智谱 GLM-5V-Turbo 发布:原生多模态 Coding 基座模型
2026 年 4 月 2 日,智谱发布 GLM-5V-Turbo,定位为「面向视觉编程的多模态 Coding 基座模型」。这款模型在 GLM-5-Turbo 的编程和 Agentic 能力基础上,加入了原生的视觉理解和推理能力。
核心能力一句话概括:模型能看懂设计稿、截图、网页界面,据此生成完整可运行的代码。

产品线的演进:从 GLM-5 到 GLM-5V-Turbo
回顾智谱的产品迭代路线:
- 2 月 11 日:GLM-5 发布,744B 参数的开源旗舰,主打编程和 Agentic Engineering
- 3 月 16 日:GLM-5-Turbo 跟进,针对 OpenClaw/AutoClaw 场景优化,强化工具调用、指令遵循、长链路执行
- 4 月 2 日:GLM-5V-Turbo 发布,在 GLM-5-Turbo 全部能力基础上,从预训练阶段融入视觉能力
苏米注:这个迭代速度相当快,大约每 2-3 周一个版本。GLM-5V-Turbo 的关键在于「原生」二字——视觉能力是从预训练阶段就开始训练的,而不是在文本模型上简单接一个视觉编码器。
新增的核心能力包括:
- 原生理解图片、视频、设计稿、文档版面等多模态输入
- 支持画框、截图、读网页等多模态工具调用
- 上下文窗口扩展到 200K
- 与 Claude Code、OpenClaw/AutoClaw 深度适配
Benchmark 表现:多模态与纯文本能力对比
先看多模态相关的指标,对比对象是 Kimi K2.5 和 Claude Opus 4.6:
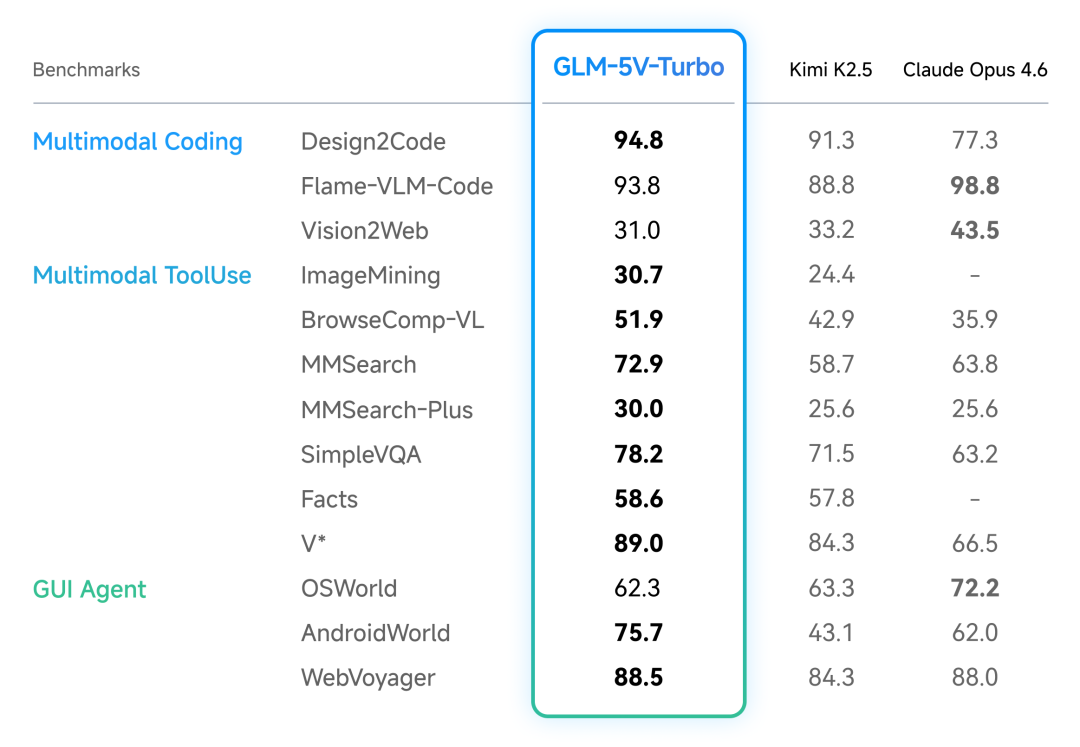
在 Design2Code、ImageMining、BrowseComp-VL、MMSearch、AndroidWorld 这几项上,GLM-5V-Turbo 均为三者最高。Opus 4.6 在 Flame-VLM-Code(98.8)和 Vision2Web(43.5)上保持领先。
再看纯文本 Coding 和 Agentic 任务的指标,这张表加入了 GLM-5-Turbo(纯文本版)用于对比,可以观察视觉能力引入后纯文本能力是否退化:
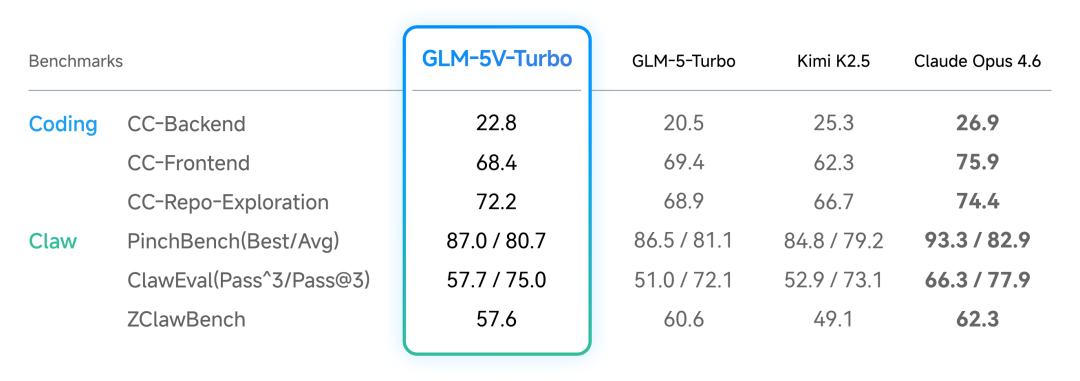
关键数据对比:
| 指标 | GLM-5V-Turbo | GLM-5-Turbo | Claude Opus 4.6 |
|---|---|---|---|
| CC-Backend | 22.8 | 20.5 | 26.9 |
| CC-Frontend | 68.4 | 69.4 | 75.9 |
| CC-Repo-Exploration | 72.2 | 68.9 | 74.4 |
苏米注:从数据看,视觉能力的引入并没有导致纯文本能力退化,个别项还有小幅提升。不过客观来说,Opus 4.6 在纯文本 Coding 三项上均领先,这个差距需要正视。
内测合作伙伴反馈
内测阶段,多家公司的模型测评团队给出了评价:
「GLM-5V-Turbo 实现了从设计稿到代码的完整还原,作为一款视觉理解模型,能够很好地满足开发者的前端开发场景」—— TRAE 模型测评团队
「原生多模态能力的引入并未削弱其编程逻辑,其编程能力仍属于国内第一梯队」—— 美团
「它为 Agent 安上了『眼睛』,同时在编程领域展现出优于同类多模态模型的能力,在视觉编程场景中更具竞争力」—— 快手万擎模型测评团队
四项技术升级
GLM-5V-Turbo 的能力来自模型架构、训练方法、数据构造、工具链四个层面的系统性改动。
1. 原生多模态融合
从预训练阶段开始做文本与视觉的深度融合。智谱研发了新一代 CogViT 视觉编码器,官方称在通用物体识别、细粒度理解、几何与空间感知上均达最优。同时设计了兼容多模态输入的 MTP(Multi-Token Prediction) 结构,在多模态场景下保持较高的推理效率。
2. 30+ 任务协同强化学习
强化学习阶段同时优化 30 多个 任务类型,覆盖 STEM、grounding、video、GUI Agent 等子领域。这种多任务协同的方式有效缓解了单领域训练的不稳定性,模型在感知、推理、Agentic 执行上均有提升。
3. Agentic 数据与任务构造
针对 Agent 数据稀缺、验证困难的痛点,智谱构建了从元素感知到序列级动作预测的多层级体系,用合成环境大规模生成可控、可验证的训练数据。
踩坑记录:一个有意思的细节是,他们从预训练阶段就注入 Agentic 元能力,比如把 GUI Agent PRM 数据加入预训练来降低幻觉。这个思路值得借鉴——把关键能力前置到预训练阶段,而不是依赖后训练修补。
4. 多模态工具链扩展
在文本工具之外,GLM-5V-Turbo 新增支持多模态搜索、画框、截图、读网页等多模态 tools。这让 Agent 的感知链路从纯文本扩展到视觉交互,形成「看懂环境 → 规划动作 → 执行任务」的完整闭环。
典型应用场景
图像即代码(Image-to-Code)
这是 GLM-5V-Turbo 最核心的能力场景。发送草图、设计稿、参考网站的截图或录屏,模型直接理解布局、配色、组件层级与交互逻辑,生成完整可运行的前端工程。




文档解读与写作
给模型一份 PDF 文档,它读完之后可以按照要求撰写特定格式的文章。
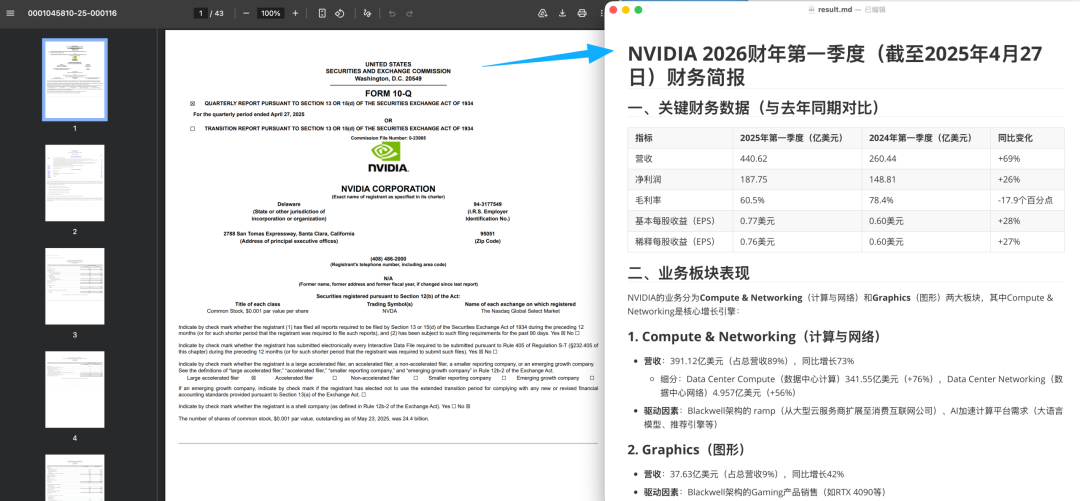
比如把 NVIDIA 2026 财年第一季度 10-Q 表格扔给 AutoClaw,提示词是「阅读文档,汇总关键数据,撰写一份简报,保存到 result.md」,模型输出了包含营收、利润、毛利率、EPS 等关键数据和业务板块分析的中文财务简报。
另一个案例是给一篇 40 页的 GLM-5 论文 PDF,让模型按微信公众号风格撰写宣传文案。模型自动从原文中定位和截取关键图表,嵌入到合适的位置,输出图文并茂的文章。
PDF-to-WEB / PDF-to-PPT
这两个能力做成了官方 Skill。PDF-to-WEB 是把论文或报告转成精美的单页学术网站,用 BERT 论文和 GLM-5 论文做的实测,渲染结果的完成度很高,接近手工做的学术项目主页。
PDF-to-PPT 则是把文档转成多页 HTML 演示文稿。比如用阿里巴巴的近期动态做了一个 14 页的分析 PPT,模型自主搜索了季度财报、业务板块数据和竞争格局,配了图表。

多模态 Deep Research
展示两个深度调研的案例:
第一个是「搜集小米汽车相关图片,输出图文交错的专题报告」。模型通过约 50 轮网络搜索,从各个渠道获取了包括新一代 SU7、YU7/YU7 GT、YU9 等车型的图片和产线、工厂照片,输出了一份结构化分析报告。

第二个是「结合阿里巴巴的近期动态和季度财报,仿照麦肯锡风格,生成专业 PPT」。模型同样自主完成了信息搜集、数据整理和可视化呈现。
视觉 Grounding
模型能在图片中精准定位目标物体。几个有意思的例子:
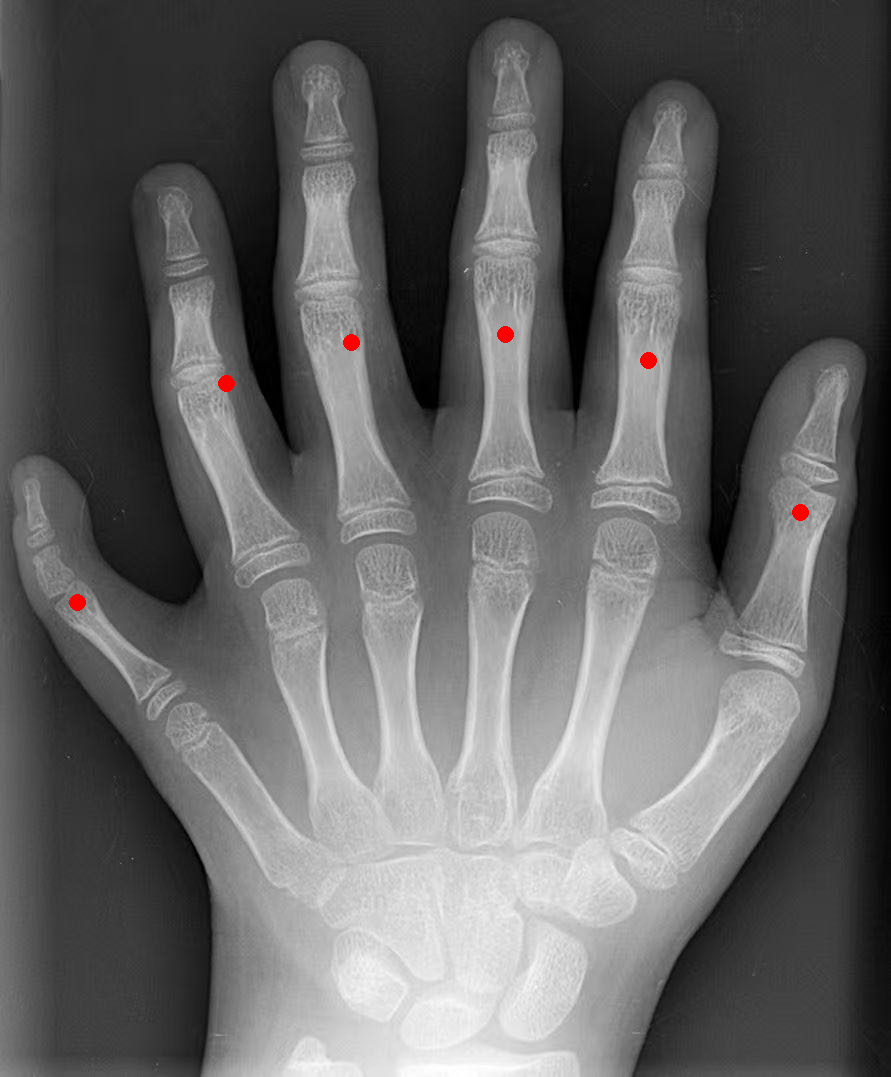
数手指:给一张手部 X 光片,让模型用坐标标出所有手指的位置。模型准确识别并标注了 6 个手指(包括左右两侧拇指和中间 4 个手指)。
多模态搜索 + 识别:给了一张 1927 年第五届索尔维会议的合影照片,提示词是「框出图中全部人物以及他们的名字」。模型成功识别并框出了全部 29 位人物,从第三排的奥古斯特·皮卡尔德到第一排的爱因斯坦。

空间推理
模型在空间理解上的能力可以和具身机器人结合。一个实测案例是一张厨房场景照片,提示词是「我想切火腿肠,请问我的手应该操作哪个位置?请在图中点出对应的位置」。模型标注出了菜刀刀柄的位置,并给出了操作指导。

为 AutoClaw/OpenClaw 装上眼睛
接入 GLM-5V-Turbo 之后,AutoClaw/OpenClaw 的任务边界大幅拓宽。以前只能处理纯文本任务,现在可以浏览网页和文档、生成图文并茂的报告和 PPT、查询并解读 K 线图。
官方已上线「股票分析师」Skill,利用视觉能力让 AutoClaw 直接看懂 K 线走势、估值区间图和券商研报图表,四路数据源 60 秒并行采集,输出图文交错的研报。
14 个官方 Skills
智谱为 GLM-5V-Turbo 准备了 14 个官方 Skills,分为三类:
基于主模型原生能力(4 个)
- PDF-to-WEB:论文/报告转单页学术网站
- PDF-to-PPT:文档转多页 HTML 演示文稿
- Web-Replication:给 URL,模型自主探索并复刻整个网站
- PRD-to-App:产品需求文档 + 原型图转全栈 Web 应用
作为外部工具调用(5 个)
- 图像 Captioning:自动分析图像内容,生成自然语言描述
- 视觉 Grounding:根据文字描述在图像中精准定位目标
- 基于文档的写作:读文档、提关键信息、生成特定格式文本
- 简历筛选:读简历,和职位要求智能比对
- 提示词生成:根据参考图/视频,自动构建文生图/视频的 Prompt
基于专用模型 GLM-OCR / GLM-Image(5 个)
- 通用文字识别:印刷体、手写体、多语言文本
- 表格识别:还原行列结构和合并单元格
- 手写体识别:适应连笔、潦草等复杂书写
- 公式识别:复杂公式转 LaTeX
- 文生图:自然语言生成图像
全部 Skills 已上线 ClawHub,可一键安装。GitHub 仓库:zai-org/GLM-skills
接入方式
产品体验
- AutoClaw(澳龙):autoglm.zhipuai.cn/autoclaw
- Z.ai:chat.z.ai
API 接入
- BigModel 开放平台:docs.bigmodel.cn
- Z.ai:docs.z.ai
Claude Code 配置
在 ~/.claude/settings.json 中配置:
- ANTHROPIC_BASE_URL 设为 https://open.bigmodel.cn/api/anthropic
- 模型 ID 填 glm-5v-turbo
或在会话中直接 /model glm-5v-turbo 切换。
AutoClaw / OpenClaw 接入
设置里添加自定义模型:
- 服务商选「智谱」
- 模型 ID 填 glm-5v-turbo
- Base URL 填 https://open.bigmodel.cn/api/paas/v4
- 填入 API Key 即可
Coding Plan 现面向 Coding Plan 用户开放申请,后续 GLM Coding Plan 也会纳入 GLM-5V-Turbo。
总结
从 GLM-5(2 月 11 日)到 GLM-5-Turbo(3 月 16 日)再到 GLM-5V-Turbo(4 月 2 日),智谱大约每两到三周发布一个版本。这次补上的是视觉能力,让 AutoClaw/OpenClaw 和 Claude Code 的感知链路从纯文本扩展到了视觉交互。
苏米注:这个迭代速度在国产大模型中相当罕见。GLM-5V-Turbo 的核心价值在于「原生多模态」——不是简单拼接视觉编码器,而是从预训练阶段就融合视觉和文本能力。对于使用 OpenClaw/AutoClaw 的用户来说,这意味着可以处理更复杂的任务场景,比如浏览网页、解读图表、生成图文报告等。期待实际使用中的表现。