美团发布了 LongCat-2.0,一个总参数 1.6 万亿(激活约 480 亿参数)的 MoE 模型。值得瞩目的是,该模型从预训练到大规模部署,全程跑在 5 万张国产算力芯片上,耗时一个多月,处理超过 35 万亿 tokens,全程无回滚且无不可恢复的 loss 突刺。
这一成果的意义不仅在于性能,更在于它完整跑通了基于国产算力的大模型全链路。对于经常面临海外模型封号或限流风险的用户来说,LongCat-2.0 提供了一个开源、可 API 接入、能直接集成到 Claude Code 或 Codex 等工作流的国产替代方案。

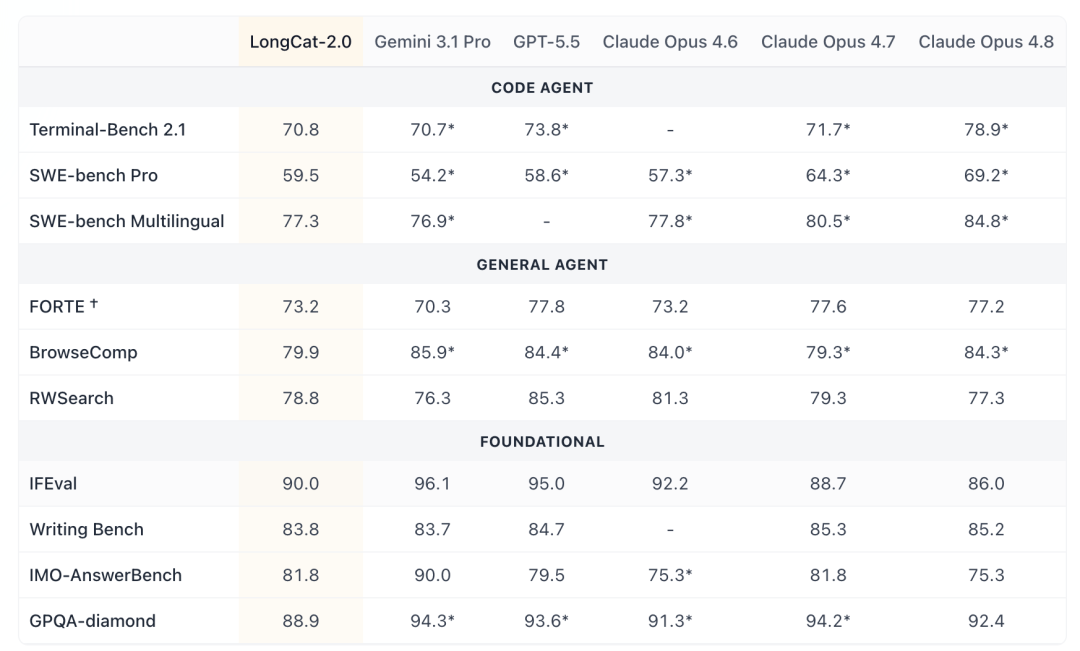
虽然 LongCat-2.0 并非全面 SOTA(在 IFEval、GPQA-diamond 等通用能力上与 Gemini 3.1 Pro、GPT-5.5 仍有差距),但在 Agent 场景下表现突出:
- 编程任务:在 Terminal-Bench 2.1 和 SWE-bench Pro 上基本追平 Gemini 3.1 Pro。
- 通用 Agent:在 FORTE 任务上与 Claude Opus 4.6 表现相当。
- 上下文支持:最大输出 128K,最高提供 1M 上下文。
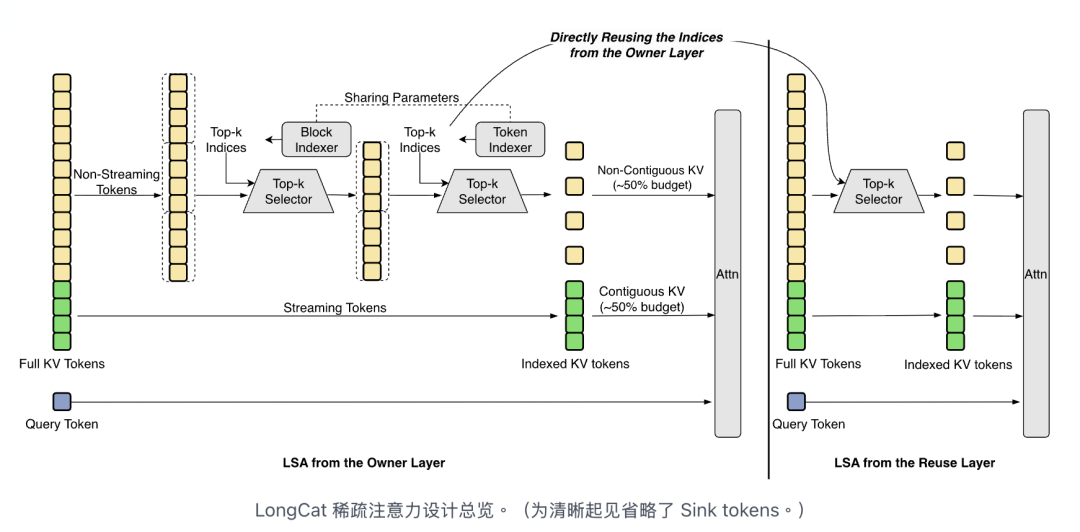
核心技术:LSA 与 N-gram Embedding
为了让模型在长上下文和工具调用中保持稳定,LongCat-2.0 引入了两项关键技术:
1. LSA 稀疏注意力机制
面对超长输入时,模型不再逐字硬啃。LSA 使模型能够更有效地处理代码库阅读、文档翻阅和多步骤操作,解决 Agent 长上下文记忆和工具调用的稳定性问题。
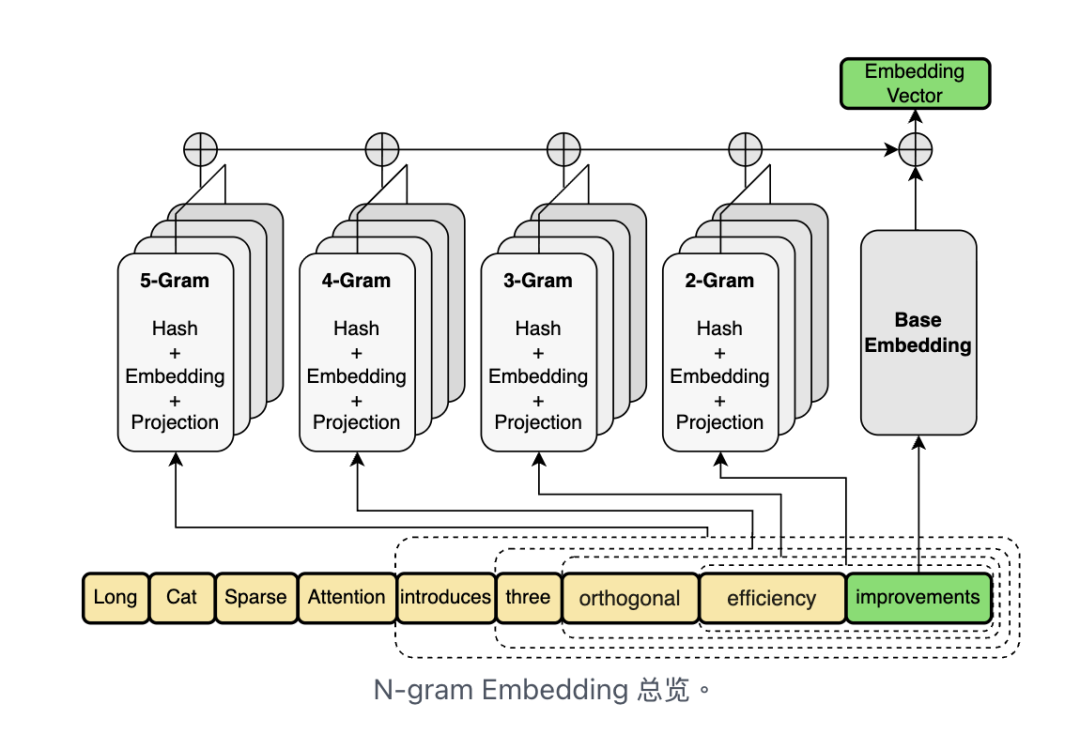
2. N-gram Embedding
模型不再只关注单个 token,而是对词组组合的语义更敏感,提升了对局部语境的理解能力。
如何接入 LongCat-2.0
LongCat-2.0 兼容 OpenAI 和 Anthropic API 生态。只需更换 base_url 和 API key 即可接入现有工作流。
OpenAI 兼容接口:
base_url="https://api.longcat.chat/openai"
model="LongCat-2.0"
api_key=LONGCAT_API_KEYAnthropic 兼容接口:
base_url="https://api.longcat.chat/anthropic"
model="LongCat-2.0"
实测:接入 Claude Code
将 LongCat-2.0 接入 Claude Code,测试其对杂乱工作文件夹的整理能力。模型首先读取目录结构,区分代码、文档、素材和测试文件,然后给出不破坏项目引用和运行逻辑的重组方案。

执行过程中,模型会先拆解整理原则,分阶段处理问题:先理解项目结构,再判断文件用途,最后结合多维度分析将文件夹还原为清晰的工作系统。



实测:接入 Codex 跑 Agent 工作流
测试场景:联网搜资料 → 整理大纲 → 调用 Skill → 生成演示文稿。
LongCat-2.0 首先联网搜索官方文档,确认模型特点和适用结构,然后检查当前环境中的 Skills 能力。完成资料收集和工具盘点后,再进行整体规划并生成文稿内容。






生成的 PPT 内容连贯一致,从背景介绍到核心能力、测试过程和结论,没有出现典型的 AI 生成排版问题。
总结
LongCat-2.0 最值得关注的价值在于:它是一个全程国产算力训练出来的万亿模型,直接落地到了开发者可用的位置。在当前海外模型频繁封号的背景下,看到国产模型能够开源、API 接入、接入真实工作流,无疑是一个积极的信号。
虽然基础能力离顶级闭源模型仍有差距,但至少在关键时刻,我们有了一个新的选择。