Agent 辅助开发:SGLang 团队的工程实践
SGLang 团队最近做了一件有趣的事:把自家在 benchmarking、profiling、CUDA kernel 调优、生产问题排查等方面的工程经验,编码成可执行的 agent skills。结果相当亮眼——3 个 KDA-Pilot kernel PR 已合并上游,B200 上 kernel 加速最高 2.75x,Qwen3-Next 吞吐量提升 71.4%,TTFT 从 456ms 降到 168ms。

为什么 SGLang 适合 Agent 辅助开发?
SGLang 是高性能 LLM 和 multimodal 模型的 serving 框架。随着模型和硬件路径膨胀,开发中反复出现几个典型问题:
- LLM 路径复杂:一个性能问题可能跨 Python runtime、scheduler、CUDA graph、Triton/CUDA kernel、FlashInfer、分布式通信、模型特定 wrapper
- Diffusion 路径同样复杂:慢的 denoise pass 可能涉及 pipeline/stage 划分、DiT blocks、attention 后端、torch.compile graph break、CFG/SP 并行、VAE、自定义 fused kernel
- 验证成本高:很多改动必须在真实模型和真实 workload 上测试(H100、H200、B200、RTX 5090),本地单元测试不够
- Profile 难以手动复用:一个 trace 可能包含几百个 kernel launch,手动读 Perfetto 容易漏掉 kernel 到 Python 源码的映射
- 性能结论严重依赖上下文:GPU 类型、shape、batch size、并行度、精度、后端、编译状态都会改变结果
这些问题天然适合 agent——启动 server、固定 workload、收集 trace、分析 profile、加测试、记录实验结果,都有明确的输入输出,适合脚本化和重复执行。
从 Prompt 工程到 SKILL 体系
SGLang 团队把常用工作流编码成技能文件(.claude/skills),每个技能都回答了:什么时候用、怎么启动、怎么验证、怎么决策、怎么交付。目前覆盖的层次包括:
- debug-cuda-crash:记录 custom op/kernel API 边界的输入、异常和 dump,把瞬时崩溃变成可离线分析的样本
- llm-serving-auto-benchmark:在 SGLang 和其他 OpenAI 兼容框架上跑公平、有界、可恢复的 serving benchmark
- llm-serving-capacity-planner:解析启动日志,解释权重内存、KV cache 预算、CUDA graph 开销
- llm-torch-profiler-analysis:产出固定的 kernel 表、overlap 机会表、fuse pattern 表
- llm-pipeline-analysis:把 torch profiler trace 切分为 forward pass、层和 kernel 流,定位稳态瓶颈
- sglang-diffusion-benchmark-profile:捕获 denoise 延迟、perf dump 和 torch profiler trace
- sglang-prod-incident-triage:收集 live-server bundle、保存失败请求、重放、路由到 crash/hang/profile 工具
- sglang-humanize-review:按真实 maintainer 讨论模式 review patch
最近合并的典型案例
Router 长上下文 tokenization 去重(PR #28744):DeepSeek-V4-Flash 上,60k/125k token 提示的 idle TTFT 降低约 29%/41%,负载下 TTFT 降低 34%–49%。
Qwen3-Next FlashInfer allreduce fusion(PR #22664):H100 TP=4 上,请求吞吐从 5.49 req/s 提升到 9.41 req/s(+71.4%),平均 TTFT 从 456ms 降到 168ms。
Cohere2Moe NVFP4 fused-MoE(PR #27401):B300 上,chat 场景请求吞吐比 SGLang 此前默认路径提升 26%,比另一个开源框架高 4.1%。
Spectral Progressive Diffusion(PR #27524):FLUX.1、FLUX.2、Z-Image、Wan、Qwen-Image 的 denoising 加速 1.6x–2.32x。
LTX-2 VAE decode channels-last-3d(PR #27431):decode 阶段从 5.41s 降到 3.84s(1.41x),峰值预留内存从 71.81 GiB 降到 62.12 GiB。
Profile 分析的两步法
SGLang 性能工作中一个常见错误是只看总耗时,或者打开 Perfetto 看几分钟就凭直觉判断"这个应该融合"。实践中通常两个 profiler 技能配合使用:
第一步:llm-torch-profiler-analysis 把全局 profile 转成三张固定表格——Kernel Table(按阶段汇总 GPU 时间占比、launch 次数、kernel 类别,映射回 Python 源码)、Overlap Opportunity Table(识别剩余 overlap 空间)、Fuse Pattern Table(对比已有的融合/overlap 路径)。
第二步:llm-pipeline-analysis 把热点定位到具体的 forward pass、层类型和 kernel 流。读取 Chrome trace JSON 和模型 config.json,用层边界 anchor kernel 切分 trace,产出 forward pass 摘要、逐层时间线、层聚类统计和计算流表。
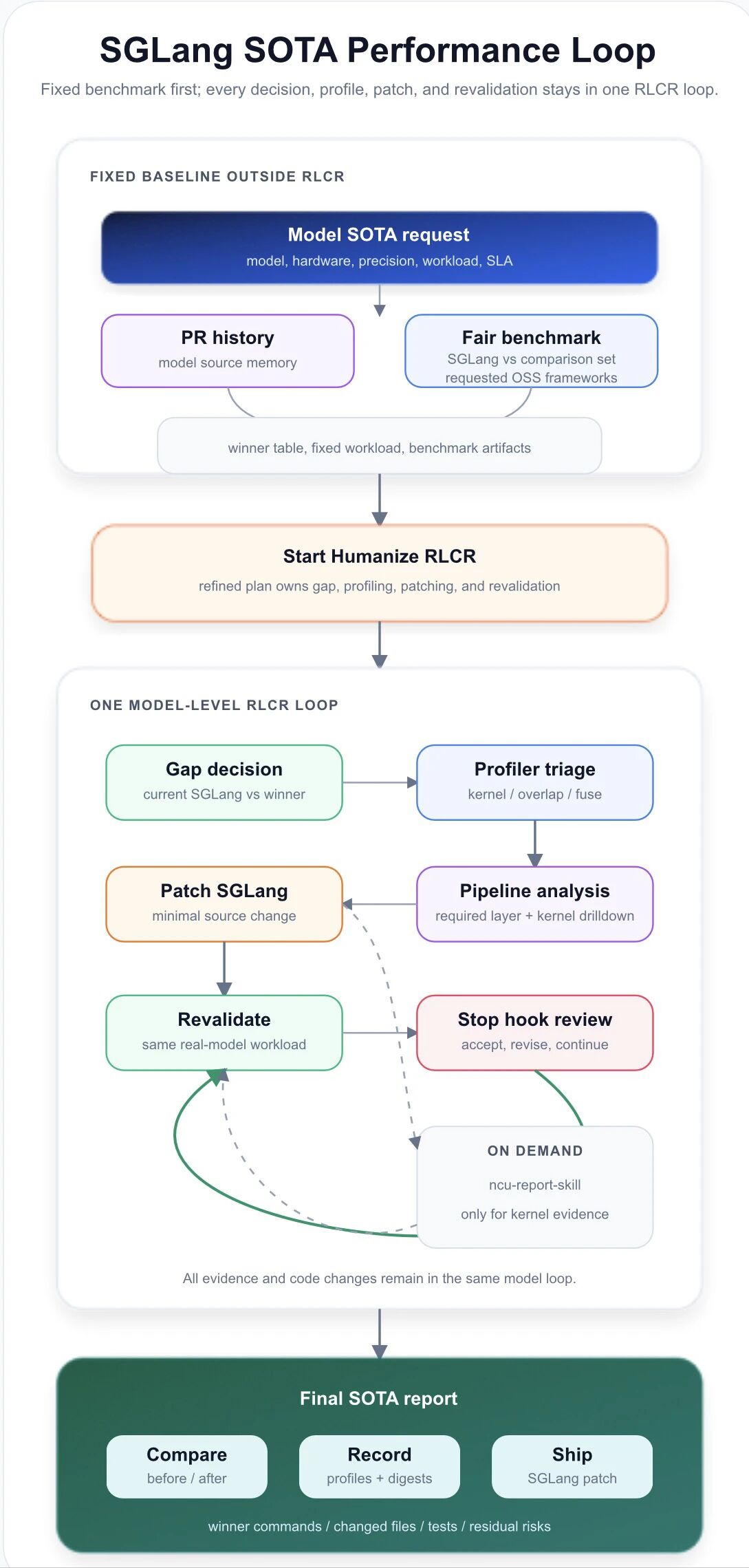
Loop Engineering:把"追 SOTA"变成可重复流程
单次优化可以用一个 skill 搞定。但十几轮实验之后,问题变了:哪个 candidate 最好、哪些方向已经失败、benchmark 是否还和 baseline 对齐、什么时候该停。这些状态不能只活在 chat context 里。
SGLang SOTA Performance Loop 是一个构建在 Humanize/RLCR 之上的工作流,分六步:定义目标边界 → 先跑公平搜索 → 判断差距 → 用 profile 解释差距 → 只在有证据支持的路径上 patch → 在相同 workload 上重新验证。每一轮都记录 benchmark、profile、精度、失败尝试、环境信息和清理动作。
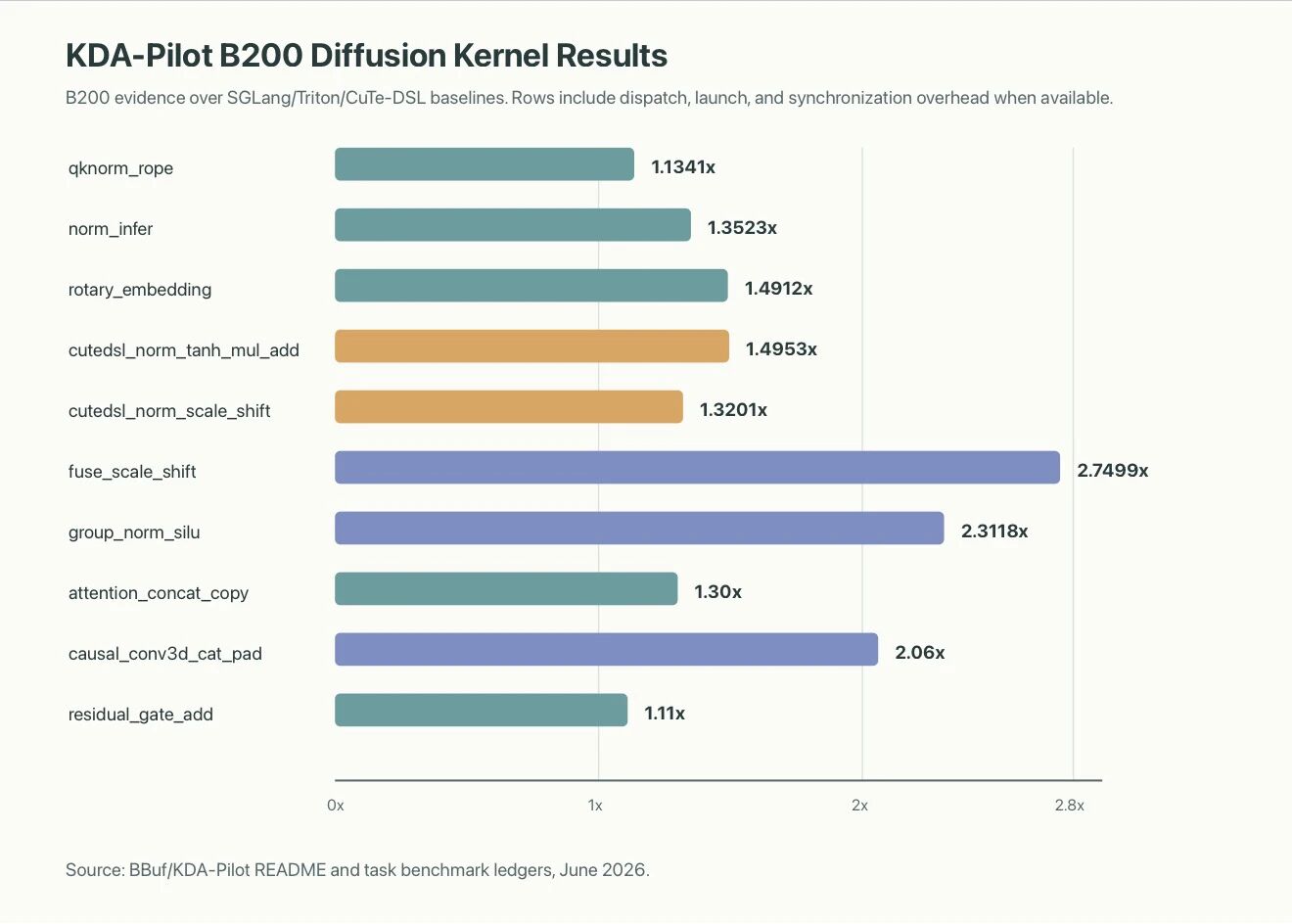
KDA-Pilot:CUDA Kernel 优化的工业化
Kernel 优化有更残酷的 scaling 问题——没有独立于硬件和 workload 的最佳 kernel。同一个算子,H100、H200、B200、B300 上偏好不同实现。搜索空间是硬件 × 模型 × workload 的笛卡尔积。
KDA-Pilot 把 kernel 优化拆成隔离任务,让 agent 不能随意修改整个 SGLang 仓库:workload 来自真实 SGLang 模型,baseline 从上游 main 复制,benchmark 使用固定生产行、A/B 交错,正确性覆盖 NaN/Inf 检查、poison 输出检查等。截至 2026 年 6 月 27 日,三个 KDA-Pilot 衍生的优化已合并上游:
- #27392:Qwen-Image norm-scale-shift,B200 上全请求加速 1.125x
- #29281:Cosmos3 causal Conv3D cat/pad,B200 加权 kernel 组从 10.6ms 降到 5.2ms(2.03x)
- #29361:LTX-2.3 residual-gate update,B200 上比 Triton 路径快 1.108x–1.130x
苏米注:SGLang 团队的这套做法最有价值的地方不在于"用 Agent 写代码",而在于"把经验变成可执行的工作流"。profile 分析的两步法、Loop Engineering 的六步流程、KDA-Pilot 的隔离验证——这些都是人类开发者的经验被系统化编码的结果。当这些经验变成 skill 后,新人可以快速上手,资深开发者可以把精力投入到更难的问题上。
几条实践规则
- 在启动 agent 之前定义任务边界。"优化 SGLang"太宽泛,"在 2x B200 上,固定 workload 下让 SGLang 匹配另一框架"才是可执行目标
- 在读 profile 之前固定 benchmark。如果 workload 可以在看到结果后改变,agent 可能意外优化了一个更简单的问题
- 根据 kernel 的计算特性解释 NCU 结果。内存受限 kernel 关注 DRAM/L2 吞吐,计算受限 GEMM 关注 Tensor Core 利用率,延迟受限 kernel 关注 launch 次数
- 在信任 profile 之前检查后端和 fallback。如果 LLM 运行静默切换 attention 后端、禁用 CUDA graph,trace 就不再描述目标 serving 路径
- Review 比以前更重要。Agent 可以创建更多 PR,也能制造更多看似合理的错误。高性能系统的 review 需要检查 shape、dtype、分布式执行、CUDA graph 行为、fallback、精度
Agent 时代的开发不会把开发者从系统中移除。更现实的变化是:把开发经验写进工作流,把重复执行交给 agent,把判断、设计、review 留给人类。