刚刚,阿里云Coding Plan订阅服务上新Qwen 3.5-Plus、GLM-5、Kimi-K2.5等编程模型,用户订阅后即可自由切换模型。

最近我在使用Claude Code和OpenClaw进行Agent任务开发时,遇到一个困扰已久的问题:每次执行复杂任务,后台的多轮规划、工具调用和自我反思会产生指数级的Token消耗。
按Token计费的模式下,这个成本压力相当可观。
阿里云新上线的Coding Plan,这个问题才得到有效缓解。
这次我想从产品设计和实际应用两个角度,分享这个方案的核心价值以及它如何改变我对AI编程工具成本模型的认知。
为什么Agent工具这么烧Token?
在深入解决方案之前,需要理解问题的本质。
传统Chatbot的工作流相对简单
用户输入,模型响应,一轮对话完成。
但Agent工具(如Claude Code、OpenClaw)的运作机制完全不同:
- 多轮规划:模型需要拆解任务,制定执行策略
- 工具调用:在执行过程中反复调用代码执行、文件操作等工具
- 自我反思:根据执行结果进行修正和重试
根据行业数据统计,单个Agent任务的算力消耗是传统Chatbot的100-1000倍。
这意味着一个看似简单的"帮我修复代码"请求,在后台可能产生数十万的Token消耗。
当按Token计费时,用户会面临一个心理困境:任务越复杂、模型思考越充分,账单反而越高。
这在某种程度上抑制了对Agent工具的充分利用。
新的计费模式
阿里云Coding Plan的核心创新在于,按API调用次数计费,而非按Token计费。
这个转变看似简单,但其背后的逻辑重构很值得玩味:
| 维度 | Token计费 | 请求次数计费 |
|---|---|---|
| 心理成本 | 模型思考越久,费用越高 | 单次请求成本恒定 |
| 适用场景 | 简单对话、短文本处理 | 复杂任务、Agent工作流 |
| 用户行为 | 倾向于简化指令,避免深度思考 | 鼓励提交完整复杂任务 |
从产品经理的角度看,这是一个巧妙的定价策略调整
它改变了用户的使用习惯,让用户更愿意将复杂工作交给AI,而不是拆散成多个简单任务。
支持的模型:
Coding Plan支持的模型包括:
- Qwen 3.5系列(阿里最新发布):在编程和复杂推理上表现出色
- Kimi K2.5(智谱最新迭代):长文本处理和多模态能力突出
- GLM-4.7(智谱):响应速度快,适合高频率Agent调用
这个组合的意义在于——用户可以根据任务特性动态切换模型,而不需要维护多个账户和API密钥。
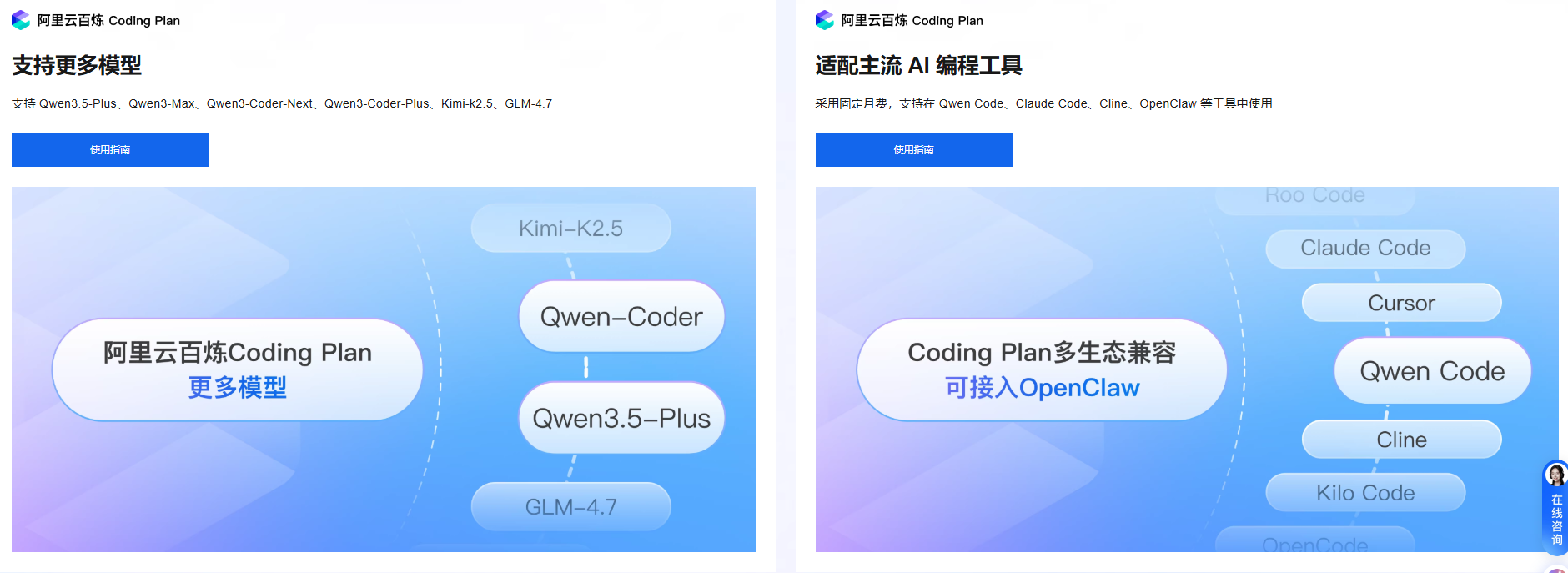
一个订阅套餐,覆盖国内编程领域的主流选择。
操作流程:从订阅到集成的完整链路
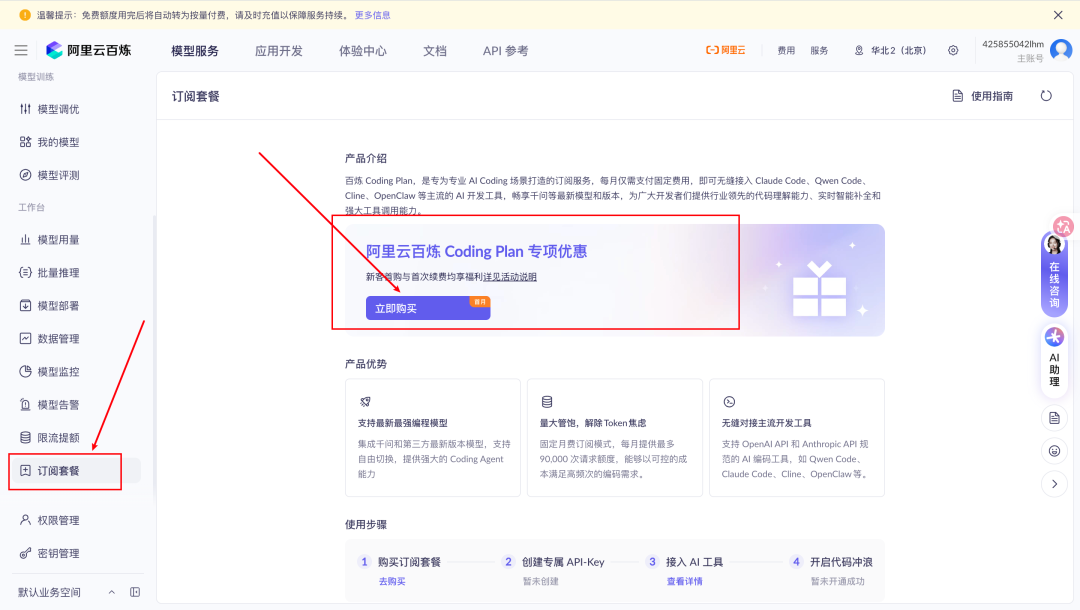
步骤1:订阅套餐
专属优惠券链接:
https://www.aliyun.com/activity/ecs/clawdbot
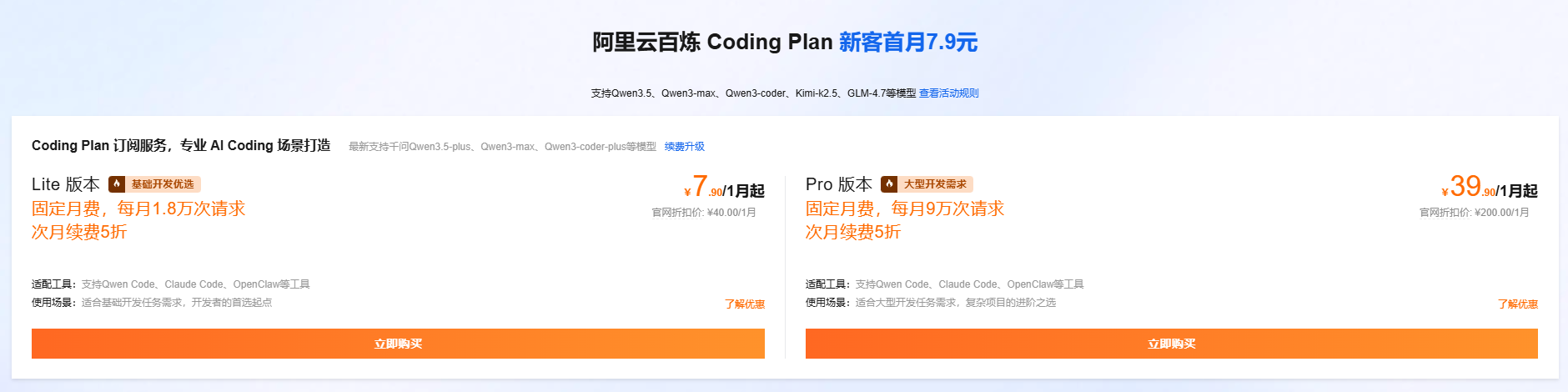
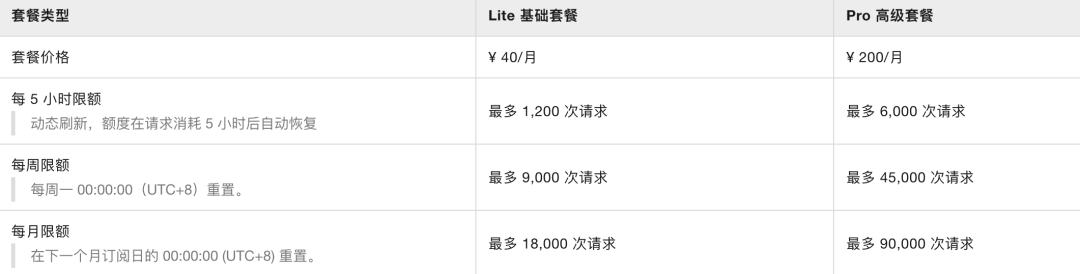
可选套餐:
- Lite基础套餐:18,000次请求/月
- Pro高级套餐:90,000次请求/月
步骤2:获取API凭证
订阅完成后,在控制台生成API Key。注意格式为 sk-sp- 开头,这与百炼通用Key不同。

同时记录两个兼容协议地址:
- OpenAI兼容:
https://coding.dashscope.aliyuncs.com/v1 - Anthropic兼容:
https://coding.dashscope.aliyuncs.com/apps/anthropic

步骤3:集成到Claude Code
编辑Claude Code的setting.json配置文件:
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "你的阿里云API Key",
"ANTHROPIC_BASE_URL": "https://coding.dashscope.aliyuncs.com/apps/anthropic",
"ANTHROPIC_MODEL": "qwen3.5-plus"
}
}
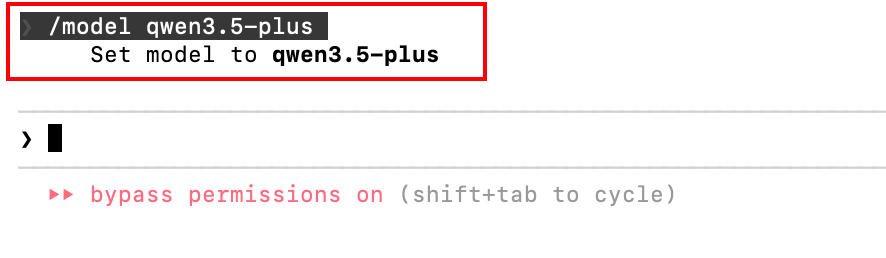
配置完成后,在Claude Code对话框中可通过命令动态切换模型:
/model qwen3.5-plus
/model kimi-k2.5
/model glm-4.7无需重启或修改配置文件。
步骤4:集成到OpenClaw
编辑云部署环境中的/root/.openclaw/openclaw.json:
{
"models": {
"mode": "merge",
"providers": {
"bailian": {
"baseUrl": "https://coding.dashscope.aliyuncs.com/v1",
"apiKey": "你的阿里云API Key",
"api": "openai-completions",
"models": [
{
"id": "qwen3.5-plus",
"name": "qwen3.5-plus",
"reasoning": false,
"input": ["text"],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 262144,
"maxTokens": 65536
}
]
}
}
},
"agents": {
"defaults": {
"model": {
"primary": "bailian/qwen3.5-plus"
},
"models": {
"bailian/qwen3.5-plus": {
"alias": "qwen3.5-plus"
}
},
"maxConcurrent": 4,
"subagents": {
"maxConcurrent": 8
}
}
}
}配置保存后,执行重启命令:
openclaw gateway restart效果评估
案例:营销短视频生成平台的Bug修复
我最近在开发一个短视频脚本生成系统,遇到一个涉及前端状态管理和数据库持久化的Bug:
在脚本库选择页面,如果用户在自定义编辑框输入文案但未点击"保存到脚本库",这段文案应该能直接被引入后续的视频生成Prompt中;但当前系统仍然调用原有的脚本。同时,点击保存按钮后显示成功提示,但数据库中并未成功存储。
使用Qwen 3.5-Plus处理这个问题的观察:
- 响应速度:平均2-3秒内返回初步诊断,较其他服务显著更快
- 稳定性:无出现卡死或延迟响应的情况
- 请求消耗:该任务触发了12次API调用(包括代码审查、假设验证、修复方案生成)
在按Token计费的模式下,这个过程的成本会相当可观;而在按次计费的模式下,成本保持恒定且可预测。
后台监控数据
设置OpenClaw定期监控某个外部信息源(每5分钟调用一次),运行3小时后的使用情况:
- 总API调用次数:21次
- 成本预估:相比按Token计费节省约70%
这个案例说明——按次计费模式下,用户可以更心无旁骛地将重复性的监控、分析任务交给Agent,而不需要频繁评估成本效益。
模型选择指南
基于实际使用体验,三款模型的特点如下:
| 模型 | 响应速度 | 长文本处理 | 编程能力 | 推荐场景 |
|---|---|---|---|---|
| Qwen 3.5-Plus | 快 | 良好 | 优秀 | 实时编程、Agent工作流 |
| Kimi K2.5 | 中等 | 优秀 | 良好 | 文档分析、多模态任务 |
| GLM-4.7 | 快 | 良好 | 良好 | 高频调用、实时助手 |
成本对比与选型建议
根据使用模式的不同,选择建议如下:
- 轻度使用者(偶尔写脚本、辅助工作):Lite基础套餐足够,月18,000次请求可覆盖日常需求
- 开发者或Agent重度依赖者(日常自动化工作流、复杂系统集成):Pro高级套餐月90,000次请求,基本实现成本可控的"算力自由"
相比市场上其他Coding Plan订阅服务,阿里云在价格竞争力上有明显优势,且模型覆盖面更广。
总结
阿里云Coding Plan的价值并不在于"最便宜"或"功能最全",而在于它重新定义了AI编程工具的成本模型。
按次计费这个看似简单的改变,实际上解决了一个更深层的问题:如何让用户充分信任和利用Agent工具的深度推理能力,而不是被成本焦虑所束缚。
对于我来说,这意味着可以更自信地将复杂的自动化任务交给AI,而不是在每次调用时都在心里默算Token的成本。
这种心理障碍的消除,往往比功能本身的提升更能改善实际的生产力。
如果你也在为Agent工具的成本压力而困扰,不妨尝试一下这个方案。
特别是在首月优惠期间,成本试错的门槛已经非常低。
专属优惠券链接:
https://www.aliyun.com/activity/ecs/clawdbot