智谱于 2026 年 4 月 8 日正式开源 GLM-5.1,这是一款拥有 744B 总参数、40B 激活参数的混合专家模型(MoE),采用 MIT 开源协议。该模型在长程任务执行能力上取得显著突破,能够零人工介入独立工作超过 8 小时。
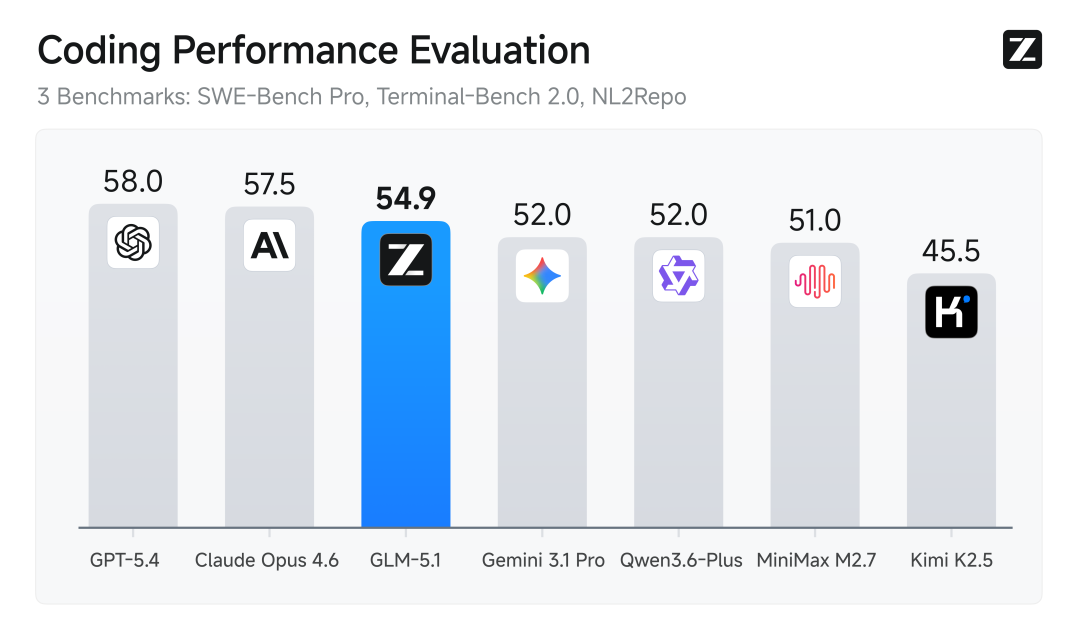
在 SWE-Bench Pro 基准测试中,GLM-5.1 取得 58.4 分的成绩,超过 GPT-5.4(57.7)和 Claude Opus 4.6(57.3),位列全球第一。在三项编码基准综合评分中,GLM-5.1 排名全球第三、开源模型第一。
长程任务能力验证
GLM-5.1 的核心突破在于其长程任务执行能力。模型能够在长时间任务中持续保持有效工作状态,完成短对话模型无法处理的复杂工程任务。
案例一:自主优化向量搜索引擎,655 轮迭代
GLM-5.1 使用 Rust 从零实现了一个向量搜索引擎,并自主完成测试、分析和代码迭代,连续运行 655 轮优化循环。
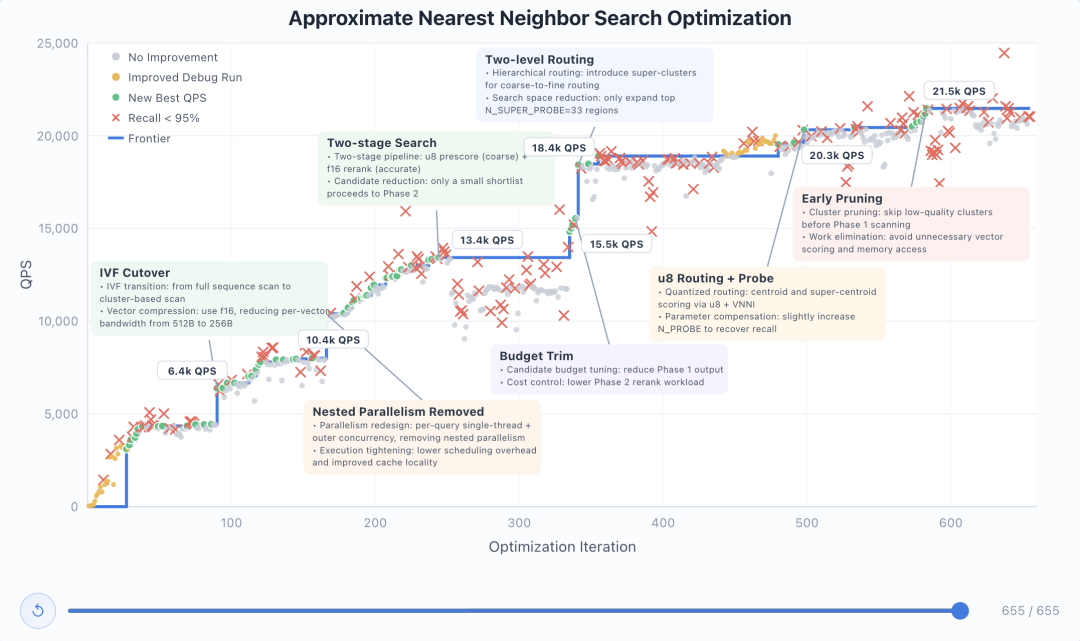
在优化过程中,模型完成了 6 次结构性策略跳跃,从最初的全库扫描方案,逐步优化至两级路由 + 提前剪枝架构。最终查询速度从 3108 QPS 提升至 21472 QPS,性能提升 6.9 倍。
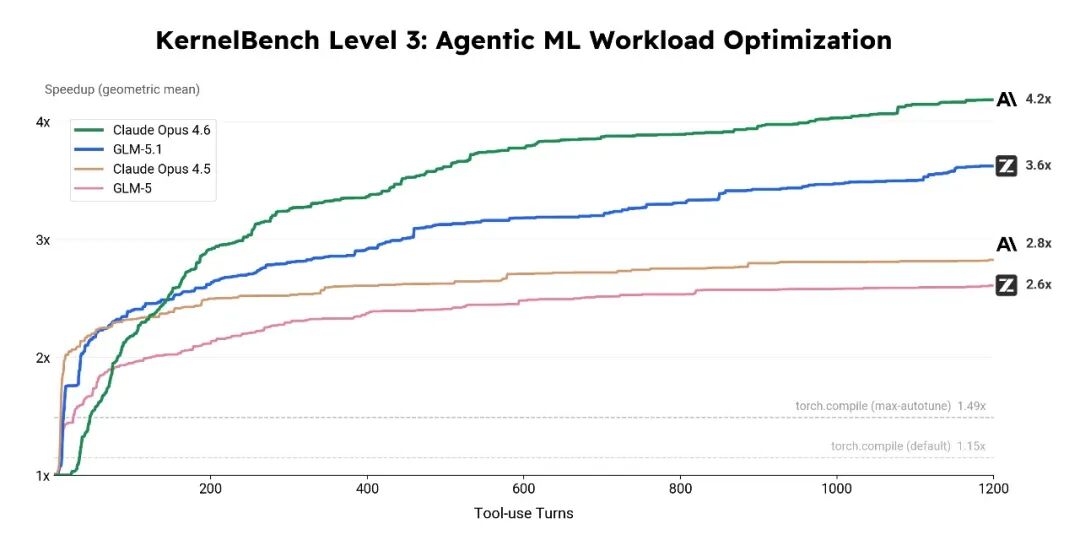
案例二:50 个 AI 模型加速代码编写,1000+ 轮工具调用
KernelBench 基准测试要求模型为 50 个真实 AI 模型(包括 MobileNet、VGG、MiniGPT、Mamba 等)编写 GPU 加速代码,在保持功能完全一致的前提下提升运行速度。

GLM-5.1 在 1000 多轮工具调用中自主编写了 Triton 和 CUDA 加速代码,最终实现 3.6 倍加速,远超 PyTorch 自带优化器 torch.compile 的 1.49 倍。
Benchmark 详细数据
GLM-5.1 的能力提升主要集中在编码和智能体两个维度,提升幅度在 19%-42% 之间。推理能力与 GLM-5 基本持平,与 Gemini 3.1 Pro、GPT-5.4 仍存在明显差距。
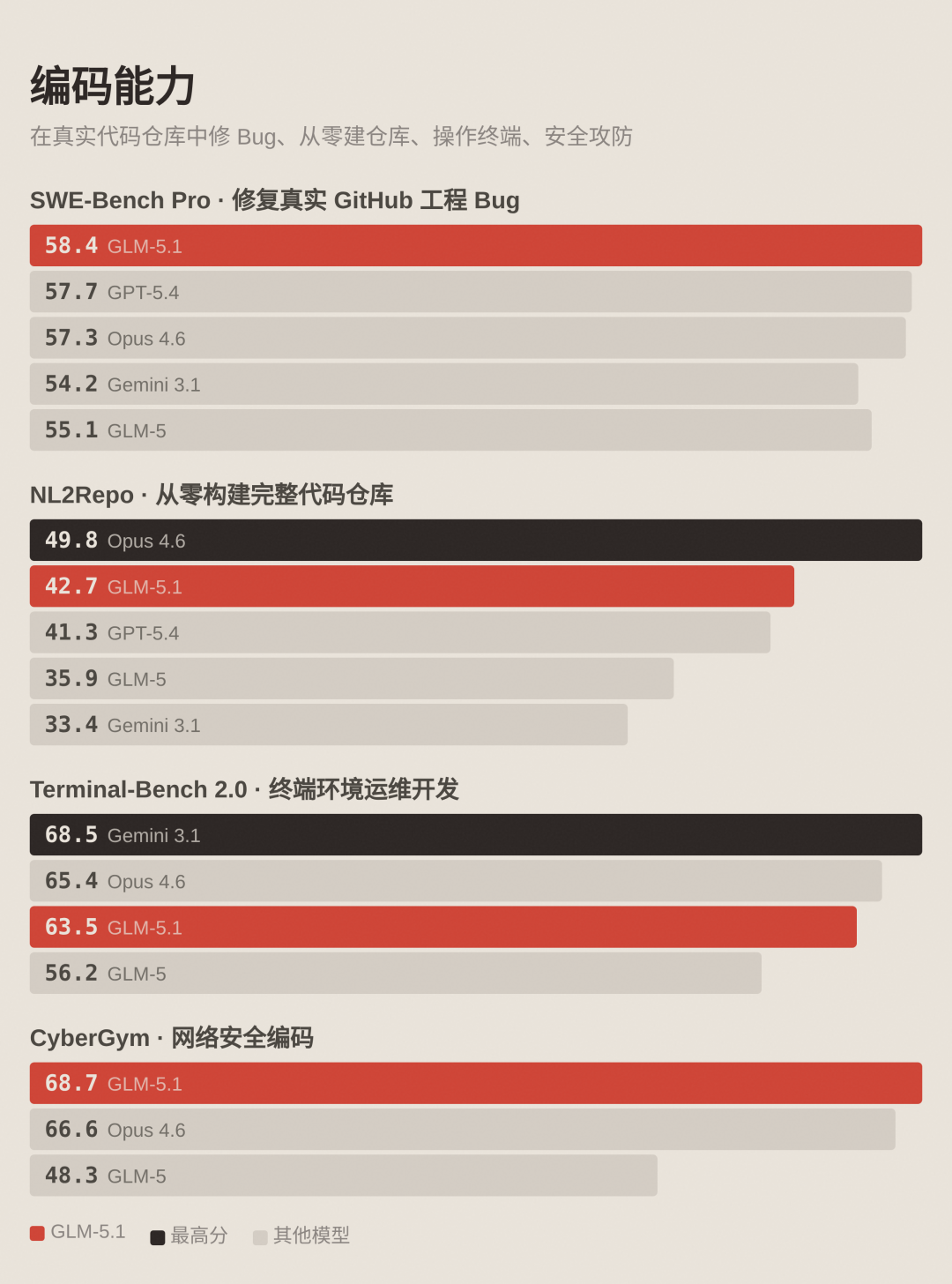
编码能力
SWE-Bench Pro 评估模型在真实 GitHub 仓库中定位并修复高难度工程 Bug 的能力,是目前最接近真实软件开发的单项指标。GLM-5.1 得分 58.4,全球最高。
NL2Repo 要求模型根据自然语言描述从零构建完整的代码仓库,测试系统级工程能力。GLM-5.1 得分 42.7,相比 GLM-5 的 35.9 提升 19%,与 Claude Opus 4.6(49.8)仍有 7 分差距。
Terminal-Bench 2.0 评估模型在真实终端环境中解决系统管理、运维和开发任务的能力。GLM-5.1 得分 63.5,GLM-5 为 56.2。
CyberGym 是网络安全编码基准,要求模型完成渗透测试、漏洞分析等安全工程任务。GLM-5.1 得分 68.7,相比 GLM-5 的 48.3 提升 42%,是进步最大的单项。

智能体能力
BrowseComp 测试模型通过自主浏览网页解决复杂信息检索问题的能力。GLM-5.1 带上下文管理得分 79.3。
τ³-Bench 在模拟客服场景中测试对话式 Agent 的双向控制能力。GLM-5.1 得分 70.6。
MCP-Atlas 评估模型在多步骤工作流中调用外部工具(MCP 服务器)的能力。GLM-5.1 得分 71.8。
Vending Bench 2 让模型经营一年的模拟自动售货机生意,测试长期规划和资源管理能力。GLM-5.1 最终账户余额 $5634,GLM-5 为 $4432,Claude Opus 4.6 为 $8017。
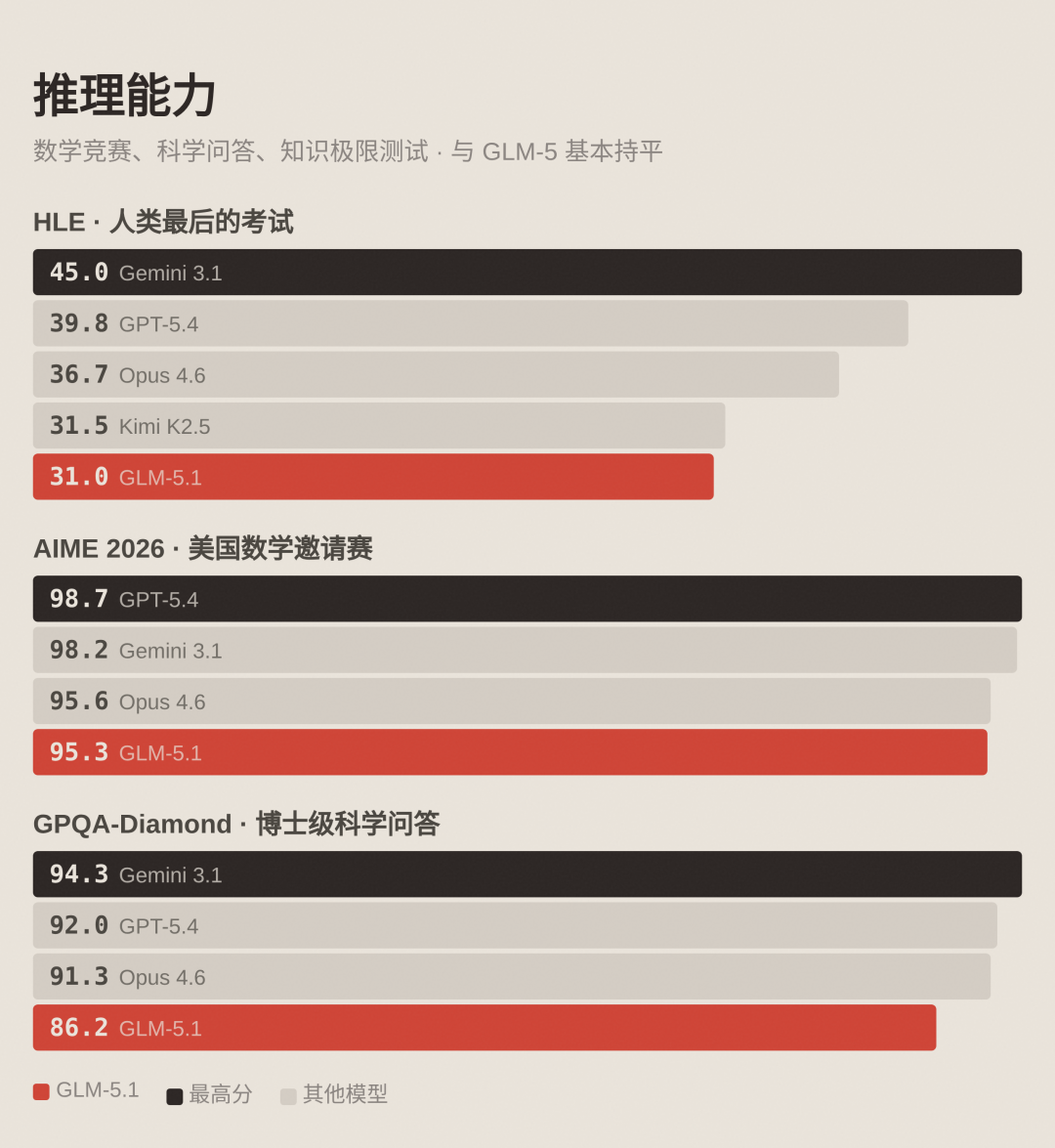
推理能力
HLE 被称为"人类最后的考试",由各领域专家出题,测试模型的知识和推理极限。GLM-5.1 得分 31.0,Gemini 3.1 Pro 为 45.0,GPT-5.4 为 39.8。
AIME 2026 是美国数学邀请赛 2026 年赛题。GLM-5.1 得分 95.3,各主流模型在这项指标上已非常接近。
GPQA-Diamond 是由博士级专家出题的科学问答,涵盖物理、化学、生物等领域。GLM-5.1 得分 86.2。

技术架构解析
GLM-5.1 的技术细节沿用 GLM-5 的论文框架,技术报告已公开在 arXiv(编号 2602.15763)。以下是与长程能力直接相关的核心技术要点。
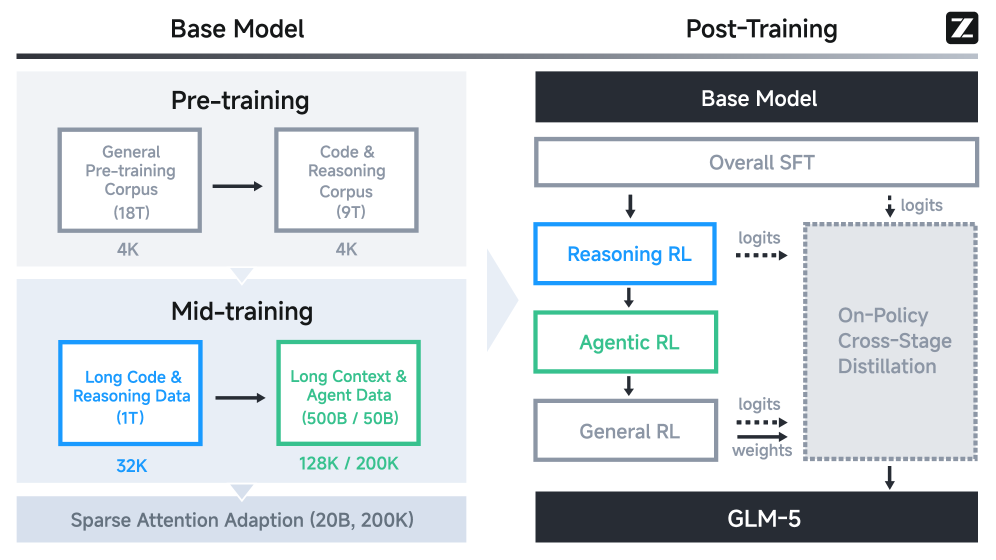
异步 RL 基础设施
传统同步 RL 处理 Agent 任务时 GPU 空闲严重,因为不同任务的轨迹长度差异极大。智谱将训练引擎和推理引擎解耦到不同 GPU 设备上:推理引擎持续生成轨迹,达到阈值后批量送训练引擎更新模型,权重定期同步。
系统通过"多任务 Rollout 编排器"支持超过 1000 个并发 rollout,每个任务实现为独立的微服务,注册到中央编排器统一调度。
TITO(Token-in-Token-out)
异步 RL 中一个容易被忽视的问题:将推理引擎当作黑箱只取最终文本,训练器需要重新分词来重建轨迹。分词边界的微小不一致会在数千步的 Agent 任务中逐步累积。
TITO 直接消费推理引擎产出的 token ID 流和元数据,保持 action 级别的精确对应,消除重新分词带来的误差。
DSA 与 RL 的适配
GLM-5 在预训练阶段引入 DSA(DeepSeek Sparse Attention),用动态稀疏注意力将长上下文的注意力计算降低约 1.5-2 倍。
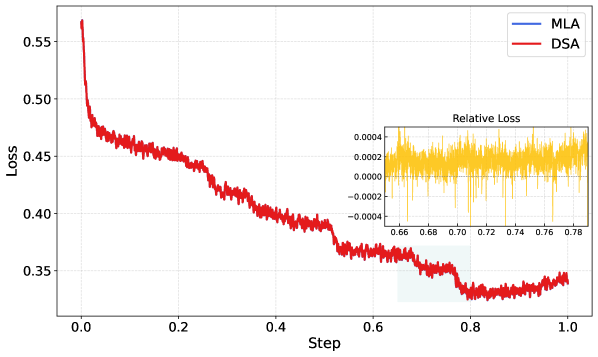
在 RL 阶段发现:DSA 的 indexer 必须使用确定性的 torch.topk。非确定性的 CUDA 实现会导致 RL 训练几步之后 entropy 急剧下降,性能严重退化。
双侧重要性采样
异步 RL 中不同轨迹可能由不同版本的模型生成,off-policy 问题严重。传统方案需要维护历史策略检查点来计算重要性采样比率。
智谱的方案更直接:直接用 rollout 时的 log-probability 作为行为策略的代理,用 token 级别的双侧裁剪机制控制信任域,超出区间的 token 从梯度计算中屏蔽。不需要跟踪历史策略。
环境规模
编码任务:构建超过 10000 个可验证训练环境,覆盖 Python、Java、Go、C、C++、JavaScript、TypeScript、PHP、Ruby 9 种语言。
搜索任务:构建 Web 知识图谱,从 200 万 + 高信息网页中抽取实体和关系,合成高难度多跳 QA 对。
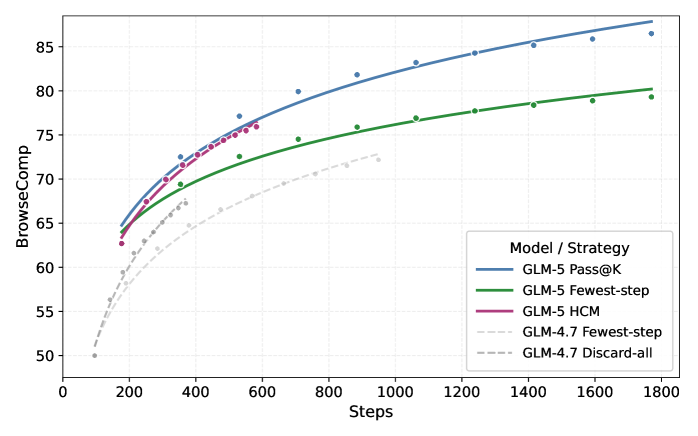
国产芯片全栈适配
GLM-5 从第一天起就完成了七家国产芯片平台的全栈适配:华为昇腾、摩尔线程、海光、寒武纪、昆仑芯、沐曦、燧原。
在华为昇腾上通过 W4A8 混量化、Lightning Indexer 融合算子、MLAPO 预处理优化等手段,单节点性能接近双卡国际集群。
开源与使用
GLM-5.1 权重以 MIT 协议开源,提供 BF16 和 FP8 两个版本。支持 vLLM、SGLang、xLLM(华为昇腾)、Ktransformers 本地部署。
API 方面,GLM-5.1 已纳入 GLM Coding Plan(Max/Pro/Lite 套餐),支持 Claude Code、OpenCode、Kilo Code、Roo Code、Cline 等工具接入。
GLM-5.1 即将上线 chat.z.ai。
参考资源
- GLM-5.1 Blog
- GLM-5 Technical Report
- GitHub
- Hugging Face
- ModelScope 魔搭社区
- GLM Coding Plan
- BigModel 开放平台