在 Token 大饥荒时代,各家 Code Plan 订阅要么抢不到,要么限流,再不就是像 Anthropic 这样动不动就封号。本文测试本地 Coding Agent 能否真正干活——结论:可以,而且比预期好很多。使用的组合是 LM Studio + Pi Agent + Gemma 4 26B A4B (Q4_K_M)。
为什么选这个组合
LM Studio:本地推理服务器
LM Studio 把模型下载、量化格式管理、OpenAI 兼容 API 这几件事都做了,界面干净。你也可以用 Ollama 或 llama.cpp 的 llama-server,三个都对外暴露 OpenAI 兼容接口。Pi 不挑,随便哪个都行。
苏米注:选 LM Studio 是因为 GPU offload 配置界面直观,调参方便。
Gemma 4 26B A4B:MoE 架构开源模型
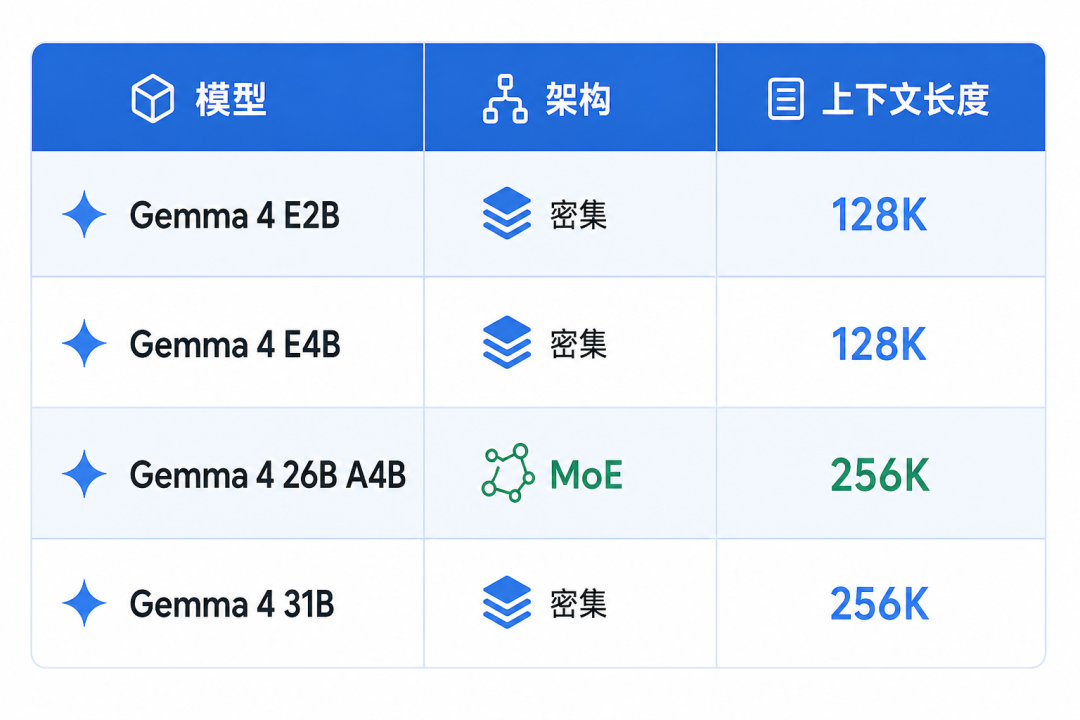
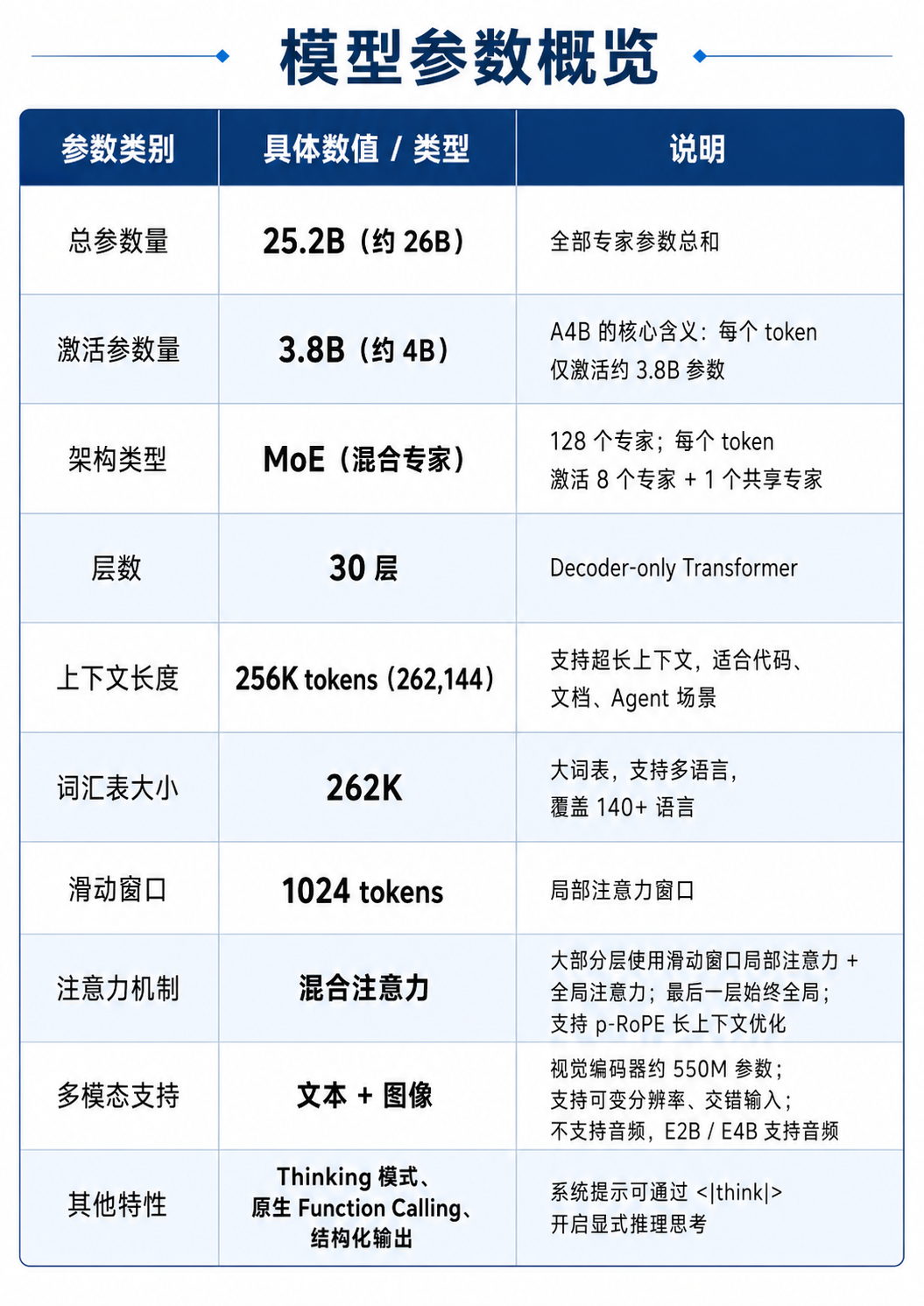
Google 最新开源模型家族的 MoE 版本。26B 总参数,但每个 token 只激活 4B。架构好处是推理速度接近小模型,但效果明显优于同等激活参数的密集模型。更关键的是原生支持 function calling、系统提示和 thinking 模式——这几个能力对 coding agent 是刚需。
Pi Agent:极简终端 Coding Harness
Pi 的核心设计理念是小:给模型的工具只有四个(read、write、edit、bash),系统提示不复杂。对于本地模型而言足够精简——因为本地模型的上下文窗口和推理速度都是有限资源,不能像调云端 API 一样挥霍。
第一步:安装 LM Studio
从 lmstudio.ai 下载对应平台安装包,支持 macOS、Windows、Linux。装完之后不需要额外配置,先开着备用。
第二步:下载 Gemma 4 模型
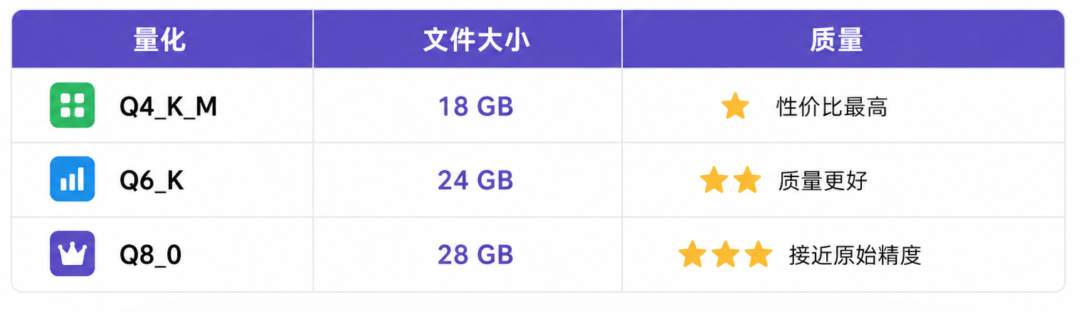
打开 LM Studio,搜索 gemma-4-26b-a4b,下载量化版本的 GGUF 文件。4090 可以上 26B A4B。
技术要点:虽然标称 26B,但 MoE 架构每次只激活 4B,实际推理速度快得多,效果远超同等激活参数的小模型。A4B 支持文本、图片理解、function calling、thinking 模式。
18 GB 的 Q4_K_M,加上上下文显存开销,24 GB 显存是舒适起步线。Mac 用户可以找 MLX 格式版本——针对 Apple Silicon 原生优化,在 M 系列芯片上通常比 GGUF 快。
第三步:启动本地服务器
模型下载完成后:
- 切到 LM Studio 的 Developer 标签页
- 选择刚才下载的 Gemma 4 模型
- 点击 Start Server
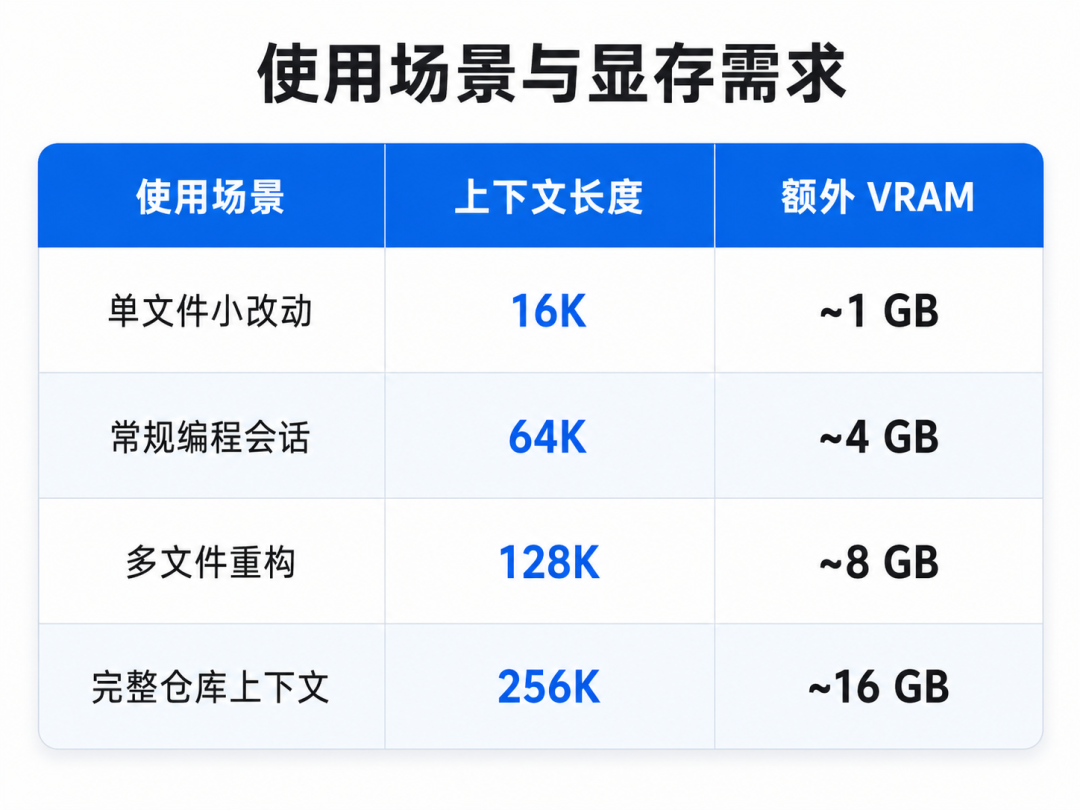
服务默认跑在 http://localhost:1234,对外暴露 OpenAI 兼容 API。
验证是否正常运行:
curl http://localhost:1234/v1/models能返回模型列表就说明服务起来了。
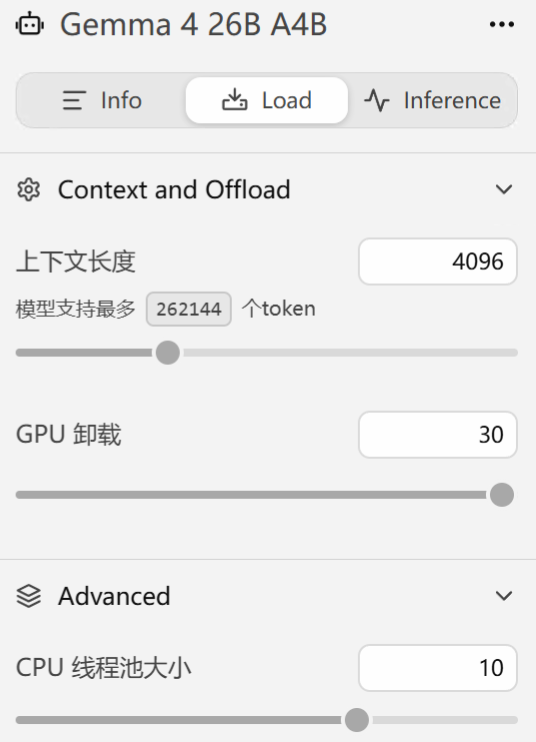
第四步:配置上下文长度和 GPU Offload
这一步很多教程跳过,但实际上对体验影响很大。
在 Developer 标签页的 Model Settings 里可以调两个关键参数:
上下文长度
Gemma 4 26B A4B 最大支持 256K 上下文,但跑 coding agent 不需要全开。上下文越长,额外占用 VRAM 越多。推荐从 128K 开始——coding agent 工作过程中会积累大量上下文,文件内容、工具输出、对话历史都往里塞。
踩坑记录:如果跑到一半上下文满了被截断比较麻烦。Pi 有几个管理上下文的命令:
- /compact:把旧消息压缩成摘要,释放上下文空间
- /new:开新会话
- /tree:浏览会话历史,跳回任意节点
- /fork:从某条消息创建分支会话
GPU Offload
控制有多少层加载到 GPU,剩余放在系统内存用 CPU 跑。全部放 GPU 最快,但 VRAM 不够会 OOM。LM Studio 可以做 GPU+CPU 混合推理,速度慢一些但能跑起来。
技术要点:显存紧张时,优先降低上下文长度,而不是减少 GPU offload 层数。
第五步:安装 Pi

Pi 通过 npm 安装:
npm install -g @mariozechner/pi-coding-agent装完直接运行 pi 就能进入交互界面。
第六步:配置本地模型
编辑文件 ~/.pi/agent/models.json:
{
"providers": {
"lmstudio": {
"baseUrl": "http://localhost:1234/v1",
"api": "openai-completions",
"apiKey": "lm-studio",
"models": [
{
"id": "google/gemma-4-26b-a4b",
"input": ["text", "image"]
}
]
}
}
}注意事项:id 字段要和 LM Studio 服务端标签页里显示的模型名称完全一致,不然 Pi 找不到。
配置完启动 Pi,用 /model 命令切换到刚才配置的本地模型。至此,整个 coding agent 就跑在你自己机器上了。
第七步:Skills 扩展
Pi 支持通过 Skills 扩展能力——本质是 Markdown 文件,写指令告诉 agent 如何完成某类特定任务。和在 Claude Code 上用的 Skills 机制是同一个思路(Agent Skills 标准)。
通过 git 安装社区 Skills:
# 全局安装,所有项目都能用
git clone https://github.com/badlogic/pi-skills ~/.pi/agent/skills/pi-skills
# 或者只在当前项目生效
git clone https://github.com/badlogic/pi-skills .pi/skills/pi-skills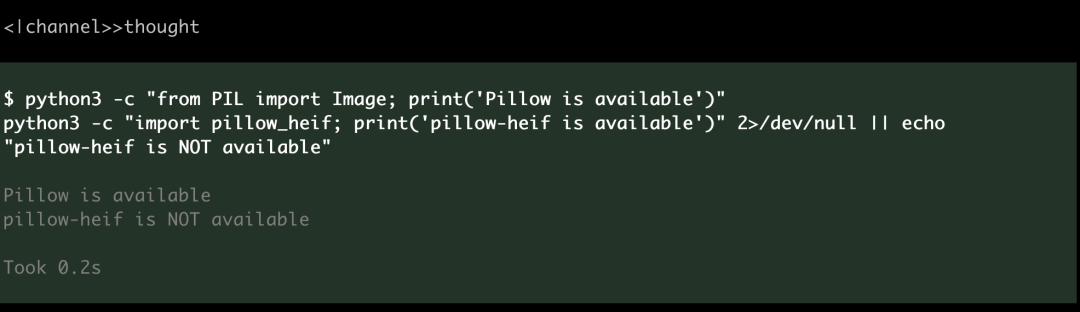
会话中用 /skill:name 手动调用指定 skill,也可以让 agent 自己判断需不需要用。
实际使用感受
Gemma 4 26B A4B 的 Function Calling 稳
之前用过一些本地模型做 agent,工具调用经常出格式错误或乱调用。Gemma 4 这一代明显改善,跑了几个中等复杂度任务基本没出现工具调用失败。
上下文管理是真正瓶颈
128K 上下文跑稍微复杂的任务不难消耗掉,特别是文件内容多的时候。Pi 的 /compact 有用但会损失细节。建议任务开始前规划好范围,不要让 agent 漫无目的地读大量文件。
本地跑的最大优势不只是省钱
没有网络延迟,响应速度稳定,没有 API 限流问题。跑批量任务或长时间 agent loop 的时候体验明显更流畅。
实战案例:批量重命名工具

让这套本地 agent 从零写一个命令行工具——扫描指定目录下图片文件,按拍摄日期自动重命名,格式是 YYYY-MM-DD_序号.扩展名。
需求:
- 读取指定目录下的 jpg/png/heic 文件
- 从 EXIF 数据提取拍摄日期
- 没有 EXIF 的用文件修改时间
- 重命名格式:YYYY-MM-DD_001.jpg,同一天的按序号排
- 支持 --dry-run 参数,只打印结果不实际重命名
- 遇到冲突文件名要提示,不要静默覆盖

Pi 拿到任务后没有直接开始写代码,先调用 bash 工具检查环境。发现 Pillow 已装,piexif 没有——运行 pip3 install piexif,确认成功后才开始写代码。
苏米注:不是所有本地模型跑 agent 任务都会先检查环境,Gemma 4 这里表现合理,没有假设依赖都存在就直接开写。
创建文件 rename_photos.py,写完主动调用 bash 跑冒烟测试。第一次跑出报错:HEIC 格式处理有问题,Pillow 默认不支持 HEIC。它自己读了报错信息,判断需要 pillow-heif 插件,装完修改代码再跑一次,通过了。
整个过程没有中途问"要不要继续",也没有在第一次报错后停下来等指令。自己完成了「写代码→测试→报错→定位问题→修复→再测试」循环。
任务统计:
- 从发出 prompt 到生成可用代码:约 4 分钟
- Agent 总共调用 12 次工具(bash 8 次,write 2 次,read 2 次)
- 中间经历三轮自动 compact 上下文
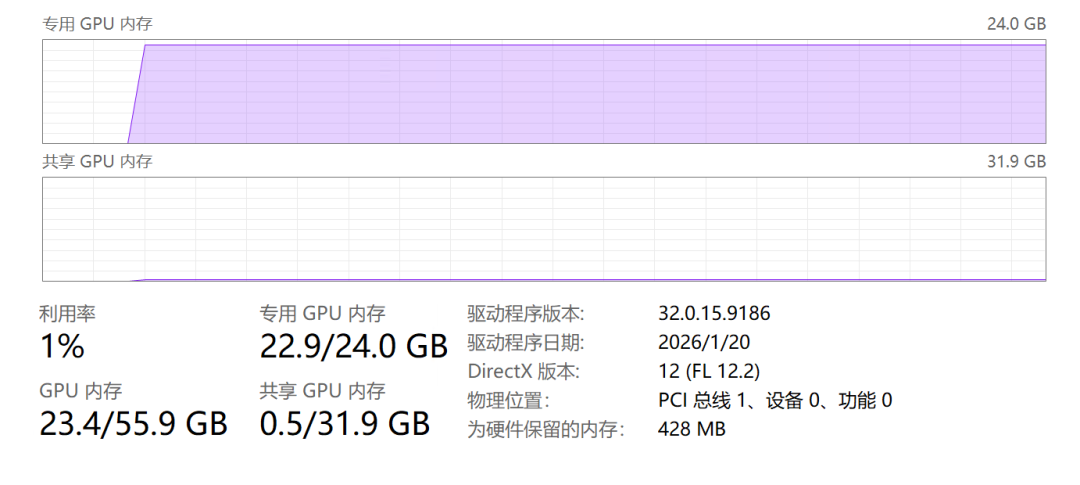
- 显存占用稳定在 22 GB 左右
这个速度和云端 API 没法比,但对于这类任务完全够用。Coding agent 大部分时间其实在等工具执行结果,纯推理时间占比没有想象中高。
适用人群:有 24GB 显存或 M 系列 Mac 的用户,这套组合值得动手试一试。比想象中容易,效果也比想象中实用。