你花了三周上线一个 Agent。Demo 里一切正常。然后一到生产环境,你才发现自己选的 framework 没有 checkpointing,memory layer 只是一个扁平的 vector dump、没有 temporal reasoning,browser tool 遇到任何带 canvas element 的网站就崩,而 eval suite 只是一个总有人忘记更新的 Notion doc。
到 2026 年,用于构建 agents 的 open-source toolkit 已经解决了大部分这类问题。问题在于:每个问题都被以十几种互不兼容的方式解决了。赢下 LoCoMo(标准 long-conversation memory benchmark)的 memory framework,每段 conversation 的开销比第二名重 340 倍,而这个差异不会出现在任何 benchmark 表格列里。Benchmark 分数与 production behavior 之间的同样落差,会出现在每一层。
所以,最好的方式是先判断你的 system 在负载下最先撞上的 constraint:latency budget、audit trail、model portability,还是 language stack。判断错了,你会在第三周重写 state schemas。
本文是 The AI Agents Stack (2026 Edition) 的 open-source 版本,围绕 think-act-observe loop 的七层展开:orchestration、memory、tool interface、browser/CUA、coding agents、evals & observability,以及 inference。下面是每一层的入门选择。

如何在每一层做选择
选择每一层的工具时,问三个问题:
- 主导 constraint 是什么? 四类 constraints 决定了大多数 layer picks。Latency budget 是你每一轮可以花多少 tokens 或 milliseconds。Audit trail 是每个 action 是否都必须可追踪以满足 compliance。Model portability 是你的 stack 与某个 provider 绑定得有多深。Language stack 是你的团队使用 Python、TypeScript,还是两者都用。通常每一层都会有一个 constraint 占主导。
- 如果选错,rip-out cost 有多高? 替换一个 MCP server 可能只改一行 config。替换 orchestration 则意味着重写 state schemas、nodes 和 edges。Rewrite 越大,越应该优先按 constraint 来选。
- 它是 open-source 还是 open-core? Open-core 意味着项目以 open-source license 发布,但 production features(multi-tenant auth、replication、SSO、audit logs)只在 managed cloud product 中可用。
Layer 1: Orchestration & Runtime Control
Orchestration layer 负责运行 agent 的 reasoning cycle。LLM 选择一个 action,runtime 执行它,runtime 观察结果,LLM 再次选择。如果这一层跳过 framework,你就得自己写 loop,也就意味着在上线前重新发明 retries、checkpointing 和 human-in-the-loop gating。
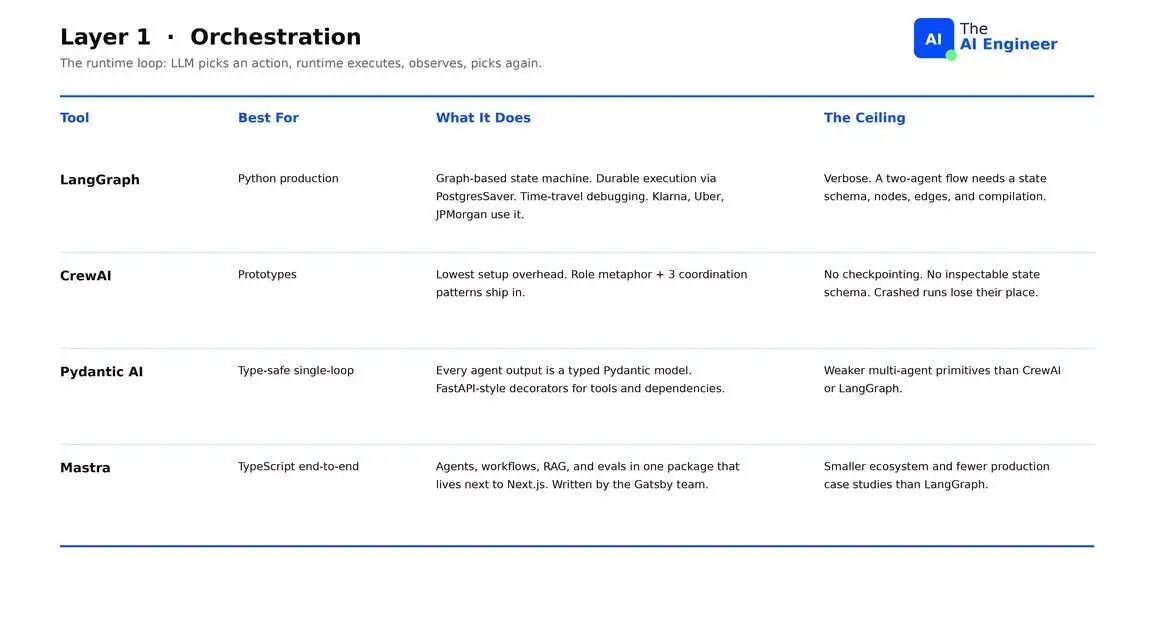
- LangGraph:Python production work 的默认选择。Graph-based state machine,支持通过 PostgresSaver 实现 durable execution、time-travel debugging。拥有该领域最大的 verified enterprise list(Klarna、Uber、LinkedIn、JPMorgan、Replit)。缺点:很 verbose,一个 two-agent flow 仍然需要 state schema、nodes、edges 和 compilation。
- CrewAI:四个 orchestration frameworks 中 setup overhead 最低的。声明 roles,选择 coordination pattern,然后运行 crew,不需要先定义 state schema。缺点:以牺牲 production durability 为代价来优化 prototype velocity,不能从 crashed runs 的失败点恢复。
- Pydantic AI:将每个 agent output 都视为 typed Pydantic model,validation、retries 和 downstream serialization 都是内建的。缺点:multi-agent primitives 较弱,最适合 single loop 场景。
- Mastra:TypeScript 的答案。Agents、workflows、RAG 和 evals 集成在一个 package 中,设计目标是直接嵌入现有 Next.js apps。缺点:ecosystem 较小。
Vendor SDKs(Claude Agent SDK、OpenAI Agents SDK、Google ADK)也属于这一层。每个 SDK 都降低了 orchestration friction,同时把 agent 锁定到某个 provider 的 API。
Layer 2: Memory & State
Context window 不是 memory。即使有 200K tokens,每一轮仍然要为整段 conversation 再付一次成本,而且 session 结束后什么都不会保留。2026 年的 production agents 会把 memory 放在 prompt 之外的 dedicated layer 中。
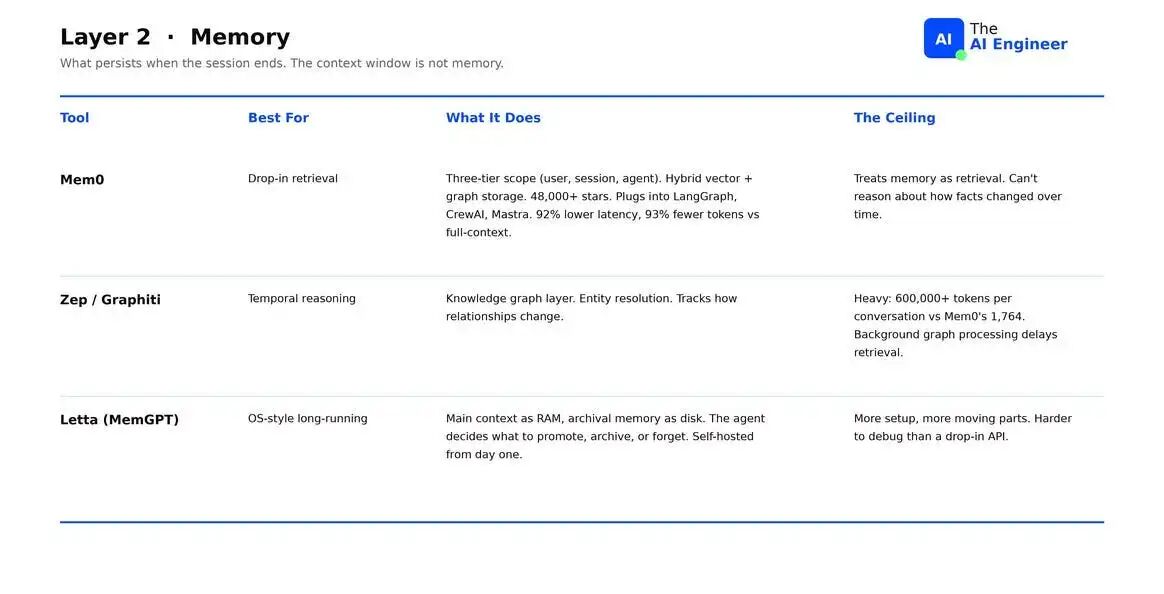
- Mem0:Memory 可 scoped 到 user、session 或 agent。Hybrid storage 结合 vectors 和 graph。ECAI 2025 paper 报告称相较 naive full-context,Mem0 latency 降低 92%,tokens 减少 93%。缺点:将 memory 视为 retrieval,Temporal reasoning 较弱。
- Zep / Graphiti:Temporal graph 选项。处理 entity resolution,跟踪 relationships 随时间的变化。缺点:graph construction 昂贵,每段 conversation 的 memory footprint 超过 600,000 tokens,immediate retrieval 经常失败。
- Letta(formerly MemGPT):像 operating system 一样处理 memory。Main context 是 RAM,archival memory 是 disk,agent 决定把什么提升到 RAM、归档到 disk。缺点:需要自己运行 storage layer,更难部署和 debug。
🏗️ Engineering Lesson: 在 agent system 中,「Memory」有两种不同含义。Runtime state 是 agent 执行 task 中途的 scratchpad(LangGraph 的 PostgresSaver 处理)。Knowledge memory 是 agent 跨 sessions 学到的内容(Mem0 和 Zep 存储)。混淆两者,你会得到一个能正确恢复 crashed run、但用户打开新 session 就把人忘了的 agent。
Layer 3: Protocols & Tools
到 2026 年,这一层是MCP(Model Context Protocol)。它是 Claude Agent SDK 使用的 open standard,OpenAI Agents SDK 原生支持它,Google ADK 与它集成。如果你今天在写 tools,你就是在写 MCP servers。
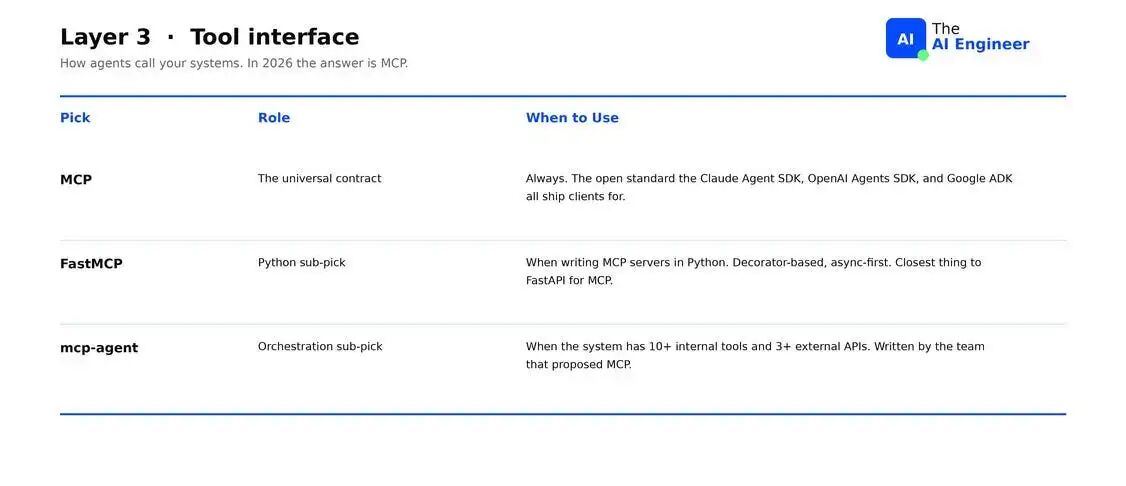
- FastMCP:用于快速编写 MCP servers 的 Python framework。Decorator-based、async-first,最接近 FastAPI for MCP。
- mcp-agent:围绕 MCP 作为 primary tool interface 构建的 orchestration framework。Server lifecycle、multi-server routing 和 prompt context handling 都是内建的。
Layer 4: Browsers & Computer Use
当 agent 需要操作的 system 没有暴露 API 时,toolkit 就必须通过 screens 执行操作。2026 年的领域分成两种 architectural approaches:DOM-driven(解析页面、查找 elements、点击它们)和 vision-driven(截取页面 screenshot,交给 vision model,点击 pixels)。
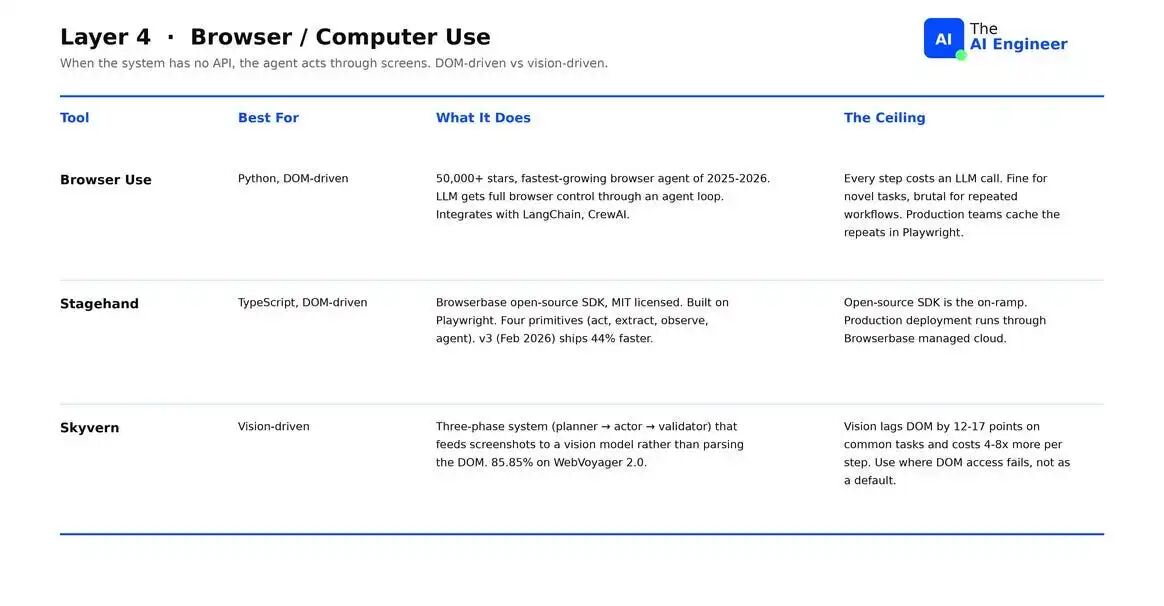
- Browser Use:Python 默认选择。GitHub stars 超过 50,000。LLM 通过 agent loop 获得对 browser 的完全控制。缺点:每一步都要消耗一次 LLM call,对 repeated workflows 非常残酷。
- Stagehand:TypeScript 的答案。Browserbase 的 open-source SDK,构建在 Playwright 之上。只在需要 reasoning 的步骤使用 AI inference,其余部分使用 scripted Playwright code。
- Skyvern:Vision-first 选项。每个 task 经过三阶段 pipeline:planner、actor、validator。在 WebVoyager 2.0 上取得 85.85%,是 DOM 不可靠的 domains 中 form-filling tasks 的最强 published score。缺点:vision-driven stacks 在 common tasks 上比 DOM-driven ones 落后 12–17 分,并且每一步成本高 4–8 倍。
2026 年的 production pattern 是两者都接入:DOM-driven 作为 primary path,当 selectors 在 canvas elements 或 anti-bot screens 上持续失败时,用 Skyvern、Anthropic Computer Use 或 OpenAI CUA 作为 escape hatch。
Layer 5: Coding Agents & Sandboxes
Coding agents 现在已经是一个独立类别。它们写 code、运行 code、在出错时 debug,并阅读 docs。这一层自带 sandboxed file system、terminal access 和 browser tool。这个类别也有自己的 benchmark:SWE-bench Verified。
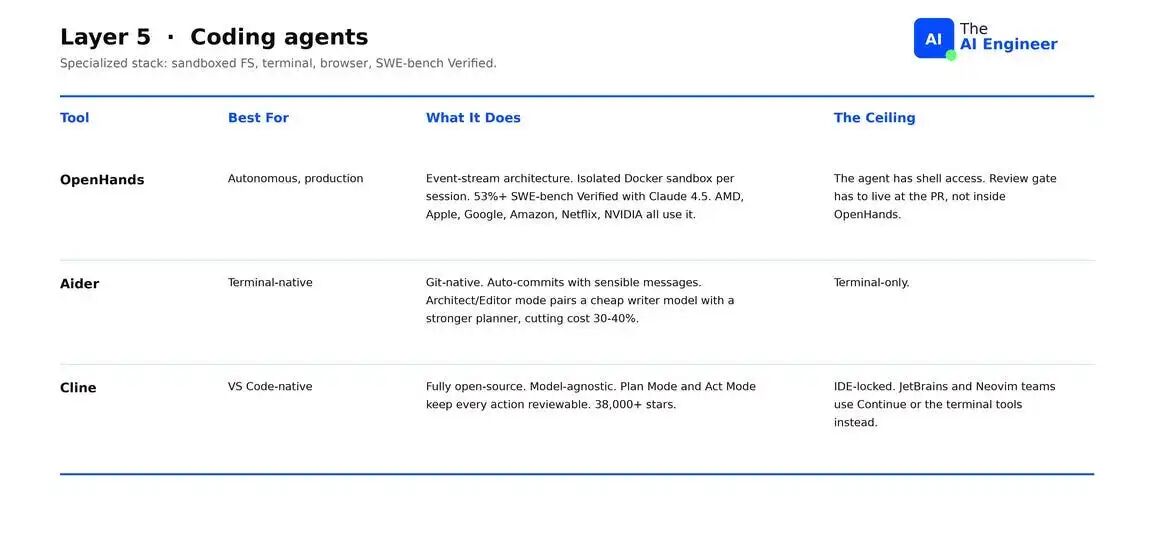
- OpenHands(formerly OpenDevin):Production-grade autonomous 选项。GitHub stars 超过 72,000。Event-stream architecture,每个 session 都运行在 isolated Docker sandbox 中。使用 Claude 4.5 在 SWE-bench Verified 上得分 53%+。
- Aider:Terminal-native 选项。天生 git-integrated,每个 change 都会变成一个 commit。Architect/Editor mode 将工作拆分给两个 models,可降低 30–40% 成本。缺点:terminal-only,没有 IDE integration。
- Cline:VS Code-native 答案。GitHub stars 超过 38,000。Plan Mode 和 Act Mode 将 intent 与 execution 分离,每个 action 在触碰 codebase 之前都可 review。缺点:IDE-locked。
2026 年,大多数运行 production coding agents 的团队会同时运行两个:一个 commercial(Claude Code、Codex)用于 hard tasks,一个 open-source 用于 flexibility 和 outages。
Layer 6: Evals & Observability
Evals & observability layer 会记录 agent 在 production 中做了什么,并在 shipping 前测试它能做什么。Tracing 捕获每一次 LLM call、tool invocation 和 cost。Evals 是 reproducible test suites。2026 年,production-grade agent teams 会在第一天就把两者接入。

- Langfuse:Open-source observability 默认选择。Open-core,原生集成 LangGraph、CrewAI、OpenAI Agents SDK 和 Mastra。缺点:managed retention、SSO 和 advanced eval features 运行在 SaaS plan 上。
- Arize Phoenix:OpenTelemetry-native alternative。Traces 会流入你 stack 中其他部分已经使用的 Grafana、Datadog 或 Honeycomb dashboards。缺点:不提供 opinionated agent-specific defaults。
- Inspect AI:UK AI Security Institute 的 open-source eval framework。用于 safety evals 和 capability benchmarking。缺点:用于 offline evaluation,需配合 Langfuse 或 Phoenix 使用。
🏗️ Engineering Lesson: 在 Day 1、第一个 user 之前就接入 tracing。没有这些 records,debug production failure 就只能猜是哪一个 prompt version、哪一个 user input,以及哪一串 tool sequence 造成了问题。
Layer 7: Models & Inference
Agent 的每一步至少是一次 inference call。运行这些 calls 的 engine 决定了其他一切的成本下限。
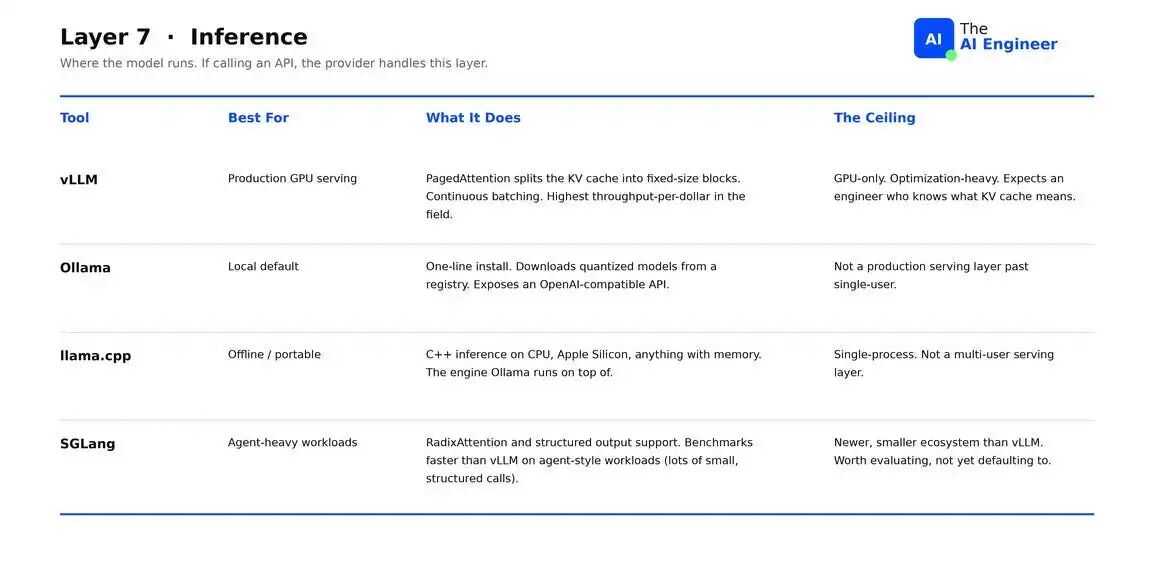
- vLLM:Open-weight models 的 production serving 默认选择。核心创新是 PagedAttention,结合 continuous batching,实现该领域最高的 throughput-per-dollar。缺点:GPU-only、optimization-heavy。
- Ollama:Local 默认选择。一行 install,从 registry 下载 quantized models。缺点:不是超过 single user 后的 production serving layer。
- llama.cpp:Ollama 底层运行的 engine。Pure C++,无 GPU dependency,可在 CPU、Apple Silicon 等设备上运行。缺点:CPU throughput 明显低于 GPU serving。
- SGLang:更新的 challenger。缓存 shared prefix computation,并在 inference engine 内部强制执行 JSON schema。在 agent workloads 上 benchmarks 比 vLLM 更快。缺点:community 更小。
这七层并不会自然 compose
看到 seven-layer diagram 时,本能反应是认为这些 layers 会纵向 compose。2026 年,大多数 agent rewrites 都可以追溯到团队基于这个假设进行构建。没有任何 ecosystem 在全部七层都是 best-in-class。
这四个 constraints 很少指向同一个 winner。Latency-first stacks 会偏向 Mem0 和 vLLM。Audit-first stacks 会偏向 LangGraph 和 Langfuse。Model portability 会让你远离 vendor SDKs。Language stack 会把你推向 Mastra 或 Pydantic AI。试图用一个 ecosystem 同时满足四者,意味着你在每一层都选择 average tool,而不是每一层最好的 tool。
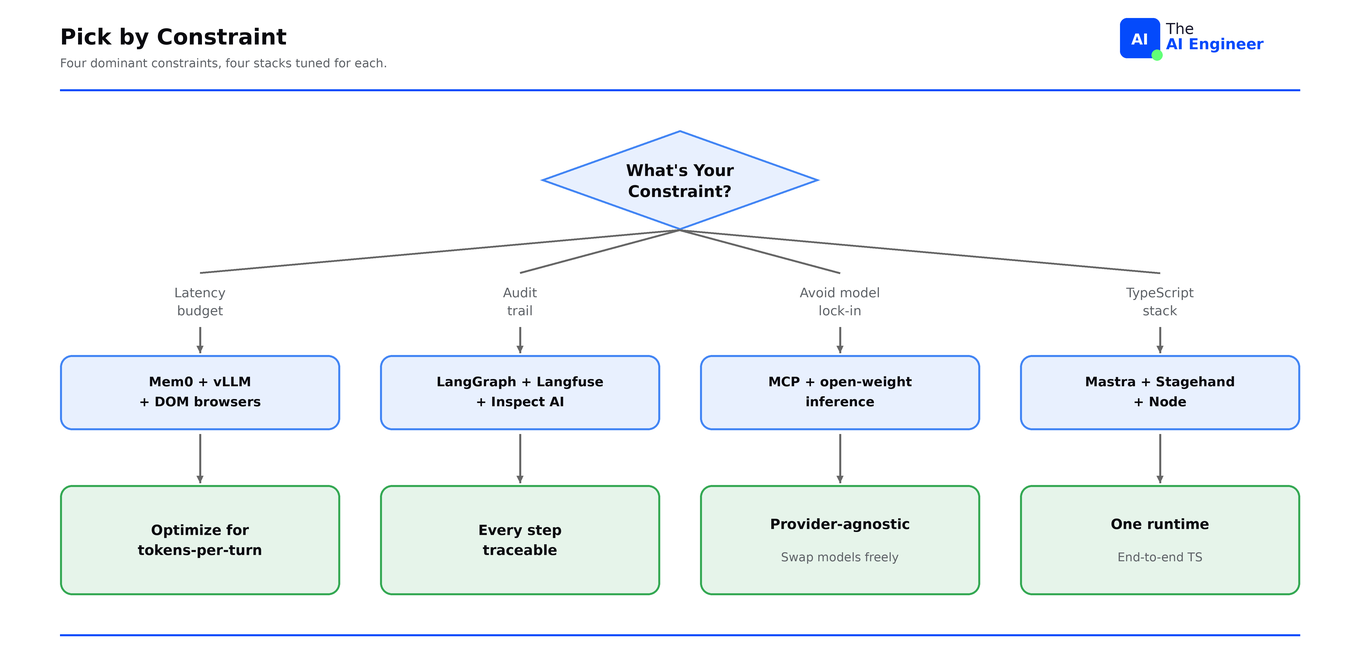
换个视角:一个 agent 的 toolkit 是七个小赌注,每个赌注都有一个 single dominant constraint,并且每个都独立做出。2026 年能够交付 reliable agents 的团队,是那些在每一层选择最佳 tool,并接受「集成 seams 本来就是工作的一部分」的团队。
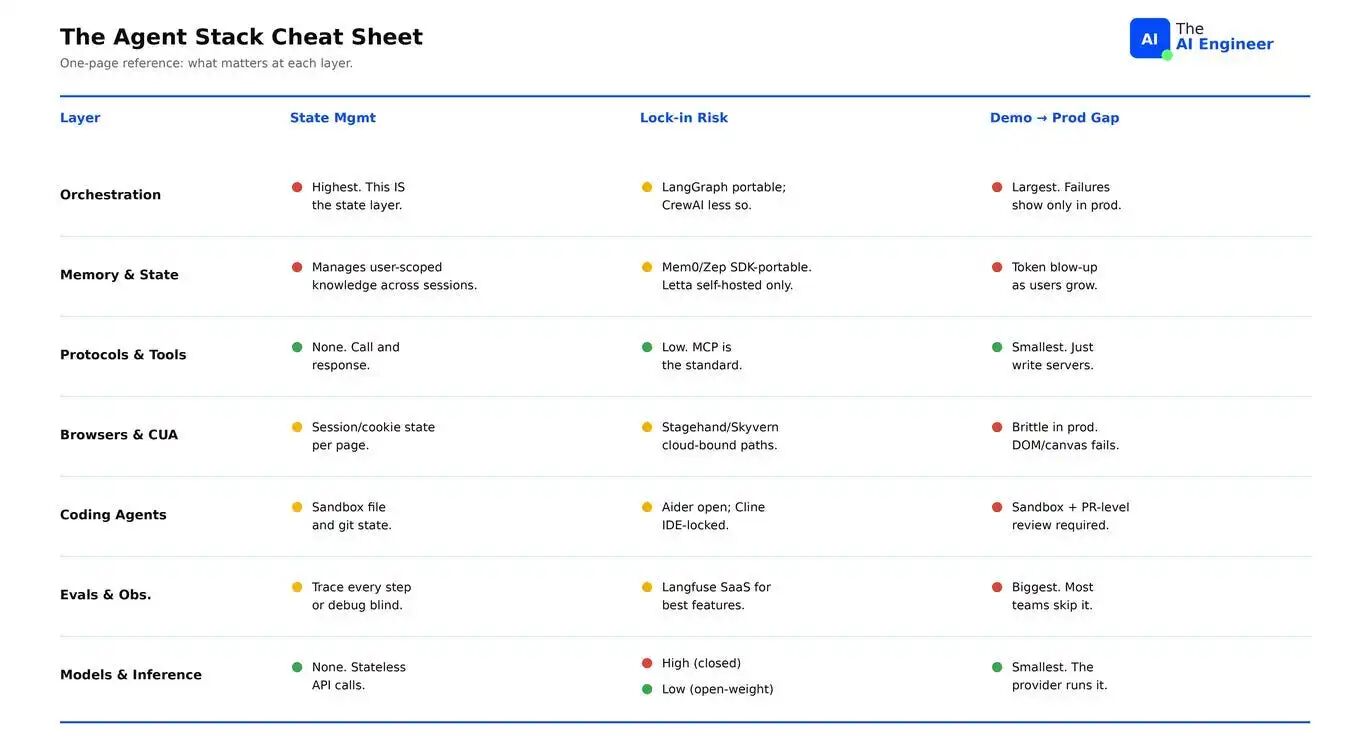
Agent Stack Cheat Sheet
在替换 production agent 的任何 layer 之前,先检查这张表。State column 告诉你需要迁移多少东西。Lock-in column 告诉你如果切换会放弃什么。Demo-to-prod column 告诉你这次替换实际需要多长时间。