语音。每天有数十亿人通过说话产生信息,这些数据天然就是训练 AI 的宝库。
也因此,AI 语音正在成为下一个重点方向:语音助手、实时翻译、口语陪练、情感陪伴应用不断涌现。但问题也随之而来:高延迟、难打断、音频数据复杂、开发成本高……这些往往让开发者举步维艰。

最近我体验了一款很有潜力的开源项目 ,它几乎解决了我在做语音应用时的所有痛点。仅发布一年,就已经收获 7400+ Star,登顶 GitHub 热榜第一。
项目介绍
TEN Framework 是一个支持 实时对话 的 Voice Agent 引擎。核心目标很直接:让开发者用最短的时间,搭建一个可交互的语音 AI 应用。
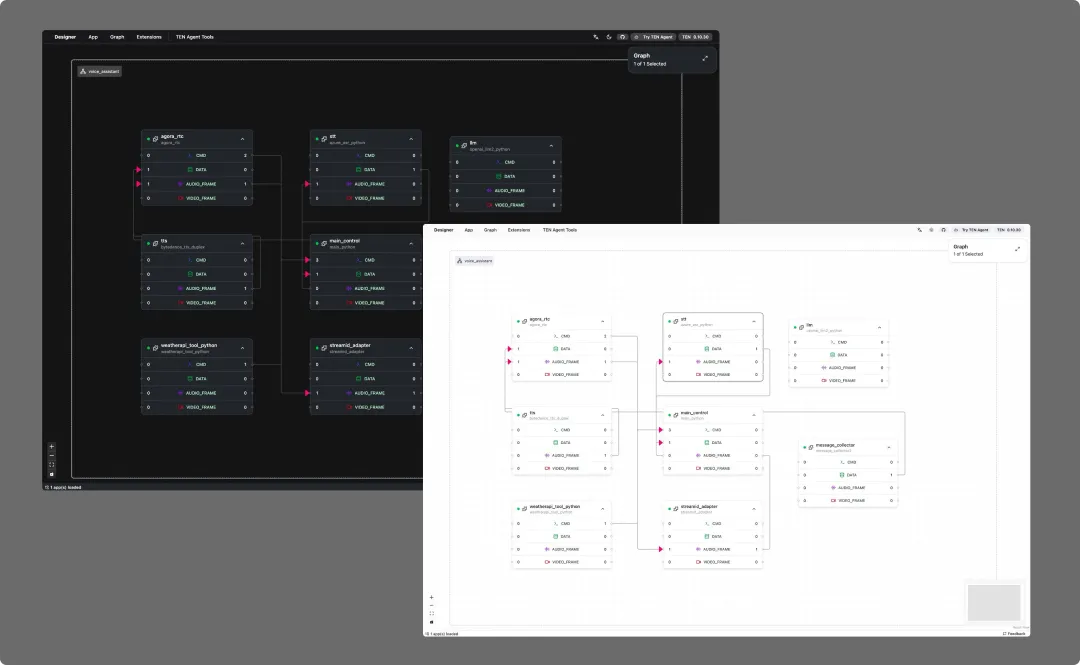
它不仅能实现 1 秒级低延迟的语音交流,还支持在对话过程中随时打断 AI,让交互体验更贴近真实沟通场景。
更重要的是,它天然支持多模态:语音、文本、图像都能作为输入输出,提前帮你解决多模态数据传输的复杂性。
核心功能亮点
低延迟、可打断的语音交互:1s 延迟,支持实时打断,体验接近真人对话。
多模态输入输出:支持语音、文本、图像,适配更复杂的 AI 场景。
可视化工具 TMAN Designer:拖拽式搭建工作流,零门槛做语音机器人。
灵活模型接入:支持 OpenAI、Gemini、Deepseek 等主流模型,甚至 bring your own models。
生态兼容:能快速接入 Dify、Coze,或通过 MCP 融入自家产品。
跨平台语言支持:兼容 C++/Go/Python/Node.js 等,适配常见开发场景。
应用场景示例
在 GitHub 社区里,已经能看到许多基于 TEN 的精彩案例:
3D 数字人语音助理:结合 Trulience Avatars,直接和数字人自然对话。
AI 有声故事书:结合文生图 + 语音模型,生成带画面的沉浸式故事体验。
语音控制桌面应用/机器人:通过语音指令直接操作本地应用或硬件。
电话智能客服:构建实时语音应答客服系统。
这些案例已经能覆盖从消费级应用到企业服务的多个方向。
安装与部署
TEN 的部署方式对新手很友好,支持多种方式:
Docker 本地部署:一键启动,开箱即用。
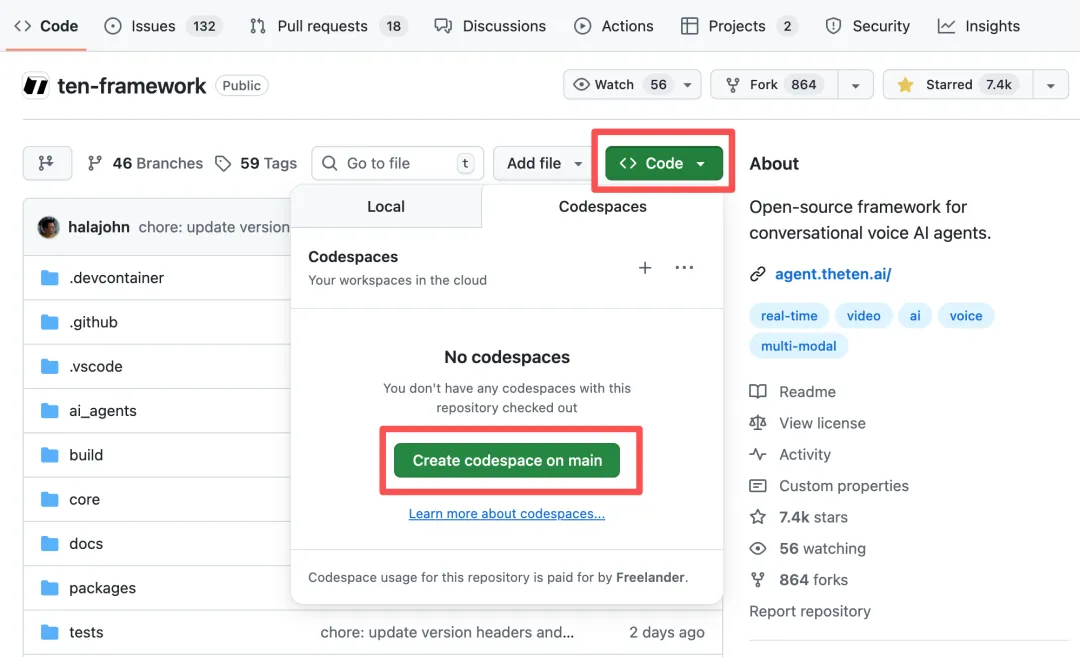
GitHub Codespace 部署(推荐):无需本地配置,在线 VSCode 环境直接运行。
简单流程大概是:
创建一个新的 codespace → 初始化环境
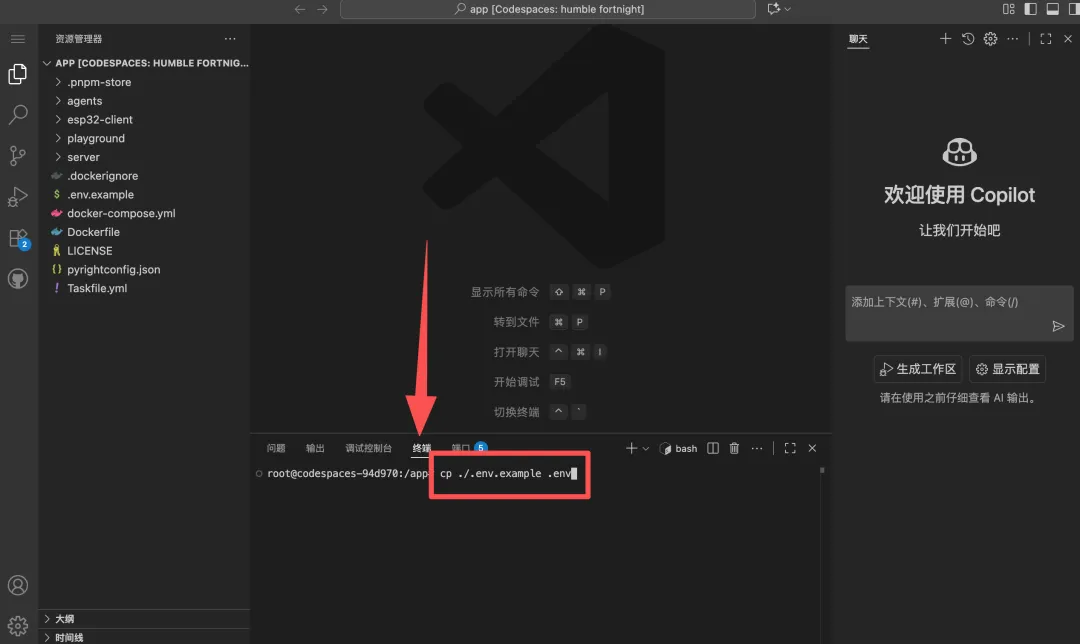
打开VSCode,运行在线环境输入 cp ./.env.example .env
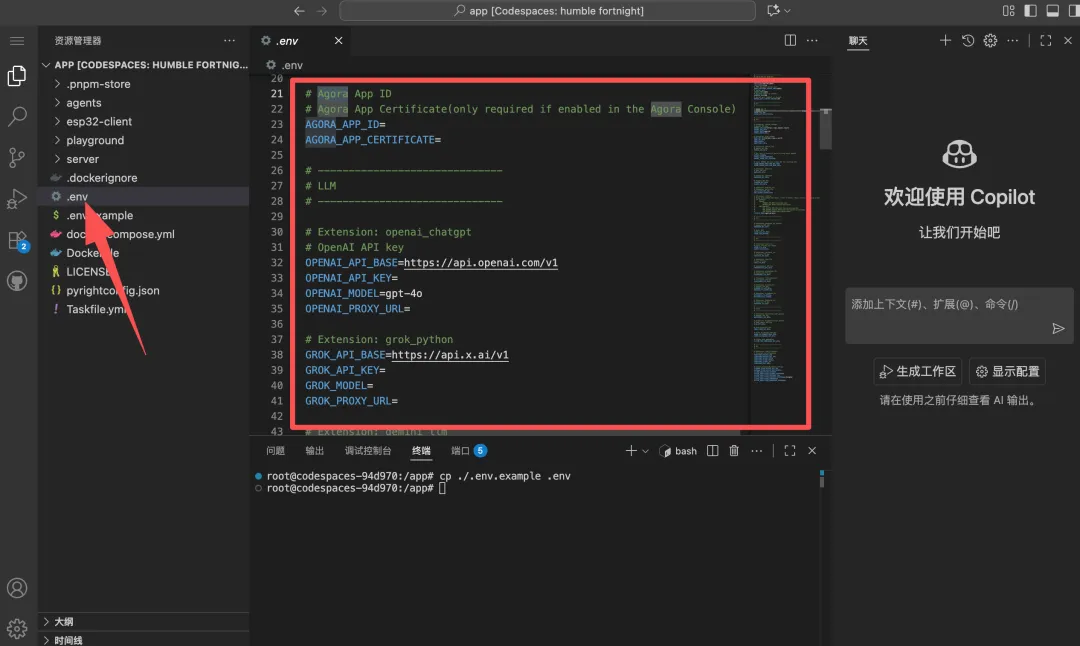
进入复制 .env.example → 填写 API Key(如声网传输、OpenAI 文本处理、Azure TTS 等)
执行 task use 构建 Agent → task run 启动服务
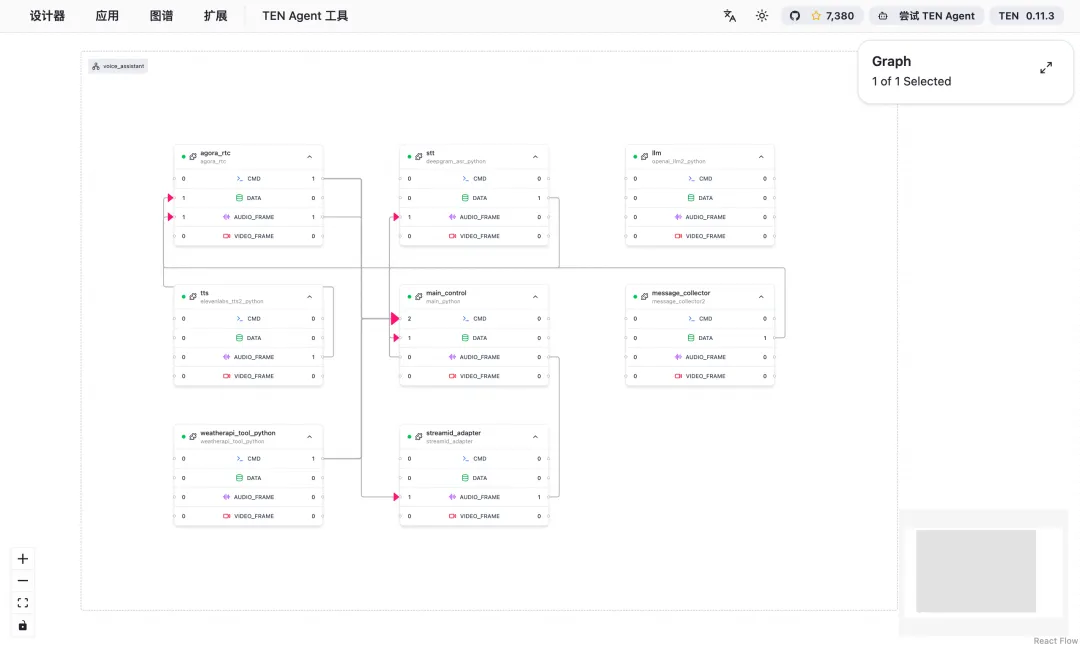
浏览器打开可视化界面 → 拖拽配置 LLM、STT、TTS 模型 → 一键运行
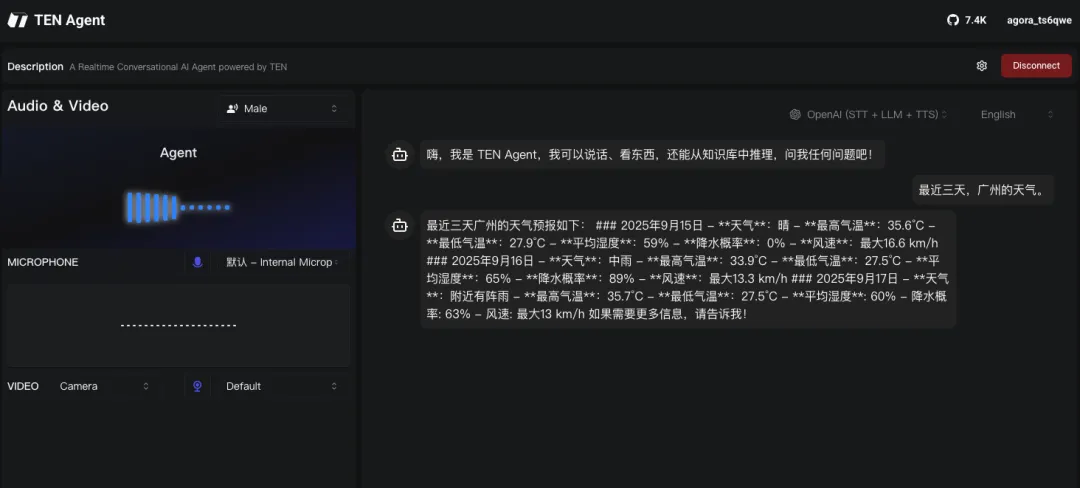
几分钟就能跑起来,非常适合快速验证想法。
与相似项目的对比
如果你关注过语音开发工具,可能会想到 Vocode、Realtime AI 等方案。相比之下:
-
Vocode:偏向于电话客服、VoIP 场景,功能集中但定制能力相对有限。
-
Realtime AI:主打低延迟交互,但缺少可视化搭建和多模态支持。
-
TEN:功能覆盖更全面,既适合做原型验证,又能支持复杂应用开发。
如果你打算在语音 AI 上做深耕,TEN 的灵活性和生态支持会更有优势。
总结
在 Apple 发布会看到 AirPods Pro 3 引入 AI 翻译功能后,我再次确信 语音交互将是未来 AI 的关键场景。相比键盘和屏幕,语音才是更自然、更通用的交互方式。
对开发者来说,TEN Framework 就像一把现成的利器:它提前帮我们解决了延迟、打断、多模态传输等“卡脖子”问题,还提供了可视化工具和详细中文文档,降低了上手门槛。
如果你对 AI 语音应用感兴趣,无论是做语音助手、数字人还是实时翻译,TEN Framework 值得你马上试试。
GitHub:https://github.com/TEN-framework/TEN-framework
Demo: