智谱 AI 近日正式开源 GLM-5.2,同步发布技术博客。该模型基于 744B MoE 架构(40B 激活),支持 1M 上下文,采用 MIT 协议开源。API 已全量上线,价格与 5.1 保持一致。
这不仅仅是一个“又多了一个开源模型”的发布,更标志着开源阵营在 Agent 长任务和 1M 上下文能力上正在从“能用”向“够打”逼近。
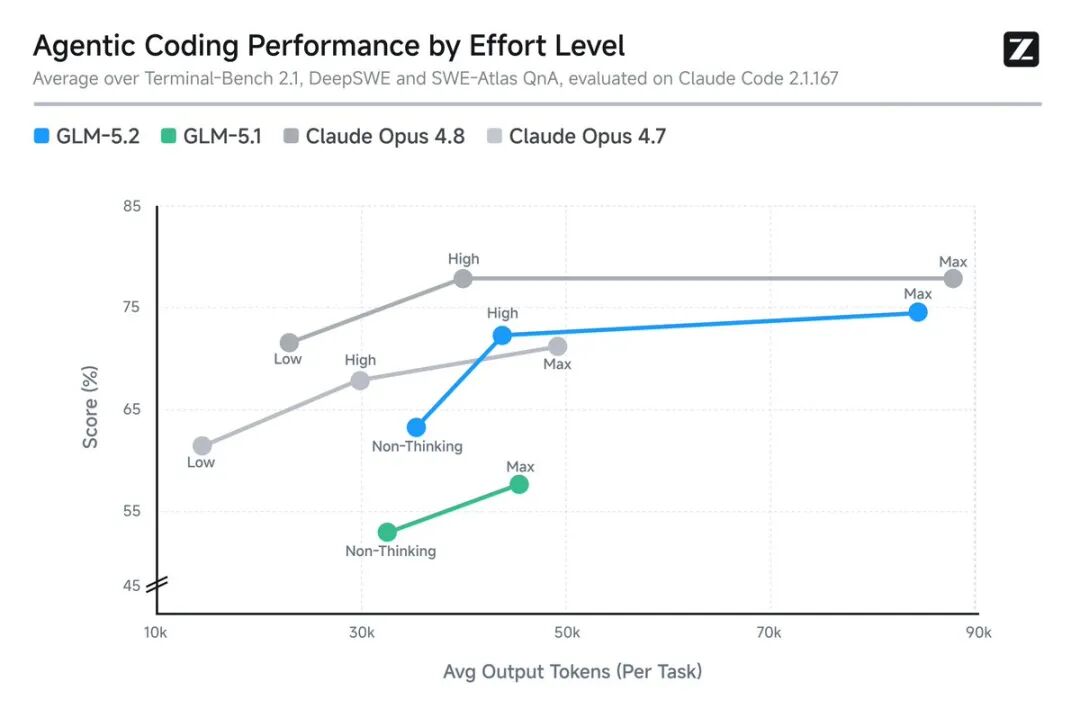
1M 上下文:工程化的突破
GLM-5.2 的目标不仅仅是短问短答的聪明,而是在更长、更复杂、更接近真实工程项目的任务中保持稳定。官方在官方博客中指出,长上下文要变成工程上可用的能力,模型必须在“长、乱、持续执行”的 coding-agent 轨迹里保持质量。
训练重点落在大规模实现、自动化研究、性能优化、复杂调试等真实工作流上。模型需要读仓库、看报错、写代码、跑命令、再根据反馈继续修。
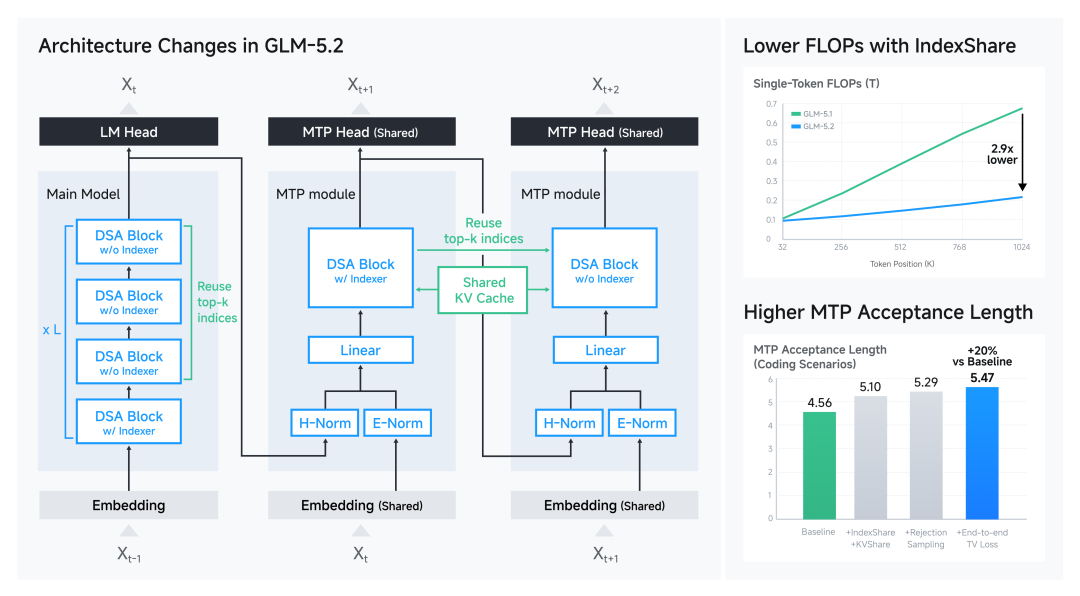
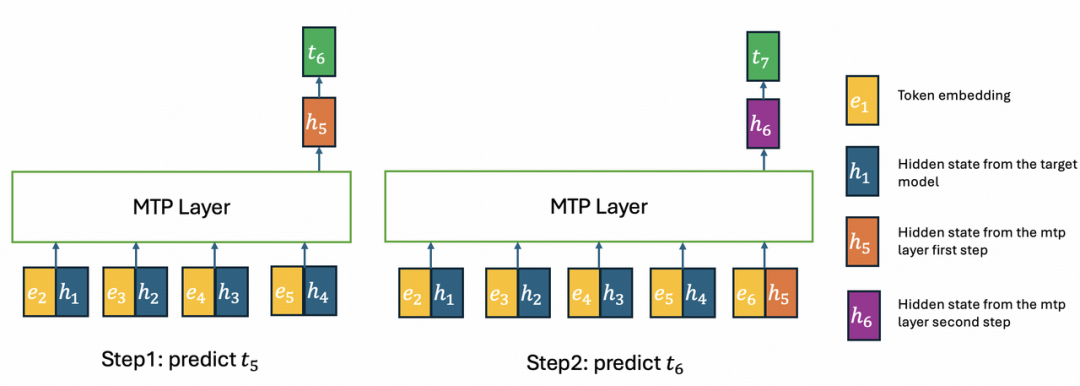
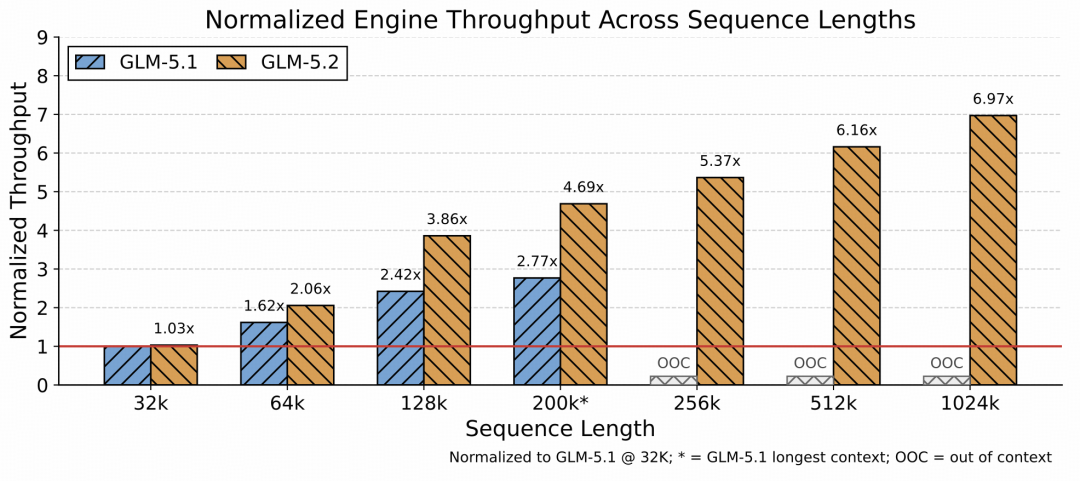
架构优化:让长窗口更经济
为了支撑 1M 上下文,GLM-5.2 在架构上进行了创新:
- IndexShare:每 4 个稀疏注意力层之间共享一个轻量 indexer。在 1M context 长度下,这会将每 token 的 FLOPs 降低 2.9 倍。
- MTP 改进:进一步提升推理效率。
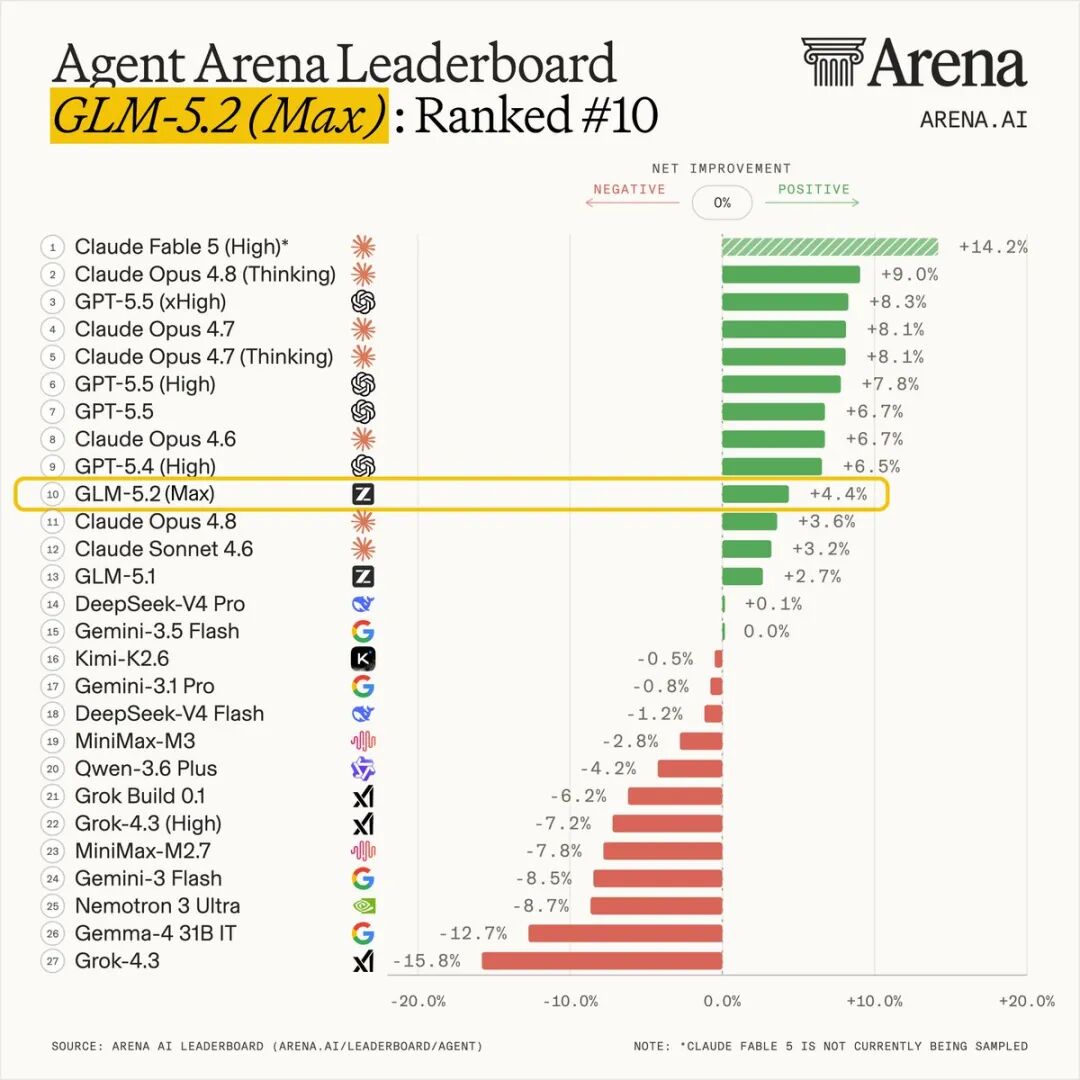
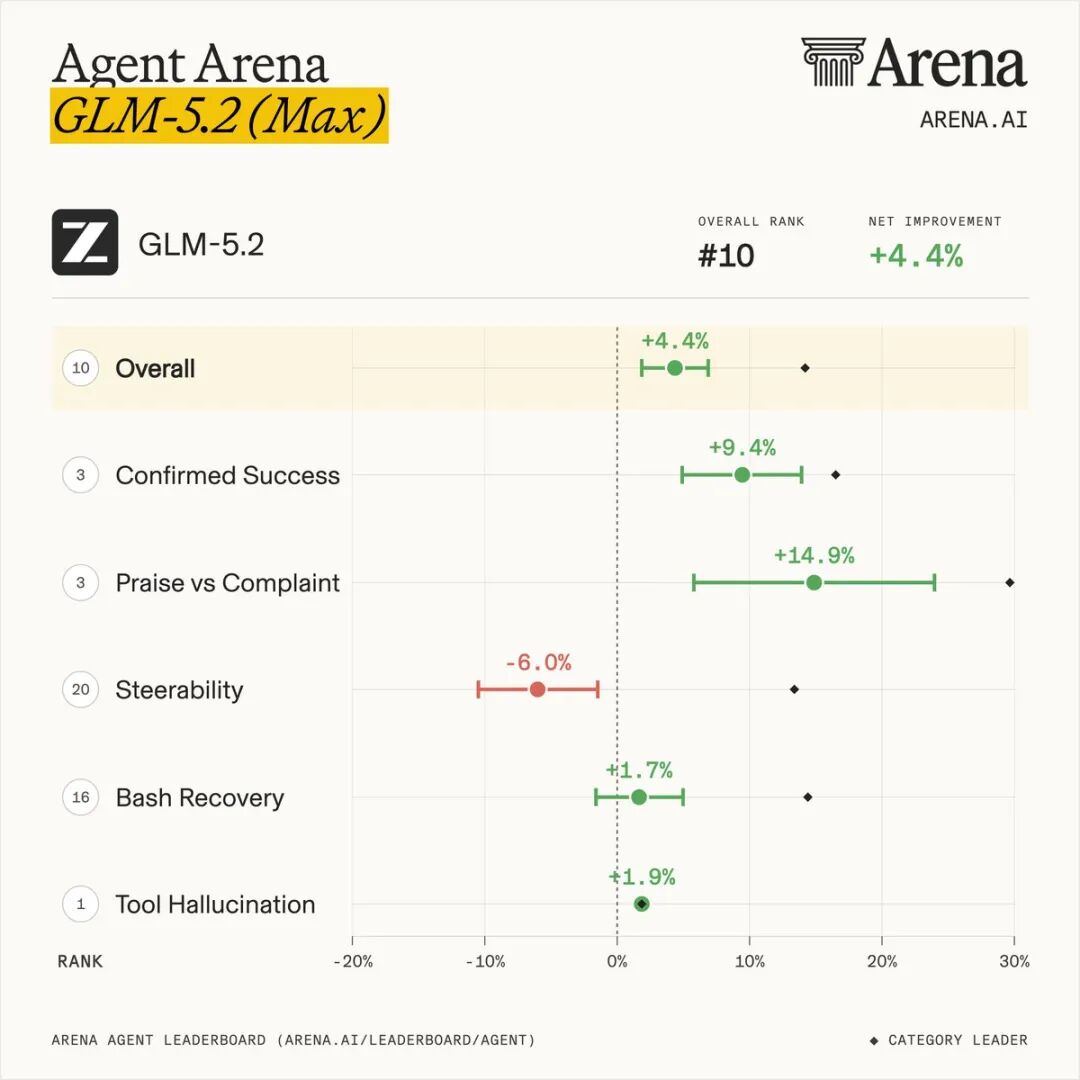
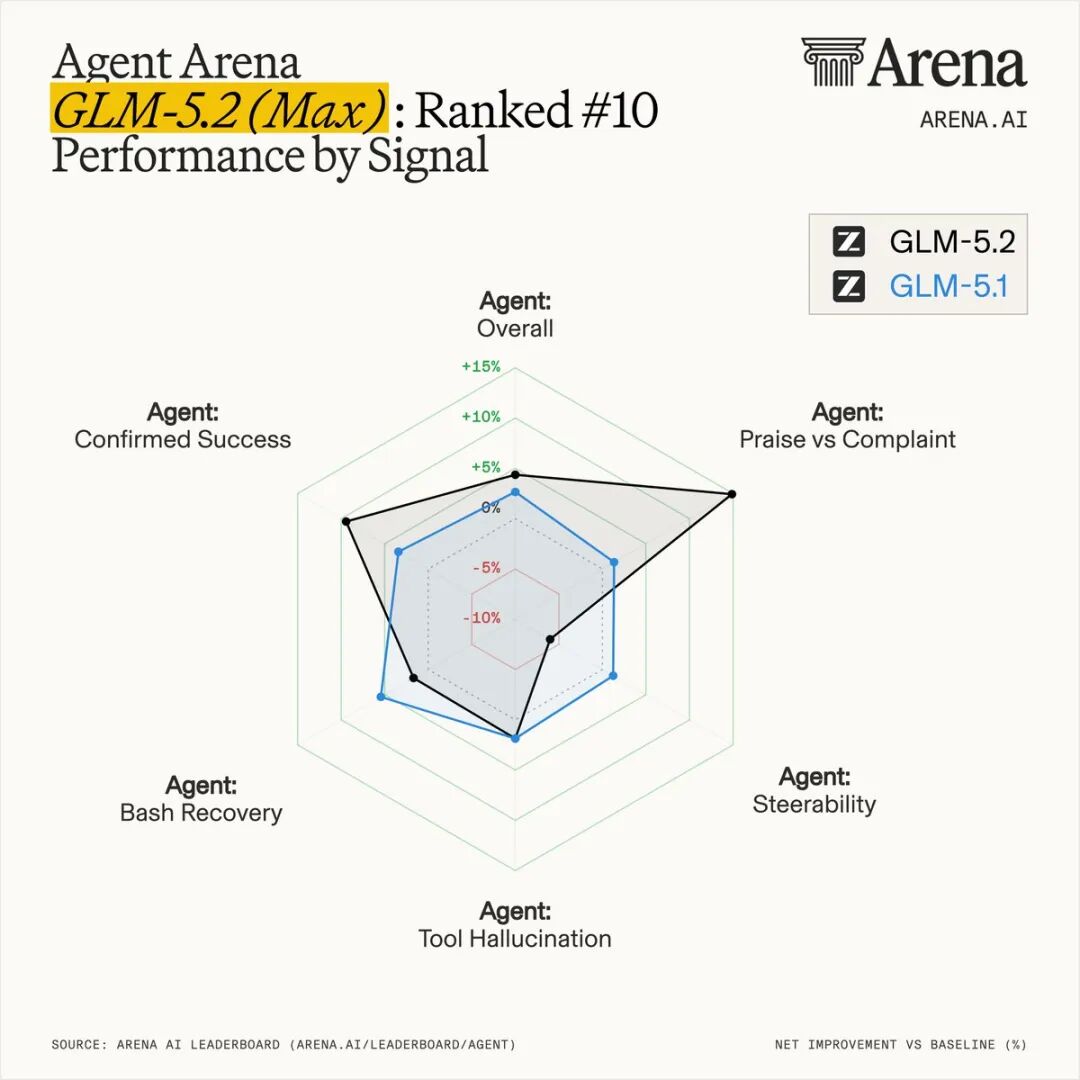
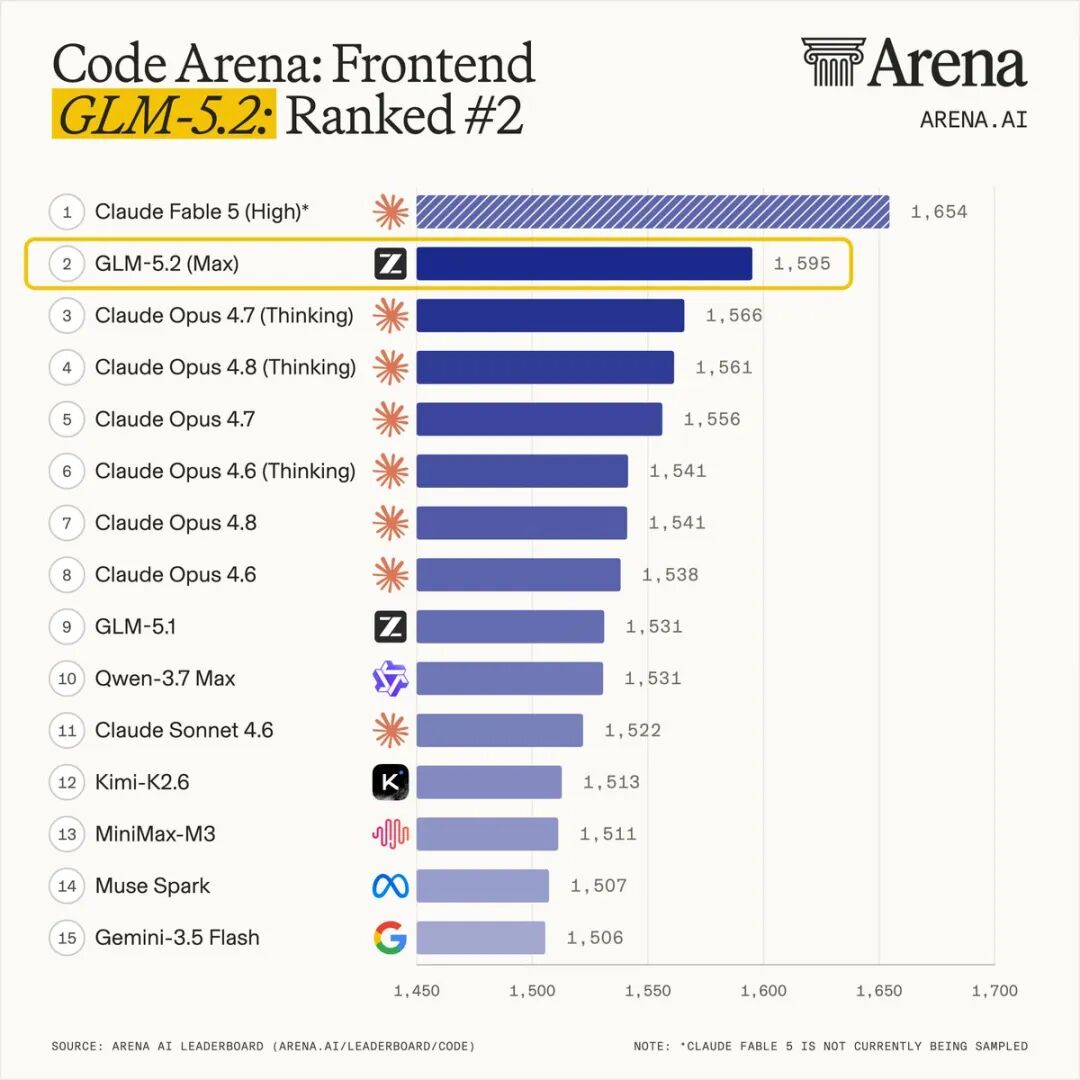
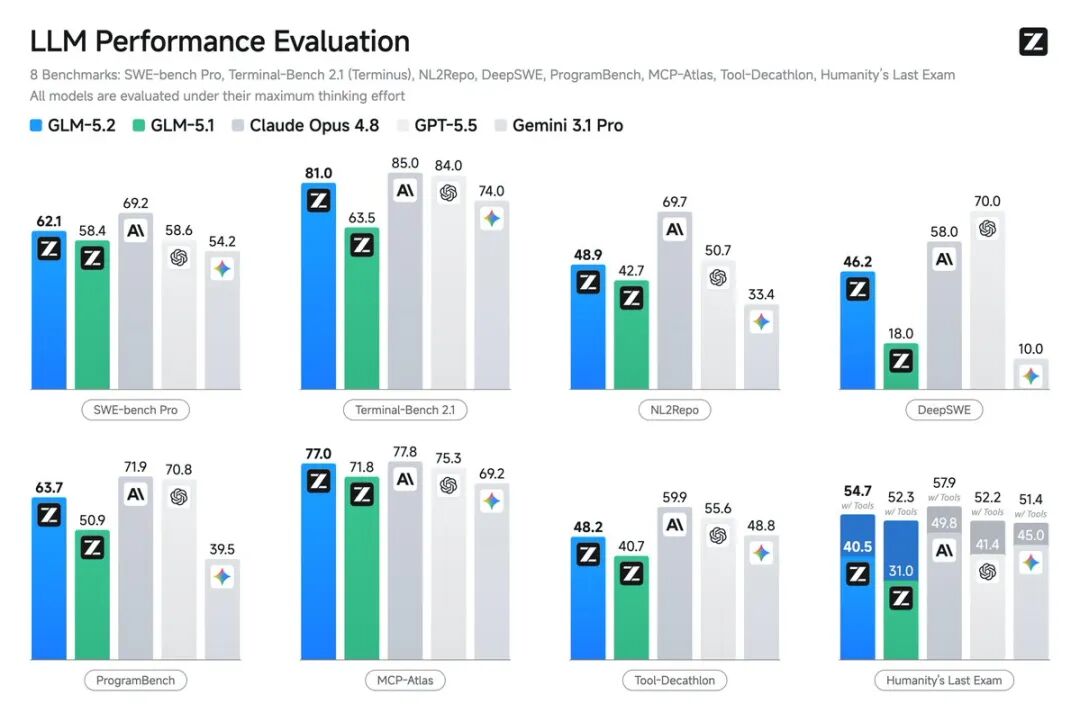
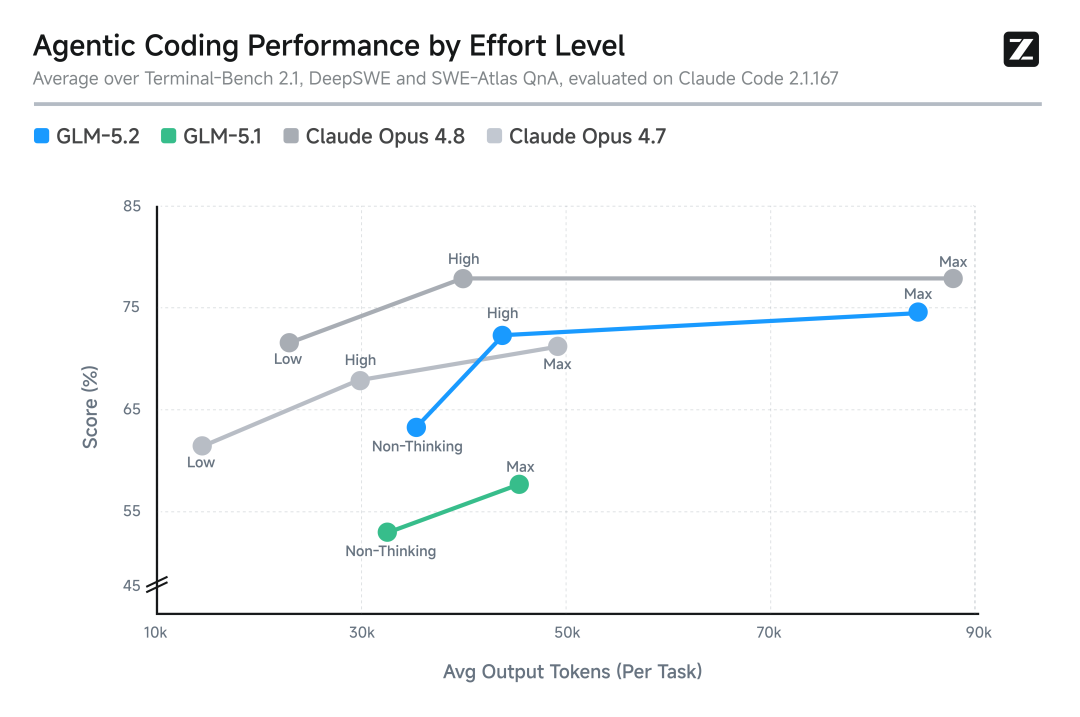
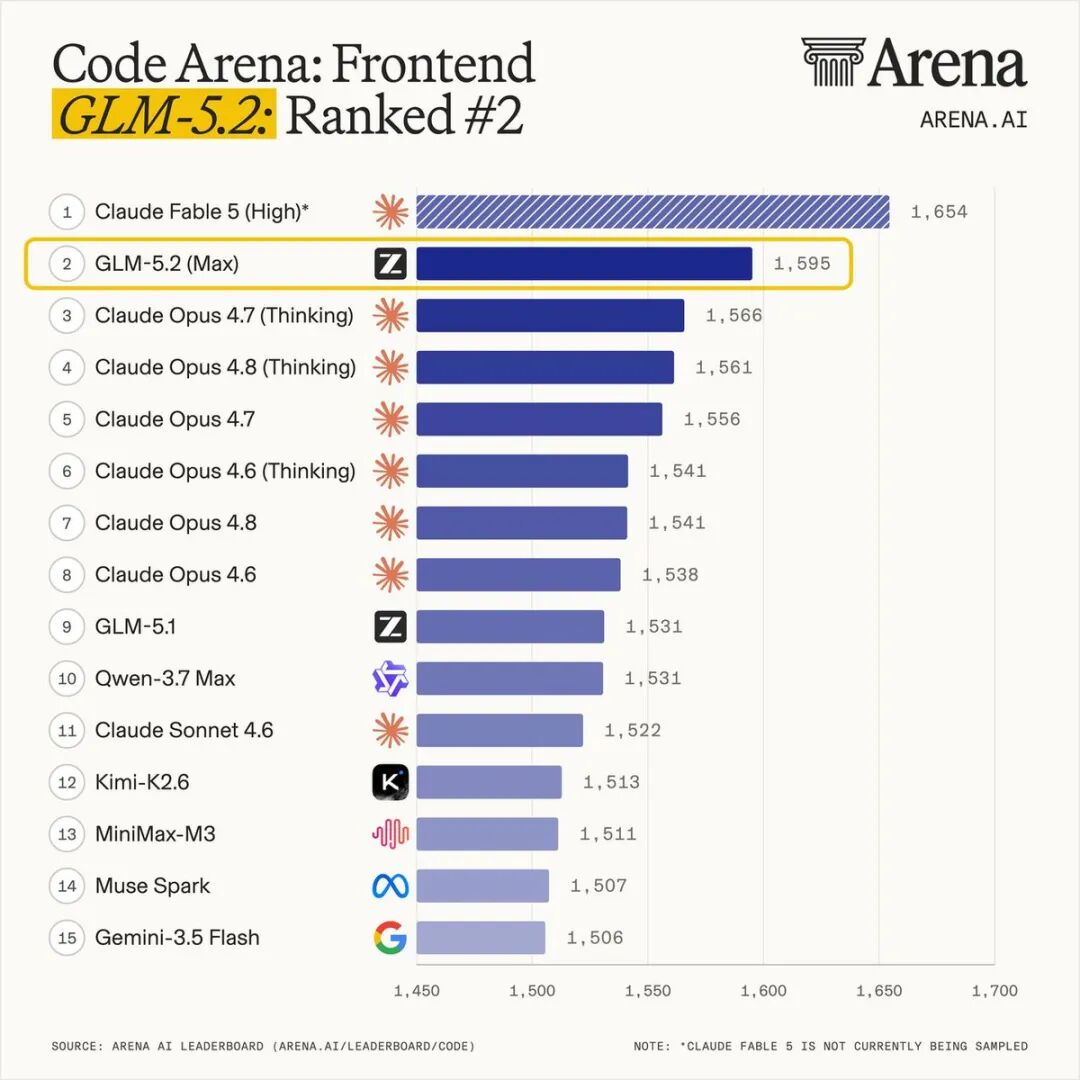
Coding 与 Agent 能力
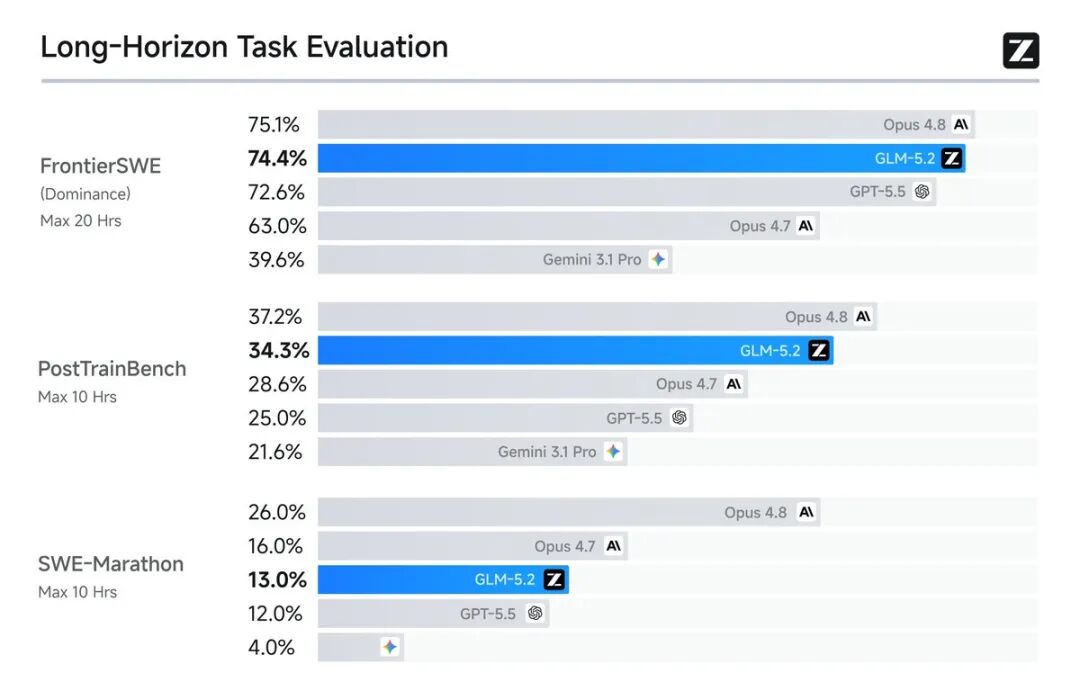
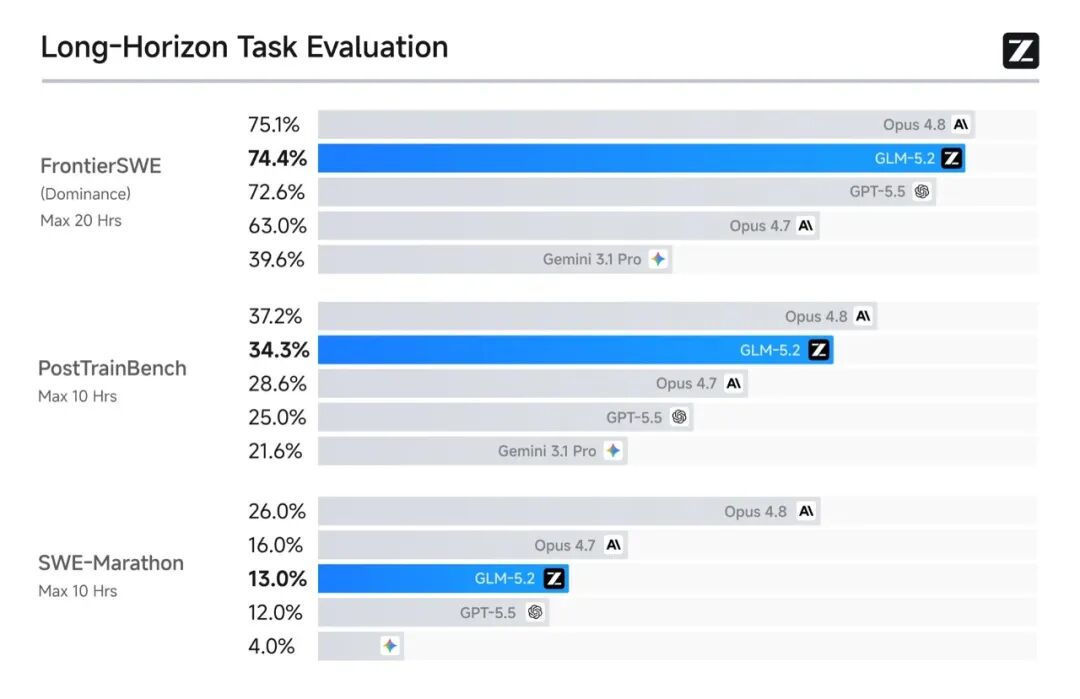
在 Coding 领域,GLM-5.2 的表现同样亮眼:
- FrontierSWE:与 Claude Opus 4.8 差距仅 1 个百分点,高于 GPT-5.5 和 Opus 4.7。
- PostTrainBench:仅次于 Opus 4.8,超过 Opus 4.7 和 GPT-5.5。
- SWE-Marathon:排在 Opus 系列之后,但表现稳健。
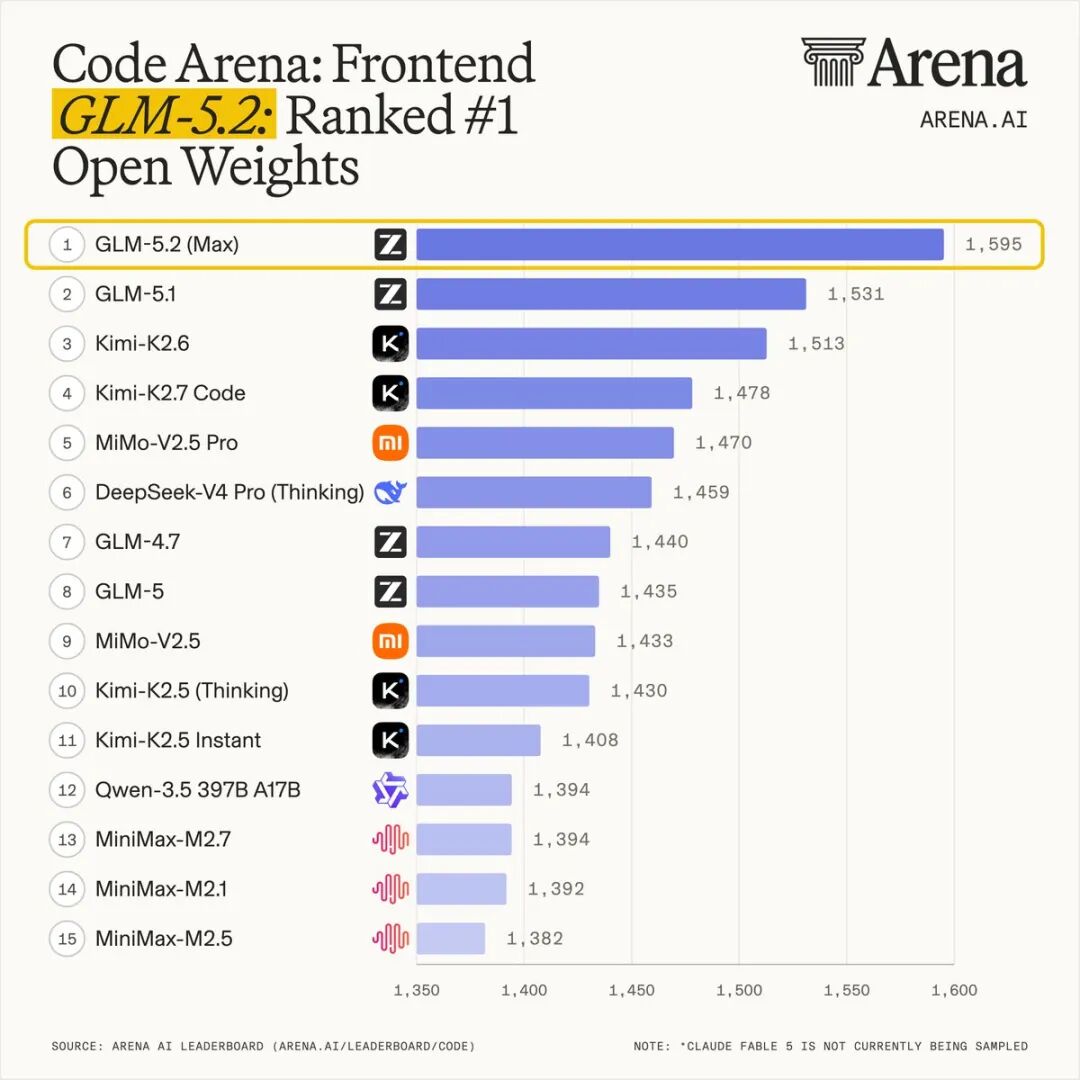
总结
GLM-5.2 的发布不仅仅是参数的提升,更是开源模型在复杂任务处理能力上的一次重要跨越。它踩在了“够不够强、够不够便宜、能不能自己部署、长上下文会不会掉链子”这四个开发者核心关切的交叉点上。
苏米注:GLM-5.2 在 IndexShare 等架构上的优化,直接降低了 1M 上下文的推理成本。对于需要处理超长文档或复杂代码库的开发者来说,这是一个性价比极高的选择。
声明:本站原创文章文字版权归本站所有,转载务必注明作者和出处;本站转载文章仅仅代表原作者观点,不代表本站立场,图文版权归原作者所有。如有侵权,请联系我们删除。
未经允许不得转载:GLM-5.2 开源:1M 上下文、744B MoE 与工程化突破