作为一个长期用AI工具做内容设计和产品探索的人,我对视频生成的“可控性”一直很敏感:角色能否保持一致、镜头是否能按叙事意图切换、声音和口型是否对齐。
今天把万相2.6试了一圈,我的核心结论是:它把创作方式从“纯提示词驱动”推进到“以角色为中心的参考驱动”,并且把声画同步和多镜头规划做到了一个可用的水平,适合短视频、广告与预演等场景的快速产出。
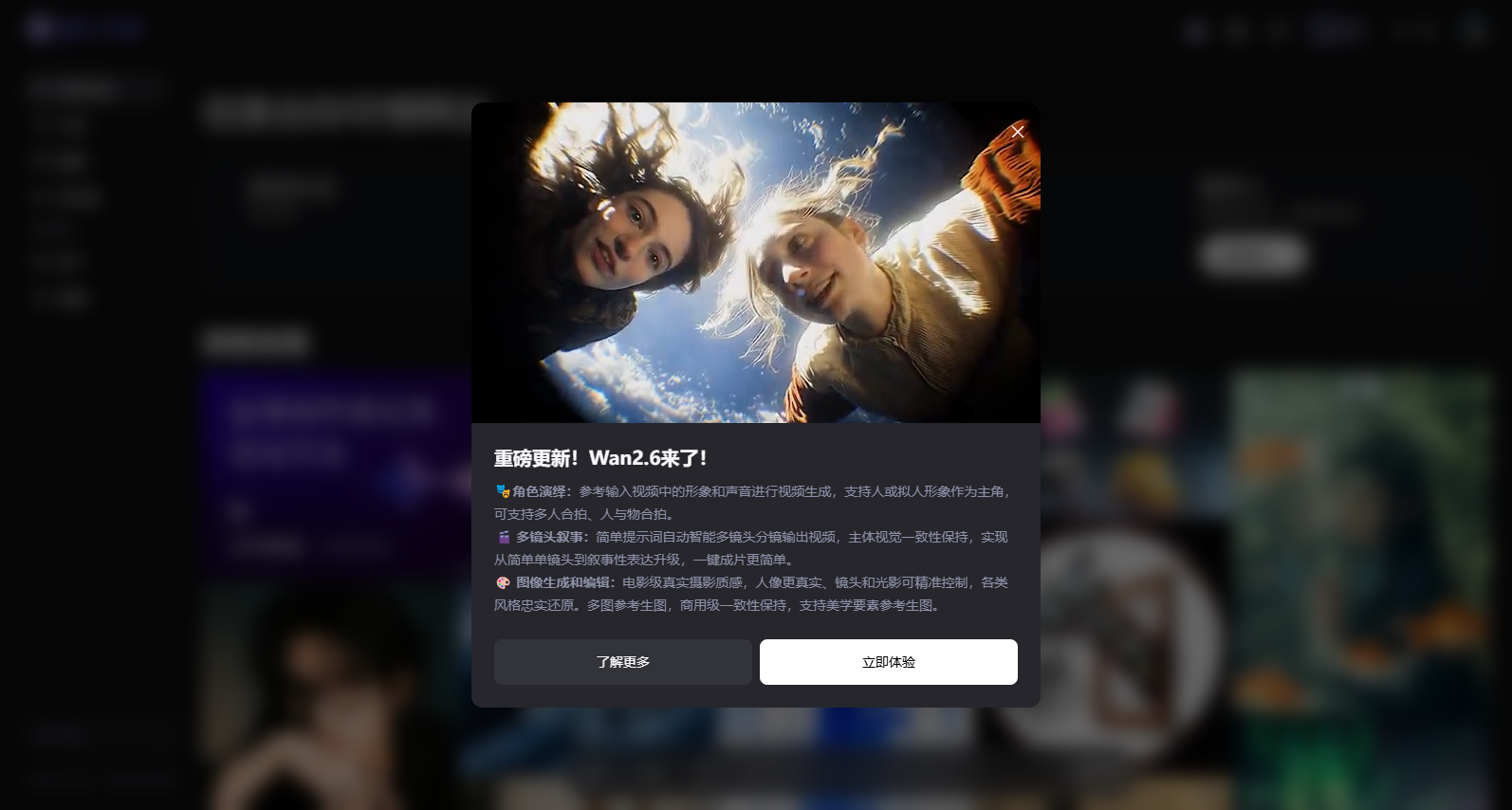
关键更新
多模态参考生成
继文本、图像、音频之后,Wan 2.6 支持视频参考生成。可复刻任意 5s 视频内的人物、动物、动画人物、物体,并作为后续视频创作的主角,不止复刻形象,还能复刻音色;支持主角的单人表演和双人合拍,并输出声画同步的视频(包含配乐、音效、人声)。
支持 15 秒 1080P 高清视频输出,更真实细腻的画面质感、更高级的美学表现
实际体验
合拍对话(角色+音色参考):上传我自己的短视频作为音色参考,再设定一个历史人物形象,同框对话。口型和语义对应准确,镜头在说话者时有推进,音色之间区分明显。对双人场景来说,这解决了我过去经常遇到的“声音串味”和“镜头只会停在一个景别”的问题。
音频驱动的图生视频:只给一张正面图和一段我录的快语速音频,不写提示词。模型自动完成口型匹配、情绪节奏和镜头切换,连贯性比我之前试过的同类方案更稳定。
单图+提示词的播客段子:一张猫狗合照+分场景提示词。模型在说话角色时推进镜头、角色远离镜头时音量减小;两种音色区分度清晰。属于“拿来就能发”的效果。
结构化对比
| 维度 | 常见AI视频(近半年实测体验) | 万相2.6 |
|---|---|---|
| 角色控制 | 主要依赖文本或单图引导,角色一致性弱,多人同框易混乱 | 角色参考(人/动物/物体),外观与音色可同步,支持单人与双人合拍 |
| 声画同步 | 常见做法是后期叠加语音,口型与节奏常不匹配 | 从参考音频提取音色与节奏,口型对齐度提升,多人场景更易区分 |
| 镜头组织 | 多为单镜头生成,分镜需要人工拼接,角色细节易漂移 | 文本驱动的智能分镜,镜头切换保持关键视觉信息相对一致 |
| 时长与分辨率 | 以短片段为主,长时连贯性与一致性是难点 | 文生/图生最长15秒,参考生视频10秒;最高1080P |
| 使用门槛 | 提示词友好,但多人与分镜需要额外剪辑与配音 | 建议准备参考图/音频+简洁分镜提示词,减少后期剪辑与配音工作量 |
| 适合人群 | 单镜头实验、素材快速试水 | 短视频创作者、广告与品牌内容团队、影视前期预演、虚拟IP运营 |
如何用?
准备参考:上传角色的图像或视频;若需要音色统一,准备干净的语音样本。
编写提示词:用“场景1/2/3…”的方式描述镜头、景别、说话者和语句;同框可明确角色名称。
调用角色:在界面中录制或上传素材,使用“@角色名”触发参考;选择文生/图生/参考生模式。
质量检查:重点看口型对齐、镜头切换的一致性、音色区分;若大远景模糊,尝试以中近景为主。
体验入口
阿里云百炼:https://bailian.console.aliyun.com/?tab=model#/model-market/all?providers=wan
总结
万相2.6的价值在于把“角色与音色的一致性”和“多镜头的基本可控”整合到同一条生成链路里。
对于需要快速产出、又希望形象统一的团队(短视频、广告、虚拟IP、影视预演),它能显著减少剪辑与配音的重复劳动,把精力转到脚本与镜头意图上。
现阶段的限制也清晰:超长叙事、复杂调度仍需人工;远景细节还不稳定。
整体而言,这是一条更贴近实际制作流程的升级路径,我会把它纳入日常工具栈,用于系列化内容与方案预演。