最近在浏览开源项目时,Fish Audio 凭借 27k Stars 登上了 GitHub 热榜。
与其他热门项目不同的是,它真正有意思的地方不在于热度本身,而在于它在语音合成领域的实际能力突破。
在深入了解其技术细节和应用形态后,我认为这是一个值得关注的成熟型开源项目——它标志着开源 TTS 方案开始具备与商用产品竞争的实力。
项目概览
Fish Audio 是一个开源文本到语音(Text-to-Speech,TTS)合成项目,核心目标是提供高质量的多语言语音生成能力。
项目采用了大规模数据训练策略:
- 训练数据规模:1000 万小时音频
- 语言覆盖:约 50 种语言
- 模型规模:40 亿参数
这个量级的投入表明这不是一个试验性 Demo,而是经过充分验证的生产级方案。
核心性能指标
从技术指标看,Fish Audio 在主流评估维度上已经达到业界领先水平:
| 评估指标 | Fish Audio | 对标方案 | 对标结果 |
|---|---|---|---|
| 中文 WER(词错率) | 0.54% | 业界其他方案 | 最低水平 |
| 英文 WER | 0.99% | 业界其他方案 | 最低水平 |
| 音频图灵测试得分 | 0.515 | OpenAI Seed-TTS | 领先 24% |
| 音频图灵测试得分 | 0.515 | MiniMax-Speech | 领先 33% |
这些数据说明的是一个明确的事实:当前 AI 语音合成已经不再是"听起来像不像人"的初级阶段,而是进入了微观层面的质量竞争。如果不是刻意去辨别,很难从听觉上直接识别合成语音。
核心功能:情绪与风格控制
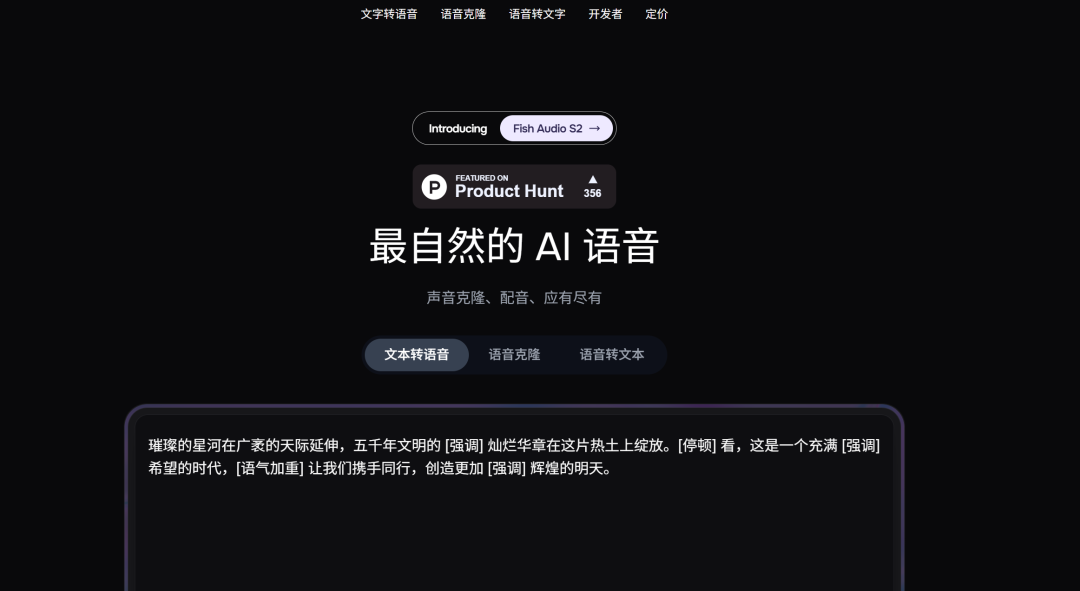
Fish Audio 的差异化之处不仅在于语音质量,更在于它提供了直观的情绪控制机制。用户可以在文本中嵌入情绪标签来实现细粒度的语音表达控制:
- 标准化标签:
[laugh](笑声)、[whispers](耳语)、[super happy](非常开心)、[pitch up](提高音调) - 自然语言描述:系统也支持更接近日常表述的情绪描写
这个设计的实用价值在于,用户不需要理解底层参数,而是可以用接近自然语言的方式直接指定语音的表现形式。这降低了使用门槛,同时大幅提升了声音定制的表达空间。
应用场景适配
基于其功能特性,Fish Audio 适配的应用场景包括:
- 内容创作:有声书、长短视频配音、播客节目制作
- 教育领域:虚拟教师、课程配音、教学内容朗读
- 系统应用:语音播报、提示音生成
- 游戏与互娱:游戏角色对白、虚拟主播、交互式内容
相比通用型 TTS 方案,Fish Audio 在这些场景中的优势在于:中文适配度更高(WER 达到 0.54% 说明中文识别和合成精度已经相当可靠),以及情绪控制能力允许创作者在不额外录音的情况下获得表现力更丰富的语音素材。
安装与部署
项目提供了两种使用方式:
快速体验:访问在线演示平台 https://fish.audio,无需本地部署,可直接测试效果。
本地部署:使用 Docker 容器化部署,简化环境配置:
docker pull fishaudio/fish-speechDocker 方式的优点是屏蔽了操作系统差异和依赖冲突,对于想要集成到自有系统的开发者来说,这是较为便捷的选择。
同时,项目在 GitHub 上开源,用户可以访问 https://github.com/fishaudio/fish-speech 获取源码、文档和最新的技术更新。
类似项目参考
在开源 TTS 领域,还有其他值得关注的项目:
- Coqui TTS:轻量级方案,专注于多语言支持,部署成本较低
- Tacotron 2:学术导向,适合研究人员参考,生产适配度相对较低
- VITS:参数高效,训练灵活性较强,但中文优化程度不如 Fish Audio
相比之下,Fish Audio 的定位是"大规模训练+生产级质量+开源可获取"的组合,这使得它在同类项目中具有较强的实用性。
总结
从我日常接触大量 AI 工具的经验来看,Fish Audio 代表了开源 TTS 项目的一个重要转折点。
它不再是"基础能用"的水平,而是在语音质量、中文适配、情绪表达等多个维度上都达到了可被实际业务采用的标准。
如果你的产品或业务涉及语音生成需求——无论是内容创作、教育还是系统交互——这个项目值得自己动手试一遍。
通过在线体验快速感受效果,再考虑是否投入本地部署,这是最务实的评估路径。中文语音合成这条线,开源方案真的开始能打了。