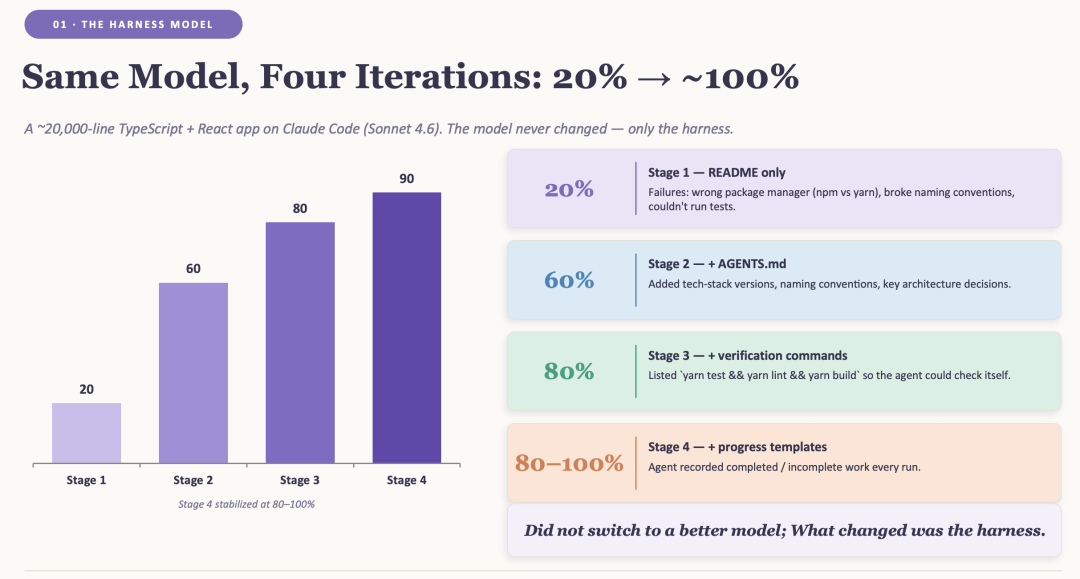
在 AI Agent 开发中,我们常常把注意力集中在模型能力上——更大的参数、更好的推理、更长的上下文。但一个被忽视的事实是:当模型能力达到一定阈值后,真正的瓶颈变成了 harness,也就是你围绕模型构建的一切基础设施。

这篇文章将展示一种用纯 Markdown 文件构建可读、可验证仓库的方法。不需要 fork 任何 coding-agent framework,不需要做代码级编排,也不需要触碰 Claude 或 Codex 的内部机制。任何人今天就可以把这些文件放进自己的 repo,并立刻感受到差异。
Harness 的五个子系统
做过足够多的 Agent 项目后,harness 可以拆解为五个相互连接的子系统。缺少任何一个,Agent 用起来都会显得别扭——就像一辆车少了仪表盘或刹车。
Instruction(指令层)——一个入口页(AGENTS.md 或 CLAUDE.md),包含项目概览、技术栈及版本、首先要运行的命令,以及少数绝不能违反的硬性规则。
Tools(工具层)——足够的访问权限,让 Agent 能真正完成工作。出于"安全"考虑禁用 shell,导致 Agent 连 pip install 都不能运行,就像雇了一名工程师却没收了他的键盘。原则是 least privilege,而不是 no privilege。
Environment(环境层)——一个能自我描述的环境:锁定的依赖、固定的 runtime 版本、可复现的容器。Agent 如果在和破损环境搏斗,就会把注意力浪费在错误的战场上。
State(状态层)——一个记录已完成、进行中和被阻塞事项的地方,让工作可以跨 session 存续。
Feedback(反馈层)——明确的命令,用来告诉 Agent 它的工作是否真的正确。

如果只能给一个 repo 添加其中一个子系统,每次都会选择 Feedback。它是 ROI 最高的子系统——投入最低,回报最大,因为它决定了 Agent 是在猜测自己完成了任务,还是能够检查自己完成了任务。
OpenAI 和 Anthropic 两家实验室都收敛到了相同的结论。OpenAI 将工程师的工作浓缩为三件事:designing environments, expressing intent, building feedback loops。Anthropic 甚至直接把他们的 Claude Agent SDK 称为 "general-purpose agent harness"。
苏米注:在实际项目中,我发现最容易被忽略的就是 Feedback 层。很多团队花大量时间调 prompt,却忘了给 Agent 一个简单的验证命令。加上
pytest tests/ -x或make check,往往比调十次 prompt 更有效。
Verification Commands:回报最高的十分钟投入
在任何 repo 的入口文件中加入 verification block,是回报最高的一件事:
# Verification Commands (MUST Adapt to your app / project)
- Tests: pytest tests/ -x
- Type check: mypy src/ --strict
- Lint: ruff check src/
- Full check: make check # runs all of the above
把所有验证逻辑通过 make targets 路由,Agent 就永远不需要猜测项目使用的是 npm、yarn、poetry 还是 pipenv——harness 提供了一个统一入口。
Repository 就是 Specification
如果把整篇文章压缩成一句话,那就是:如果它不在 repository 里,那么对 Agent 来说它就不存在。
一个处在非结构化 repository 中的 AI Agent,就像一个没有任何 onboarding 的天才新人:它把精力浪费在弄清自己身处何处上。但如果你给它一张清晰的地图——一个入口路由器、与代码共置的文档,以及精确的 verification commands——同一个模型就会从 20% 的成功率跃升到接近完美。
真实项目中,大量知识存在于 repo 之外——Slack 线程里、过时的 Confluence 页面里、零散的代码注释里,更多时候存在于两三个资深人员的脑子里。所有这些对 Agent 都是不可见的。每一个缺口都会迫使它猜测。
苏米注:一个团队的案例显示,70% 的 Agent 任务需要人工救援,几乎每一次失败都是因为 Agent 违反了某条大家都知道、但没人写下来的隐性规则。把隐性知识显性化,是 Harness Engineering 的核心价值。
因此,对任何项目都可以做一个简单的测试:打开一个全新的 Agent session,除了 repository 什么都不给,然后问五个问题:
- 这个系统是什么?→ README.md + AGENTS.md(或 CLAUDE.md)
- 它是如何组织的?→ 每个 module 下的 ARCHITECTURE.md
- 我如何运行它?→ Makefile / init.sh / package scripts
- 我如何验证它?→ test、lint、check commands(在 AGENTS.md 中)
- 我们现在进展到哪里了?→ PROGRESS.md / feature_list.md / git history

如果 Agent 仅凭文件就能回答全部五个问题,它就可以在无人值守的情况下开始真正工作。如果有一个问题回答不了,那就是地图上的空白区域——而地图空白的地方,Agent 就会猜。错误的猜测会变成 bug,过度猜测会消耗 Agent 有限的注意力。
如何画出一张面向 Agent 的好地图
通过 fresh-session test 并不是要写更多文档,而是要在正确的位置写正确的文档。四条原则可以覆盖大部分场景:
1. Discovery Cost(发现成本)
Agent 的注意力预算中,仅仅用于寻找某个关键事实的那一部分。把某个东西埋在十层目录深处,Agent 每个 session 都要为此消耗 context。把它放在第一眼就能看到的位置,成本就会显著下降。
2. Knowledge Decay(知识衰减)
文档在单位时间内变得陈旧的比例。这是安静的杀手:
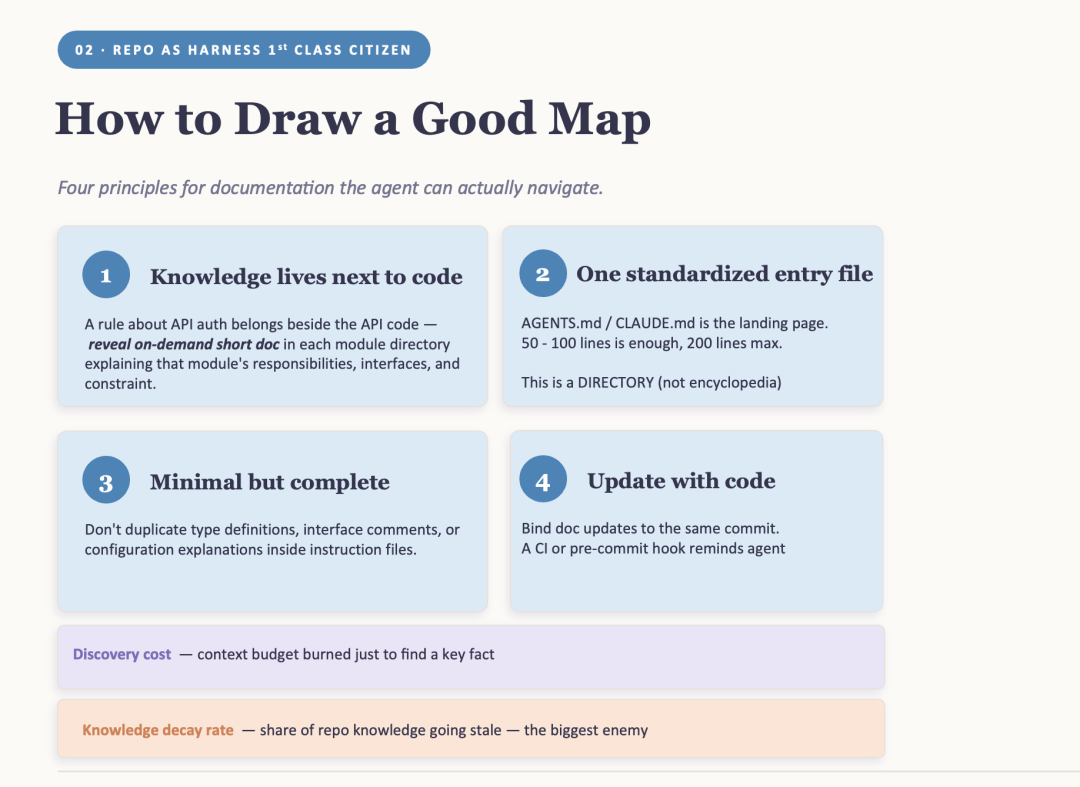
知识要和代码放在一起。关于 API authentication 的规则应该放在 API 代码旁边,而不是埋在一个 4,000 行的全局文档中。目录本身就成为索引——当 Agent 到达代码时,它也到达了约束条件,无需搜索。
3. 一个标准化入口文件
AGENTS.md 或 CLAUDE.md 是 landing page,不是百科全书。50–100 行就足够,200 行是上限。它唯一的职责,是让 Agent 回答这是什么、如何运行、如何验证——并指向其他所有内容。
4. 最少但完整
如果删掉一条规则不会改变 Agent 做出的任何一个决定,那这条规则就不应该存在。但每个 fresh-session question 仍然必须有答案。不要在 instruction files 中重复类型定义、interface 注释或配置说明。
5. 随代码一起更新
将文档变更和代码变更绑定在同一个 commit 中。过时的文档比没有文档更糟糕——缺失的文档会让 Agent 提问,陈旧的文档会让它自信地走错方向。
Agent State 的 ACID 原则

把 Agent state 当作数据库事务来处理:
- Atomicity(原子性):一个逻辑变更 = 一个 commit;如果中途出问题,就 git stash 并回滚,不留下半成品状态。
- Consistency(一致性):每次操作后都运行 verification,永远不要 commit 一个破损的中间状态。
- Isolation(隔离性):并发 Agent 使用独立 branches 或 progress files,避免相互覆盖。针对每个 feature 的开发,要求使用 git worktree。只有在 feature 完全测试通过后,才 merge 回工作 branch 或 main。
- Durability(持久性):任何必须跨 session 保留下来的东西,都要进入 git-tracked files。Chat history 里的内容不算数——只有写下来的内容才算数。要求 Agent 将 plan、todo、thinking 导出到本地 markdown files。
为什么一个巨大的 Instruction File 会失败
最初接受"把所有东西放进 single source of truth"这个想法时,很多人会把一切塞进 AGENTS.md——deployment runbooks、edge-case histories、能想到的每一条规则。它膨胀到超过一千行,然后 Agent 反而变得更差。
常见错误:把 AGENTS.md 或 CLAUDE.md 当成百科全书,而不是路由器。
它会适得其反,可以分为三点:
Signal-to-noise 崩塌。在修一个一行 bug 时,强迫 Agent 读 50 行 deployment 琐事,会把相关 instruction 淹没在噪声中。低 signal-to-noise ratio 和缺失信息一样致命。
"Lost in the middle" 效应。Language models 往往会最关注长文档的开头和结尾,而略读中间部分。把一条不可协商的约束埋在第 40 段,它几乎就等于不存在。如果一条规则真的关键,它就应该放在最顶部或最底部——绝不要放在中间。
Agent 无法判断什么重要。当硬性约束和软性建议在同一个位置使用同样的格式时,Agent 无法区分 "MUST NOT" 和 "you might consider"。
解决方法是把 AGENTS.md 和 CLAUDE.md 当作路由器,而不是手册——"按需展示",就像优秀 UI 设计一样。先给 overview,细节只隔一次点击,需要时再读。
# AGENTS.md
## Run it
- make setup && make test
## Hard constraints (non-negotiable)
- Always use parameterized queries for DB access.
- All component files use PascalCase.
## Where to look (read on demand)
- API request/response patterns → docs/api-patterns.md
- Database rules & migrations → docs/database-rules.md
- Auth & session model → src/auth/ARCHITECTURE.md
苏米注:要像对待 technical debt 一样对待 instruction debt。你添加的每一条规则都应该说明它为什么存在,以及什么时候可以删除。没有 expiry condition 的规则会变成永久噪声。
目标不是提供最多 context,而是提供最少但仍能回答每个 fresh-session question 的 context。约束它,不要微观管理它。强制执行 invariants,让 Agent 自己搞清楚实现。
Prompt Caching:好地图也能省钱
模型会复用对话中稳定的 prefix——system prompt、project map、早期读取的文件——通过缓存提供,而不是重新计算。一个读取同一组 canonical files 的新 session,会复用这个 warm prefix。

效果是双向的:每一次交互都会降低 latency 并降低 cost。但 cache 的 key 依赖于这个 prefix 不发生变化。只要早期内容发生任何编辑——system prompt、entry file,甚至是你读取文件的顺序——都会使其后的所有缓存失效,并需要支付全价重新计算。
最佳实践:把稳定的地图放在前面并保持不变;把易变内容(progress file、live task state)放到最后。一个整洁、稳定的 repository map 不仅是良好的工程实践,还会悄悄为自己省钱。
核心结论
一个能力很强的 Agent 在空白 repository 中的表现,和一个没有 onboarding 的天才新人完全一样:它把精力花在弄清东西在哪里,而不是完成工作。
给它一张地图——一个用于路由的短入口文件、与其所描述代码共置的知识,以及能证明工作结果的精确命令——你已经拥有的同一个模型,就会悄然从五次成功一次提升到几乎每次成功。
修复 workspace。Repository 就是 specification——如果它不在 repo 里,它就不存在。