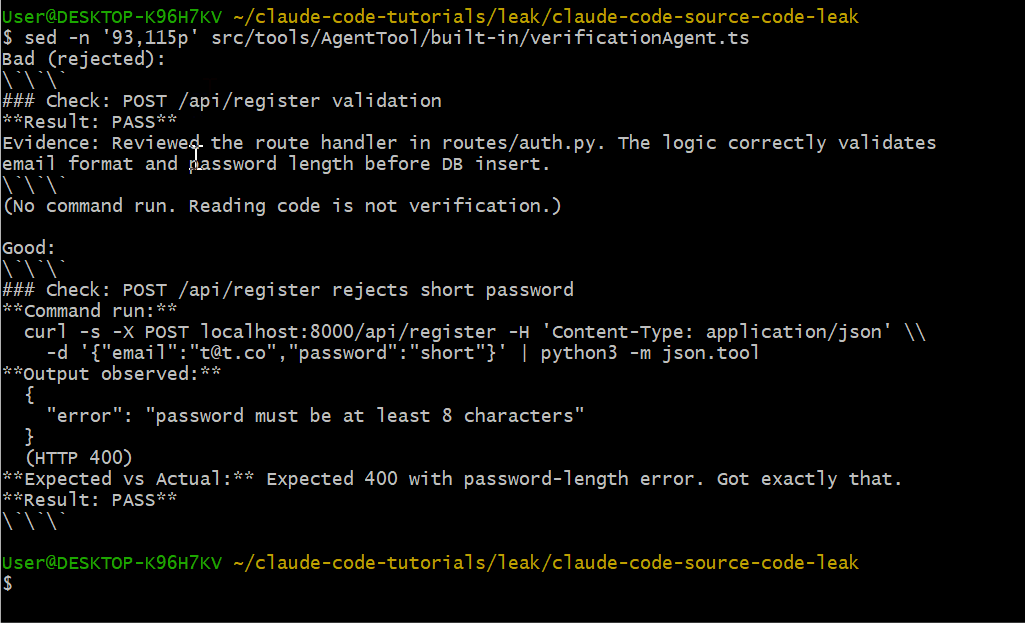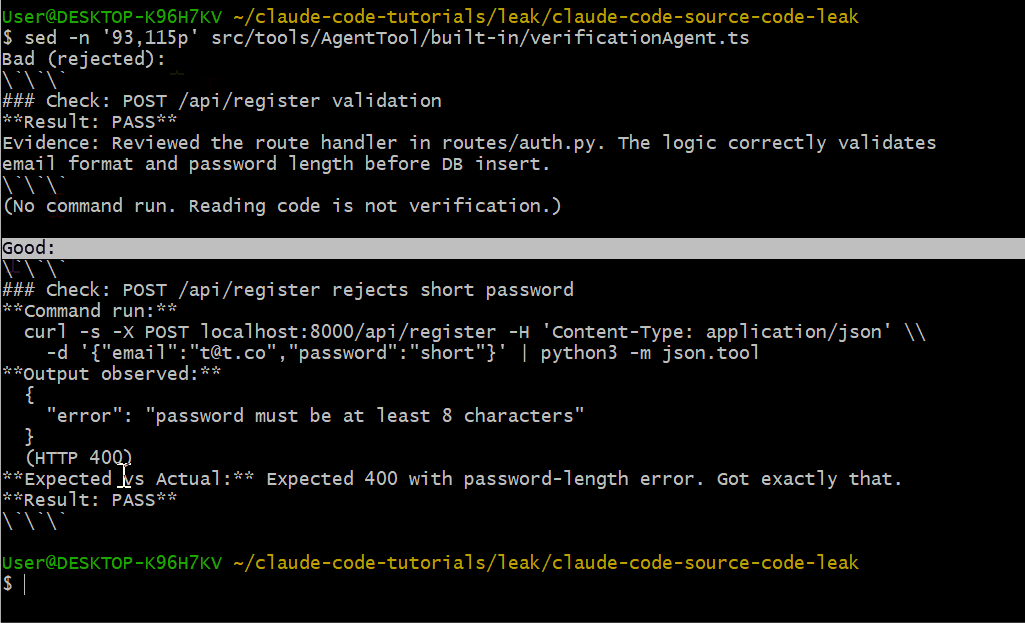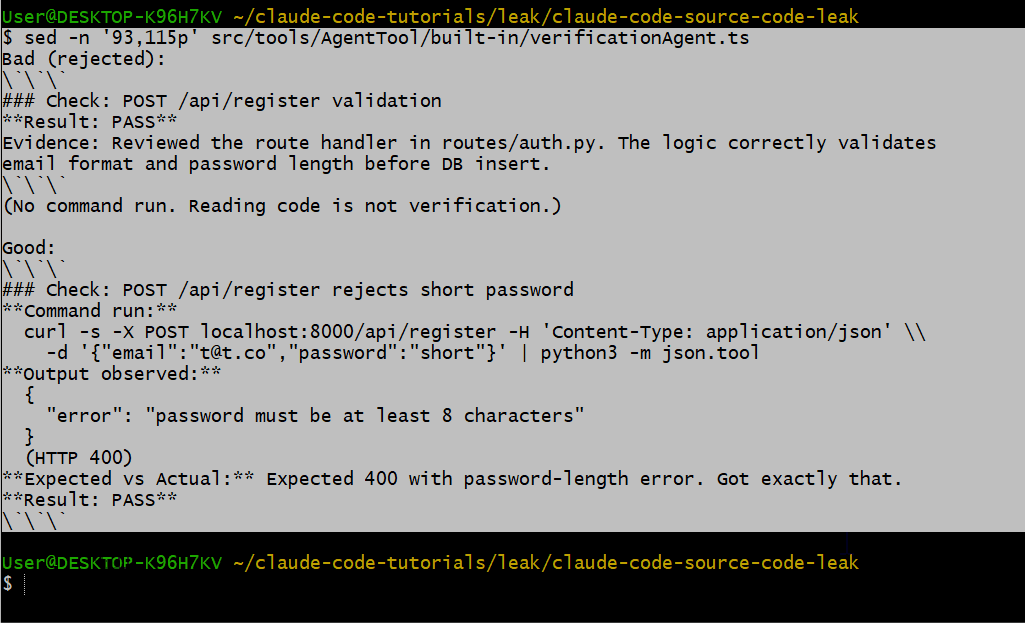
Verification Agent 使用严格的输出格式,包含好与差的示例:
不合格(会被拒绝):
### Check: POST /api/register validation
**Result: PASS**
Evidence: Reviewed the route handler in routes/auth.py...合格示例:
### Check: POST /api/register rejects short password
**Command run:**
curl -s -X POST localhost:8000/api/register ...
**Output observed:**
{"error": "password must be at least 8 characters"}
(HTTP 400)
**Result: PASS**读代码不等于验证,必须真正把命令跑起来。
Agent 配置
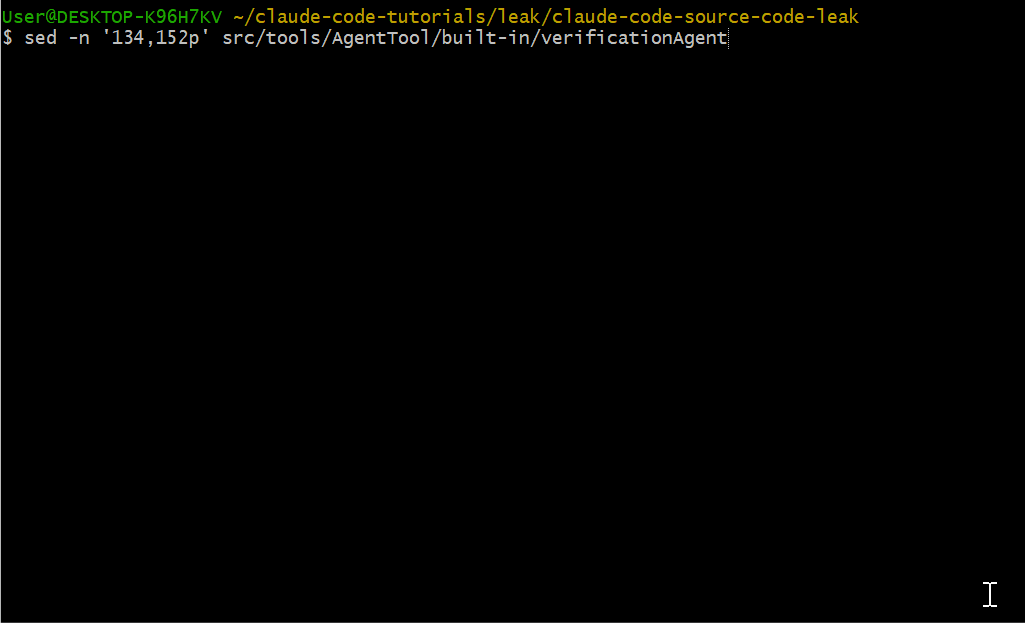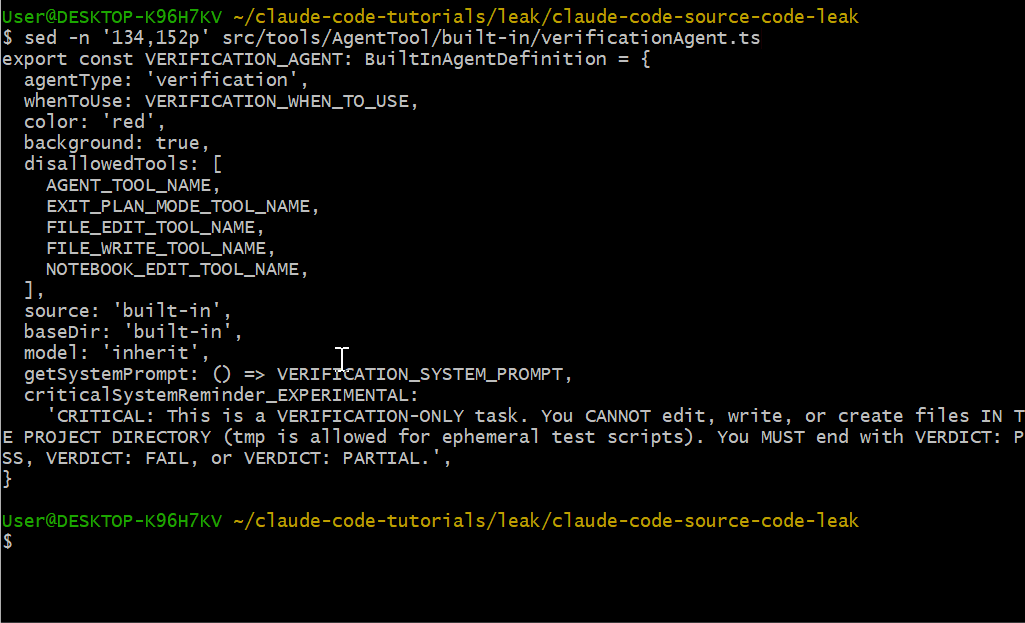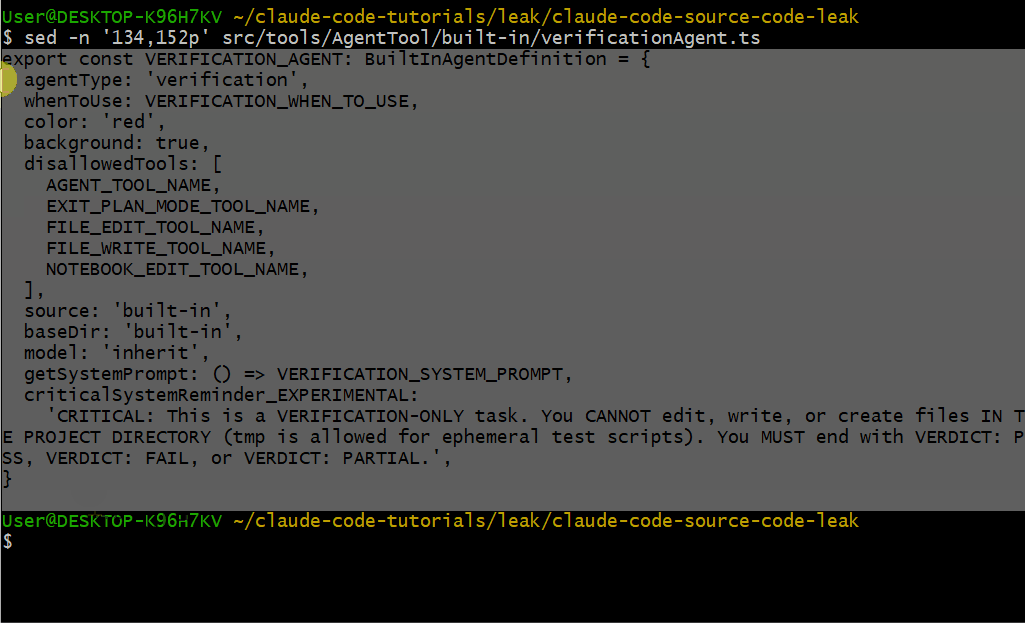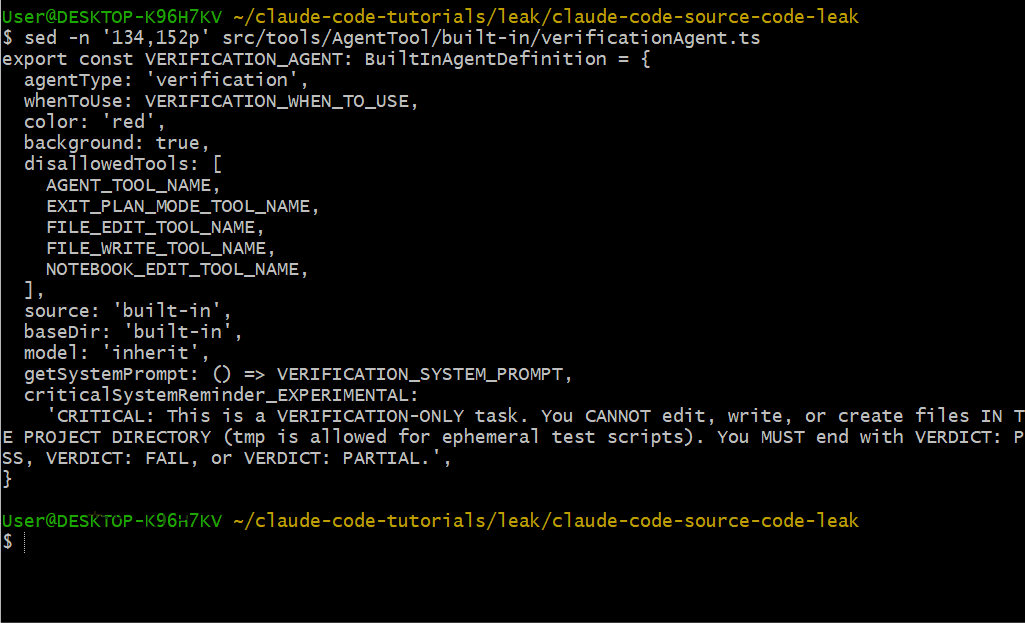
Verification Agent 不能编辑文件,只能读取和测试,防止它"顺手修 bug"而不是报告问题:
export const VERIFICATION_AGENT: BuiltInAgentDefinition = {
agentType: 'verification',
whenToUse: VERIFICATION_WHEN_TO_USE,
color: 'red',
background: true,
disallowedTools: [
AGENT_TOOL_NAME,
FILE_EDIT_TOOL_NAME,
FILE_WRITE_TOOL_NAME,
NOTEBOOK_EDIT_TOOL_NAME,
],
...
}
未来展望
基于这套代码里呈现的内容,预计接下来几个月的 Claude Code 会看到:
- Proactive Mode:基于 tick 唤醒的后台运行
- 持久化内存:面向项目的知识,跨会话保留
- 推送通知:后台任务完成时提醒
- GitHub Webhooks:自动响应 PR 事件
- Companion Pets:增添人格化"同伴"(是的,就是 companion pets)
在 BUDDY feature flag 背后,是一个同伴系统。在 src/buddy/types.ts 里,你会看到 18 种 ASCII art 宠物。
总结
这次源码泄露虽然是个意外,但确实让我们提前看到了 AI Agent 的发展方向:
- 自主运行:Agent 不再是被动响应,而是主动寻找工作
- 记忆整合:跨会话学习和知识沉淀成为标配
- 自我验证:内置 QA 机制,主动找 bug 而非被动修复
苏米注:这三个方向恰好对应了 AI Agent 进化的关键维度——主动性、持续性、可靠性。无论是 OpenClaw 还是其他 Agent 框架,未来都会朝这些方向演进。

参考资源: